 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Complete Set of Quadratic Constraints For Repeated ReLU
Jul 09, 2024This paper derives a complete set of quadratic constraints (QCs) for the repeated ReLU. The complete set of QCs is described by a collection of $2^{n_v}$ matrix copositivity conditions where $n_v$ is the dimension of the repeated ReLU. We also show that only two functions satisfy all QCs in our complete set: the repeated ReLU and a repeated "flipped" ReLU. Thus our complete set of QCs bounds the repeated ReLU as tight as possible up to the sign invariance inherent in quadratic forms. We derive a similar complete set of incremental QCs for repeated ReLU, which can potentially lead to less conservative Lipschitz bounds for ReLU networks than the standard LipSDP approach. Finally, we illustrate the use of the complete set of QCs to assess stability and performance for recurrent neural networks with ReLU activation functions. The stability/performance condition combines Lyapunov/dissipativity theory with the QCs for repeated ReLU. A numerical implementation is given and demonstrated via a simple example.
Stability and Performance Analysis of Discrete-Time ReLU Recurrent Neural Networks
May 08, 2024This paper presents sufficient conditions for the stability and $\ell_2$-gain performance of recurrent neural networks (RNNs) with ReLU activation functions. These conditions are derived by combining Lyapunov/dissipativity theory with Quadratic Constraints (QCs) satisfied by repeated ReLUs. We write a general class of QCs for repeated RELUs using known properties for the scalar ReLU. Our stability and performance condition uses these QCs along with a "lifted" representation for the ReLU RNN. We show that the positive homogeneity property satisfied by a scalar ReLU does not expand the class of QCs for the repeated ReLU. We present examples to demonstrate the stability / performance condition and study the effect of the lifting horizon.
Capabilities of Large Language Models in Control Engineering: A Benchmark Study on GPT-4, Claude 3 Opus, and Gemini 1.0 Ultra
Apr 04, 2024



In this paper, we explore the capabilities of state-of-the-art large language models (LLMs) such as GPT-4, Claude 3 Opus, and Gemini 1.0 Ultra in solving undergraduate-level control problems. Controls provides an interesting case study for LLM reasoning due to its combination of mathematical theory and engineering design. We introduce ControlBench, a benchmark dataset tailored to reflect the breadth, depth, and complexity of classical control design. We use this dataset to study and evaluate the problem-solving abilities of these LLMs in the context of control engineering. We present evaluations conducted by a panel of human experts, providing insights into the accuracy, reasoning, and explanatory prowess of LLMs in control engineering. Our analysis reveals the strengths and limitations of each LLM in the context of classical control, and our results imply that Claude 3 Opus has become the state-of-the-art LLM for solving undergraduate control problems. Our study serves as an initial step towards the broader goal of employing artificial general intelligence in control engineering.
Model-Free $μ$-Synthesis: A Nonsmooth Optimization Perspective
Feb 18, 2024



In this paper, we revisit model-free policy search on an important robust control benchmark, namely $\mu$-synthesis. In the general output-feedback setting, there do not exist convex formulations for this problem, and hence global optimality guarantees are not expected. Apkarian (2011) presented a nonconvex nonsmooth policy optimization approach for this problem, and achieved state-of-the-art design results via using subgradient-based policy search algorithms which generate update directions in a model-based manner. Despite the lack of convexity and global optimality guarantees, these subgradient-based policy search methods have led to impressive numerical results in practice. Built upon such a policy optimization persepctive, our paper extends these subgradient-based search methods to a model-free setting. Specifically, we examine the effectiveness of two model-free policy optimization strategies: the model-free non-derivative sampling method and the zeroth-order policy search with uniform smoothing. We performed an extensive numerical study to demonstrate that both methods consistently replicate the design outcomes achieved by their model-based counterparts. Additionally, we provide some theoretical justifications showing that convergence guarantees to stationary points can be established for our model-free $\mu$-synthesis under some assumptions related to the coerciveness of the cost function. Overall, our results demonstrate that derivative-free policy optimization offers a competitive and viable approach for solving general output-feedback $\mu$-synthesis problems in the model-free setting.
Learning Certifiably Robust Controllers Using Fragile Perception
Sep 22, 2022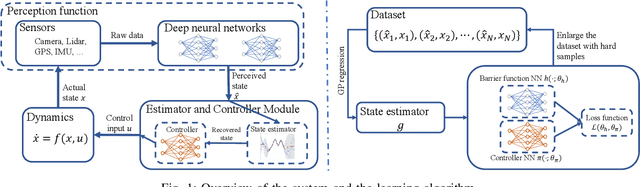
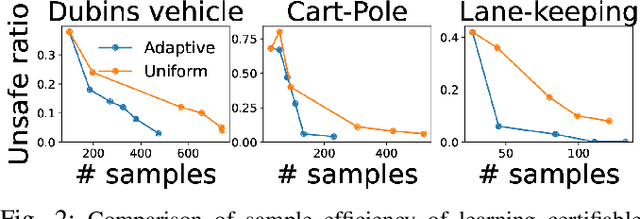
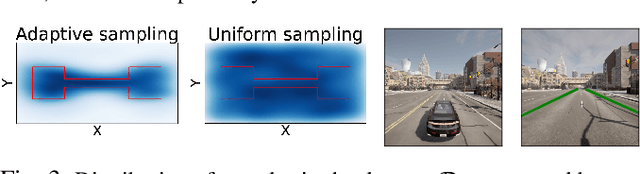
Advances in computer vision and machine learning enable robots to perceive their surroundings in powerful new ways, but these perception modules have well-known fragilities. We consider the problem of synthesizing a safe controller that is robust despite perception errors. The proposed method constructs a state estimator based on Gaussian processes with input-dependent noises. This estimator computes a high-confidence set for the actual state given a perceived state. Then, a robust neural network controller is synthesized that can provably handle the state uncertainty. Furthermore, an adaptive sampling algorithm is proposed to jointly improve the estimator and controller. Simulation experiments, including a realistic vision-based lane-keeping example in CARLA, illustrate the promise of the proposed approach in synthesizing robust controllers with deep-learning-based perception.
Revisiting PGD Attacks for Stability Analysis of Large-Scale Nonlinear Systems and Perception-Based Control
Jan 03, 2022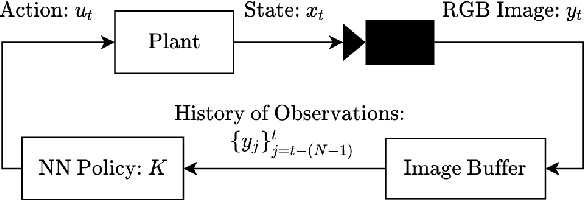
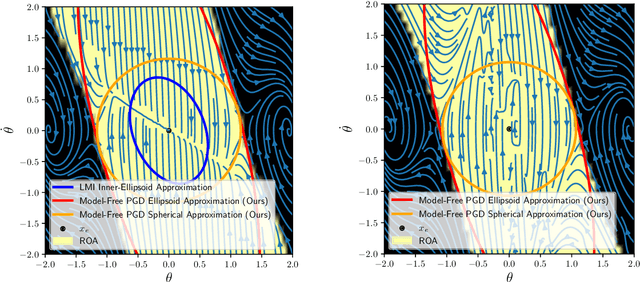
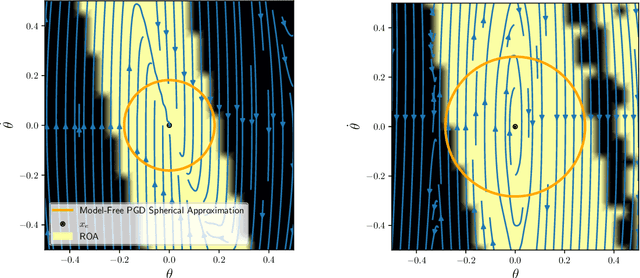
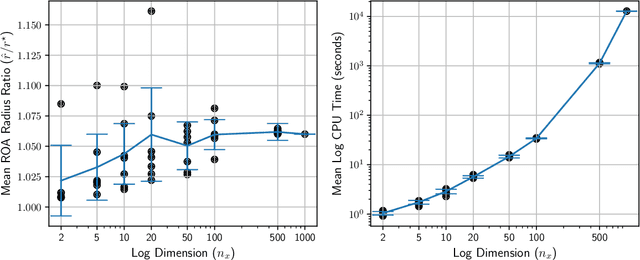
Many existing region-of-attraction (ROA) analysis tools find difficulty in addressing feedback systems with large-scale neural network (NN) policies and/or high-dimensional sensing modalities such as cameras. In this paper, we tailor the projected gradient descent (PGD) attack method developed in the adversarial learning community as a general-purpose ROA analysis tool for large-scale nonlinear systems and end-to-end perception-based control. We show that the ROA analysis can be approximated as a constrained maximization problem whose goal is to find the worst-case initial condition which shifts the terminal state the most. Then we present two PGD-based iterative methods which can be used to solve the resultant constrained maximization problem. Our analysis is not based on Lyapunov theory, and hence requires minimum information of the problem structures. In the model-based setting, we show that the PGD updates can be efficiently performed using back-propagation. In the model-free setting (which is more relevant to ROA analysis of perception-based control), we propose a finite-difference PGD estimate which is general and only requires a black-box simulator for generating the trajectories of the closed-loop system given any initial state. We demonstrate the scalability and generality of our analysis tool on several numerical examples with large-scale NN policies and high-dimensional image observations. We believe that our proposed analysis serves as a meaningful initial step toward further understanding of closed-loop stability of large-scale nonlinear systems and perception-based control.
Model-Free $μ$ Synthesis via Adversarial Reinforcement Learning
Nov 30, 2021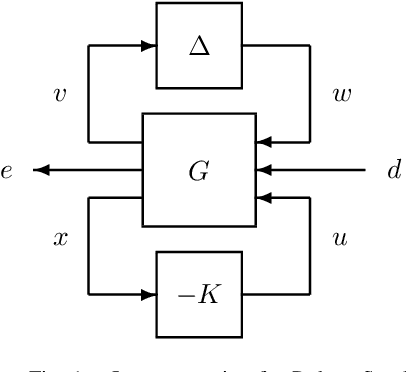
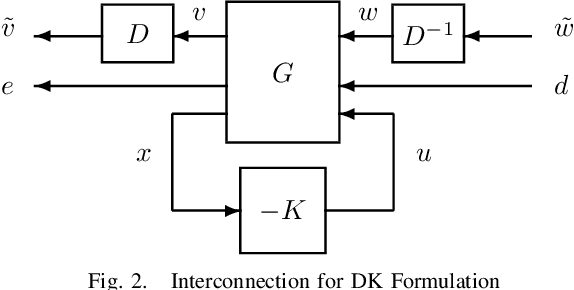
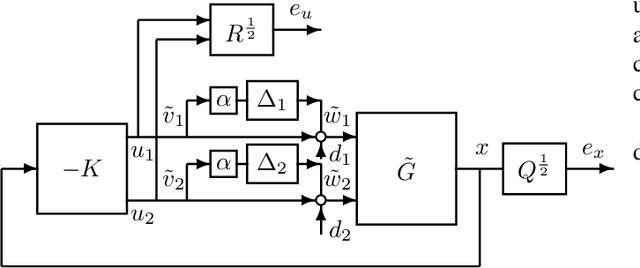
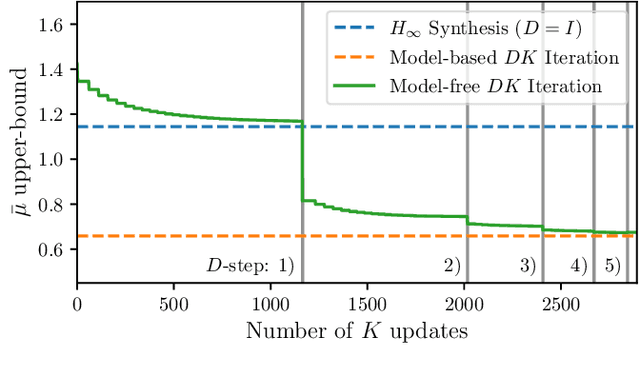
Motivated by the recent empirical success of policy-based reinforcement learning (RL), there has been a research trend studying the performance of policy-based RL methods on standard control benchmark problems. In this paper, we examine the effectiveness of policy-based RL methods on an important robust control problem, namely $\mu$ synthesis. We build a connection between robust adversarial RL and $\mu$ synthesis, and develop a model-free version of the well-known $DK$-iteration for solving state-feedback $\mu$ synthesis with static $D$-scaling. In the proposed algorithm, the $K$ step mimics the classical central path algorithm via incorporating a recently-developed double-loop adversarial RL method as a subroutine, and the $D$ step is based on model-free finite difference approximation. Extensive numerical study is also presented to demonstrate the utility of our proposed model-free algorithm. Our study sheds new light on the connections between adversarial RL and robust control.
Policy Optimization for Markovian Jump Linear Quadratic Control: Gradient-Based Methods and Global Convergence
Nov 24, 2020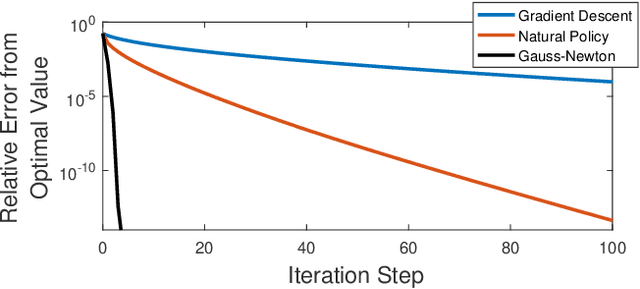
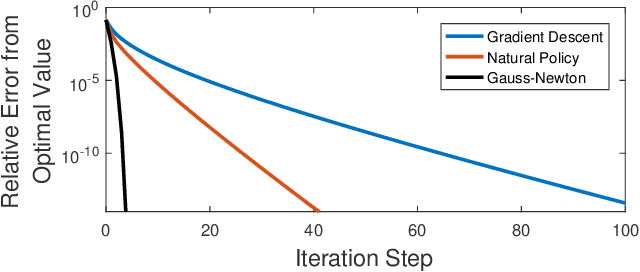
Recently, policy optimization for control purposes has received renewed attention due to the increasing interest in reinforcement learning. In this paper, we investigate the global convergence of gradient-based policy optimization methods for quadratic optimal control of discrete-time Markovian jump linear systems (MJLS). First, we study the optimization landscape of direct policy optimization for MJLS, with static state feedback controllers and quadratic performance costs. Despite the non-convexity of the resultant problem, we are still able to identify several useful properties such as coercivity, gradient dominance, and almost smoothness. Based on these properties, we show global convergence of three types of policy optimization methods: the gradient descent method; the Gauss-Newton method; and the natural policy gradient method. We prove that all three methods converge to the optimal state feedback controller for MJLS at a linear rate if initialized at a controller which is mean-square stabilizing. Some numerical examples are presented to support the theory. This work brings new insights for understanding the performance of policy gradient methods on the Markovian jump linear quadratic control problem.
Policy Learning of MDPs with Mixed Continuous/Discrete Variables: A Case Study on Model-Free Control of Markovian Jump Systems
Jun 04, 2020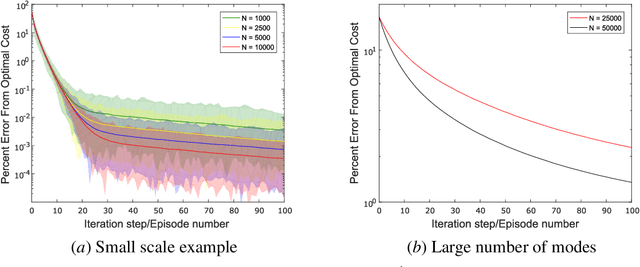
Markovian jump linear systems (MJLS) are an important class of dynamical systems that arise in many control applications. In this paper, we introduce the problem of controlling unknown (discrete-time) MJLS as a new benchmark for policy-based reinforcement learning of Markov decision processes (MDPs) with mixed continuous/discrete state variables. Compared with the traditional linear quadratic regulator (LQR), our proposed problem leads to a special hybrid MDP (with mixed continuous and discrete variables) and poses significant new challenges due to the appearance of an underlying Markov jump parameter governing the mode of the system dynamics. Specifically, the state of a MJLS does not form a Markov chain and hence one cannot study the MJLS control problem as a MDP with solely continuous state variable. However, one can augment the state and the jump parameter to obtain a MDP with a mixed continuous/discrete state space. We discuss how control theory sheds light on the policy parameterization of such hybrid MDPs. Then we modify the widely used natural policy gradient method to directly learn the optimal state feedback control policy for MJLS without identifying either the system dynamics or the transition probability of the switching parameter. We implement the (data-driven) natural policy gradient method on different MJLS examples. Our simulation results suggest that the natural gradient method can efficiently learn the optimal controller for MJLS with unknown dynamics.
Convergence Guarantees of Policy Optimization Methods for Markovian Jump Linear Systems
Feb 10, 2020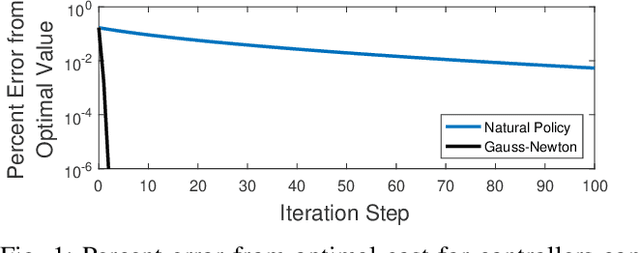
Recently, policy optimization for control purposes has received renewed attention due to the increasing interest in reinforcement learning. In this paper, we investigate the convergence of policy optimization for quadratic control of Markovian jump linear systems (MJLS). First, we study the optimization landscape of direct policy optimization for MJLS, and, in particular, show that despite the non-convexity of the resultant problem the unique stationary point is the global optimal solution. Next, we prove that the Gauss-Newton method and the natural policy gradient method converge to the optimal state feedback controller for MJLS at a linear rate if initialized at a controller which stabilizes the closed-loop dynamics in the mean square sense. We propose a novel Lyapunov argument to fix a key stability issue in the convergence proof. Finally, we present a numerical example to support our theory. Our work brings new insights for understanding the performance of policy learning methods on controlling unknown MJLS.