 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Approach to Multiple Comparison Benchmark Evaluations that is Stable Under Manipulation of the Comparate Set
May 19, 2023



The measurement of progress using benchmarks evaluations is ubiquitous in computer science and machine learning. However, common approaches to analyzing and presenting the results of benchmark comparisons of multiple algorithms over multiple datasets, such as the critical difference diagram introduced by Dem\v{s}ar (2006), have important shortcomings and, we show, are open to both inadvertent and intentional manipulation. To address these issues, we propose a new approach to presenting the results of benchmark comparisons, the Multiple Comparison Matrix (MCM), that prioritizes pairwise comparisons and precludes the means of manipulating experimental results in existing approaches. MCM can be used to show the results of an all-pairs comparison, or to show the results of a comparison between one or more selected algorithms and the state of the art. MCM is implemented in Python and is publicly available.
Proximity Forest 2.0: A new effective and scalable similarity-based classifier for time series
Apr 13, 2023



Time series classification (TSC) is a challenging task due to the diversity of types of feature that may be relevant for different classification tasks, including trends, variance, frequency, magnitude, and various patterns. To address this challenge, several alternative classes of approach have been developed, including similarity-based, features and intervals, shapelets, dictionary, kernel, neural network, and hybrid approaches. While kernel, neural network, and hybrid approaches perform well overall, some specialized approaches are better suited for specific tasks. In this paper, we propose a new similarity-based classifier, Proximity Forest version 2.0 (PF 2.0), which outperforms previous state-of-the-art similarity-based classifiers across the UCR benchmark and outperforms state-of-the-art kernel, neural network, and hybrid methods on specific datasets in the benchmark that are best addressed by similarity-base methods. PF 2.0 incorporates three recent advances in time series similarity measures -- (1) computationally efficient early abandoning and pruning to speedup elastic similarity computations; (2) a new elastic similarity measure, Amerced Dynamic Time Warping (ADTW); and (3) cost function tuning. It rationalizes the set of similarity measures employed, reducing the eight base measures of the original PF to three and using the first derivative transform with all similarity measures, rather than a limited subset. We have implemented both PF 1.0 and PF 2.0 in a single C++ framework, making the PF framework more efficient.
Deep Learning for Time Series Classification and Extrinsic Regression: A Current Survey
Feb 06, 2023



Time Series Classification and Extrinsic Regression are important and challenging machine learning tasks. Deep learning has revolutionized natural language processing and computer vision and holds great promise in other fields such as time series analysis where the relevant features must often be abstracted from the raw data but are not known a priori. This paper surveys the current state of the art in the fast-moving field of deep learning for time series classification and extrinsic regression. We review different network architectures and training methods used for these tasks and discuss the challenges and opportunities when applying deep learning to time series data. We also summarize two critical applications of time series classification and extrinsic regression, human activity recognition and satellite earth observation.
Parameterizing the cost function of Dynamic Time Warping with application to time series classification
Jan 24, 2023Dynamic Time Warping (DTW) is a popular time series distance measure that aligns the points in two series with one another. These alignments support warping of the time dimension to allow for processes that unfold at differing rates. The distance is the minimum sum of costs of the resulting alignments over any allowable warping of the time dimension. The cost of an alignment of two points is a function of the difference in the values of those points. The original cost function was the absolute value of this difference. Other cost functions have been proposed. A popular alternative is the square of the difference. However, to our knowledge, this is the first investigation of both the relative impacts of using different cost functions and the potential to tune cost functions to different tasks. We do so in this paper by using a tunable cost function {\lambda}{\gamma} with parameter {\gamma}. We show that higher values of {\gamma} place greater weight on larger pairwise differences, while lower values place greater weight on smaller pairwise differences. We demonstrate that training {\gamma} significantly improves the accuracy of both the DTW nearest neighbor and Proximity Forest classifiers.
SETAR-Tree: A Novel and Accurate Tree Algorithm for Global Time Series Forecasting
Nov 16, 2022Threshold Autoregressive (TAR) models have been widely used by statisticians for non-linear time series forecasting during the past few decades, due to their simplicity and mathematical properties. On the other hand, in the forecasting community, general-purpose tree-based regression algorithms (forests, gradient-boosting) have become popular recently due to their ease of use and accuracy. In this paper, we explore the close connections between TAR models and regression trees. These enable us to use the rich methodology from the literature on TAR models to define a hierarchical TAR model as a regression tree that trains globally across series, which we call SETAR-Tree. In contrast to the general-purpose tree-based models that do not primarily focus on forecasting, and calculate averages at the leaf nodes, we introduce a new forecasting-specific tree algorithm that trains global Pooled Regression (PR) models in the leaves allowing the models to learn cross-series information and also uses some time-series-specific splitting and stopping procedures. The depth of the tree is controlled by conducting a statistical linearity test commonly employed in TAR models, as well as measuring the error reduction percentage at each node split. Thus, the proposed tree model requires minimal external hyperparameter tuning and provides competitive results under its default configuration. We also use this tree algorithm to develop a forest where the forecasts provided by a collection of diverse SETAR-Trees are combined during the forecasting process. In our evaluation on eight publicly available datasets, the proposed tree and forest models are able to achieve significantly higher accuracy than a set of state-of-the-art tree-based algorithms and forecasting benchmarks across four evaluation metrics.
Deep Learning for Time Series Anomaly Detection: A Survey
Nov 09, 2022



Time series anomaly detection has applications in a wide range of research fields and applications, including manufacturing and healthcare. The presence of anomalies can indicate novel or unexpected events, such as production faults, system defects, or heart fluttering, and is therefore of particular interest. The large size and complex patterns of time series have led researchers to develop specialised deep learning models for detecting anomalous patterns. This survey focuses on providing structured and comprehensive state-of-the-art time series anomaly detection models through the use of deep learning. It providing a taxonomy based on the factors that divide anomaly detection models into different categories. Aside from describing the basic anomaly detection technique for each category, the advantages and limitations are also discussed. Furthermore, this study includes examples of deep anomaly detection in time series across various application domains in recent years. It finally summarises open issues in research and challenges faced while adopting deep anomaly detection models.
HYDRA: Competing convolutional kernels for fast and accurate time series classification
Mar 25, 2022
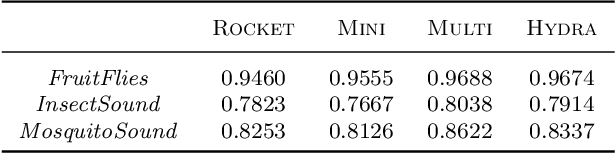
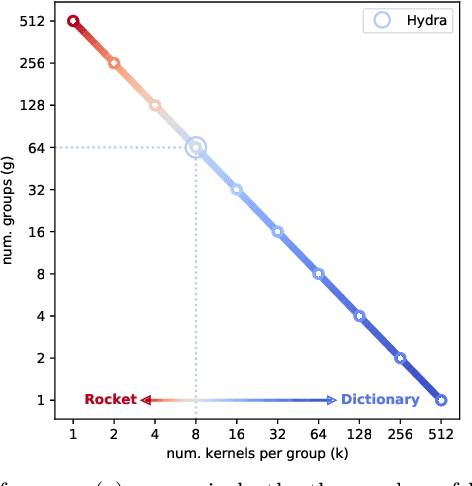
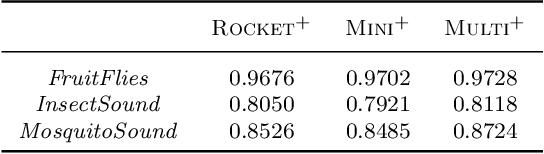
We demonstrate a simple connection between dictionary methods for time series classification, which involve extracting and counting symbolic patterns in time series, and methods based on transforming input time series using convolutional kernels, namely ROCKET and its variants. We show that by adjusting a single hyperparameter it is possible to move by degrees between models resembling dictionary methods and models resembling ROCKET. We present HYDRA, a simple, fast, and accurate dictionary method for time series classification using competing convolutional kernels, combining key aspects of both ROCKET and conventional dictionary methods. HYDRA is faster and more accurate than the most accurate existing dictionary methods, and can be combined with ROCKET and its variants to further improve the accuracy of these methods.
Estimating Divergences in High Dimensions
Dec 08, 2021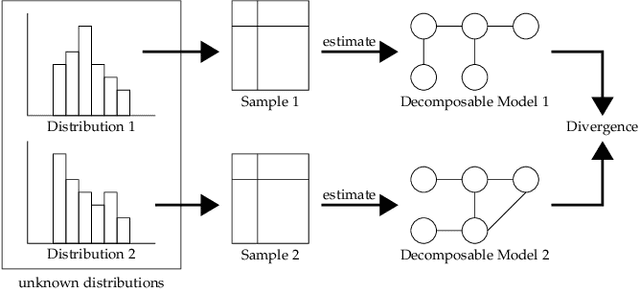

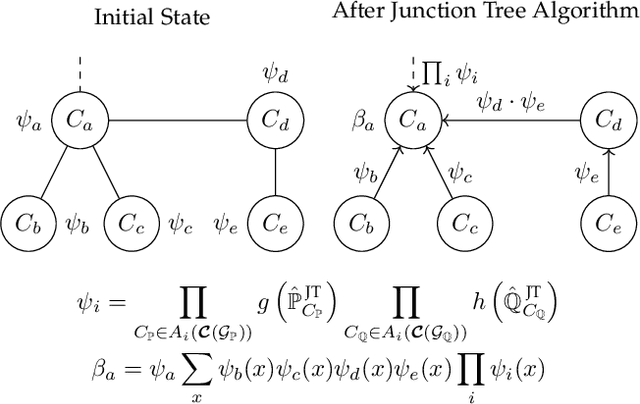
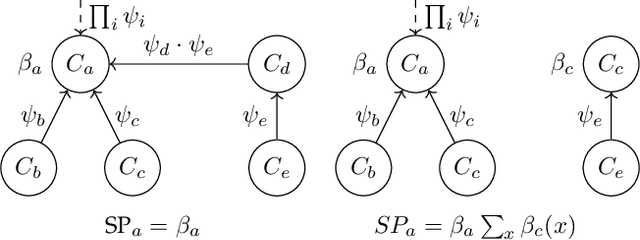
The problem of estimating the divergence between 2 high dimensional distributions with limited samples is an important problem in various fields such as machine learning. Although previous methods perform well with moderate dimensional data, their accuracy starts to degrade in situations with 100s of binary variables. Therefore, we propose the use of decomposable models for estimating divergences in high dimensional data. These allow us to factorize the estimated density of the high-dimensional distribution into a product of lower dimensional functions. We conduct formal and experimental analyses to explore the properties of using decomposable models in the context of divergence estimation. To this end, we show empirically that estimating the Kullback-Leibler divergence using decomposable models from a maximum likelihood estimator outperforms existing methods for divergence estimation in situations where dimensionality is high and useful decomposable models can be learnt from the available data.
Amercing: An Intuitive, Elegant and Effective Constraint for Dynamic Time Warping
Nov 26, 2021
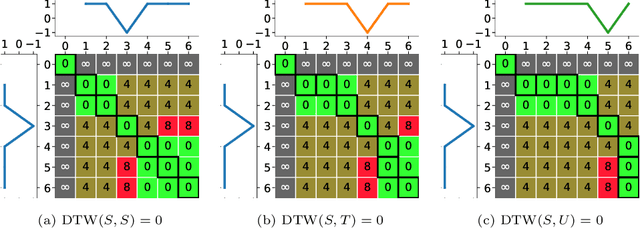
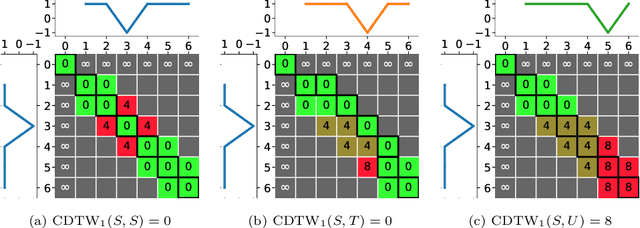
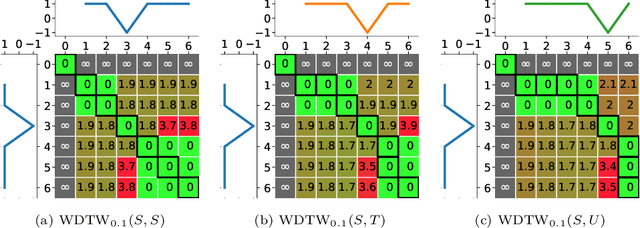
Dynamic Time Warping (DTW), and its constrained (CDTW) and weighted (WDTW) variants, are time series distances with a wide range of applications. They minimize the cost of non-linear alignments between series. CDTW and WDTW have been introduced because DTW is too permissive in its alignments. However, CDTW uses a crude step function, allowing unconstrained flexibility within the window, and none beyond it. WDTW's multiplicative weight is relative to the distances between aligned points along a warped path, rather than being a direct function of the amount of warping that is introduced. In this paper, we introduce Amerced Dynamic Time Warping (ADTW), a new, intuitive, DTW variant that penalizes the act of warping by a fixed additive cost. Like CDTW and WDTW, ADTW constrains the amount of warping. However, it avoids both abrupt discontinuities in the amount of warping allowed and the limitations of a multiplicative penalty. We formally introduce ADTW, prove some of its properties, and discuss its parameterization. We show on a simple example how it can be parameterized to achieve an intuitive outcome, and demonstrate its usefulness on a standard time series classification benchmark. We provide a demonstration application in C++.
Monash Time Series Forecasting Archive
May 14, 2021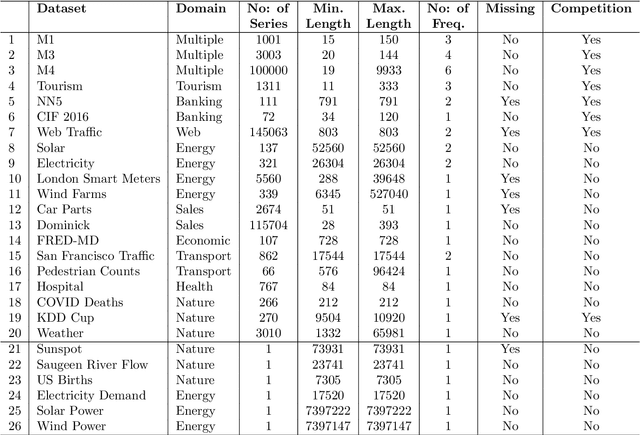


Many businesses and industries nowadays rely on large quantities of time series data making time series forecasting an important research area. Global forecasting models that are trained across sets of time series have shown a huge potential in providing accurate forecasts compared with the traditional univariate forecasting models that work on isolated series. However, there are currently no comprehensive time series archives for forecasting that contain datasets of time series from similar sources available for the research community to evaluate the performance of new global forecasting algorithms over a wide variety of datasets. In this paper, we present such a comprehensive time series forecasting archive containing 20 publicly available time series datasets from varied domains, with different characteristics in terms of frequency, series lengths, and inclusion of missing values. We also characterise the datasets, and identify similarities and differences among them, by conducting a feature analysis. Furthermore, we present the performance of a set of standard baseline forecasting methods over all datasets across eight error metrics, for the benefit of researchers using the archive to benchmark their forecasting algorithms.