 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuarkAudio Technical Report
Dec 23, 2025Many existing audio processing and generation models rely on task-specific architectures, resulting in fragmented development efforts and limited extensibility. It is therefore promising to design a unified framework capable of handling multiple tasks, while providing robust instruction and audio understanding and high-quality audio generation. This requires a compatible paradigm design, a powerful backbone, and a high-fidelity audio reconstruction module. To meet these requirements, this technical report introduces QuarkAudio, a decoder-only autoregressive (AR) LM-based generative framework that unifies multiple tasks. The framework includes a unified discrete audio tokenizer, H-Codec, which incorporates self-supervised learning (SSL) representations into the tokenization and reconstruction process. We further propose several improvements to H-Codec, such as a dynamic frame-rate mechanism and extending the audio sampling rate to 48 kHz. QuarkAudio unifies tasks by using task-specific conditional information as the conditioning sequence of the decoder-only LM, and predicting discrete target audio tokens in an AR manner. The framework supports a wide range of audio processing and generation tasks, including speech restoration (SR), target speaker extraction (TSE), speech separation (SS), voice conversion (VC), and language-queried audio source separation (LASS). In addition, we extend downstream tasks to universal free-form audio editing guided by natural language instructions (including speech semantic editing and audio event editing). Experimental results show that H-Codec achieves high-quality audio reconstruction with a low frame rate, improving both the efficiency and performance of downstream audio generation, and that QuarkAudio delivers competitive or comparable performance to state-of-the-art task-specific or multi-task systems across multiple tasks.
Adversarial Sub-sequence for Text Generation
May 30, 2019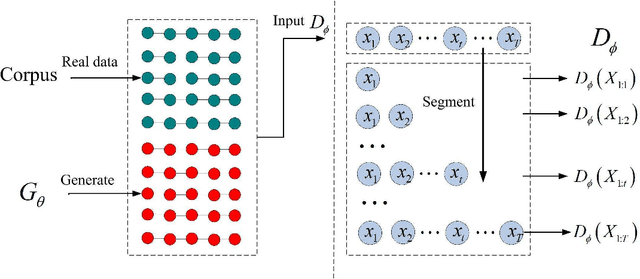

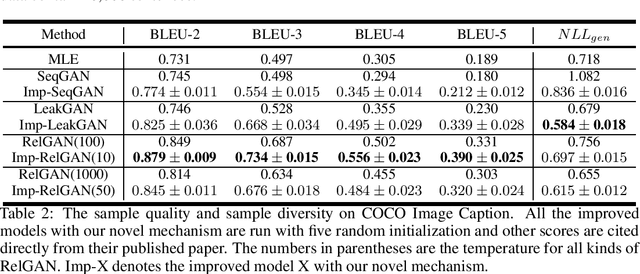
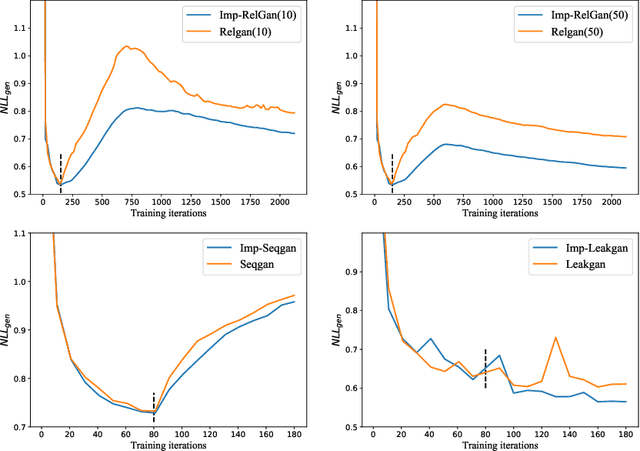
Generative adversarial nets (GAN) has been successfully introduced for generating text to alleviate the exposure bias. However, discriminators in these models only evaluate the entire sequence, which causes feedback sparsity and mode collapse. To tackle these problems, we propose a novel mechanism. It first segments the entire sequence into several sub-sequences. Then these sub-sequences, together with the entire sequence, are evaluated individually by the discriminator. At last these feedback signals are all used to guide the learning of GAN. This mechanism learns the generation of both the entire sequence and the sub-sequences simultaneously. Learning to generate sub-sequences is easy and is helpful in generating an entire sequence. It is easy to improve the existing GAN-based models with this mechanism. We rebuild three previous well-designed models with our mechanism, and the experimental results on benchmark data show these models are improved significantly, the best one outperforms the state-of-the-art model.\footnote[1]{All code and data are available at https://github.com/liyzcj/seggan.git