 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Neural-Symbolic Concept Reasoning
Apr 27, 2023



Deep learning methods are highly accurate, yet their opaque decision process prevents them from earning full human trust. Concept-based models aim to address this issue by learning tasks based on a set of human-understandable concepts. However, state-of-the-art concept-based models rely on high-dimensional concept embedding representations which lack a clear semantic meaning, thus questioning the interpretability of their decision process. To overcome this limitation, we propose the Deep Concept Reasoner (DCR), the first interpretable concept-based model that builds upon concept embeddings. In DCR, neural networks do not make task predictions directly, but they build syntactic rule structures using concept embeddings. DCR then executes these rules on meaningful concept truth degrees to provide a final interpretable and semantically-consistent prediction in a differentiable manner. Our experiments show that DCR: (i) improves up to +25% w.r.t. state-of-the-art interpretable concept-based models on challenging benchmarks (ii) discovers meaningful logic rules matching known ground truths even in the absence of concept supervision during training, and (iii), facilitates the generation of counterfactual examples providing the learnt rules as guidance.
Extending Logic Explained Networks to Text Classification
Nov 04, 2022



Recently, Logic Explained Networks (LENs) have been proposed as explainable-by-design neural models providing logic explanations for their predictions. However, these models have only been applied to vision and tabular data, and they mostly favour the generation of global explanations, while local ones tend to be noisy and verbose. For these reasons, we propose LENp, improving local explanations by perturbing input words, and we test it on text classification. Our results show that (i) LENp provides better local explanations than LIME in terms of sensitivity and faithfulness, and (ii) logic explanations are more useful and user-friendly than feature scoring provided by LIME as attested by a human survey.
Concept Embedding Models
Sep 19, 2022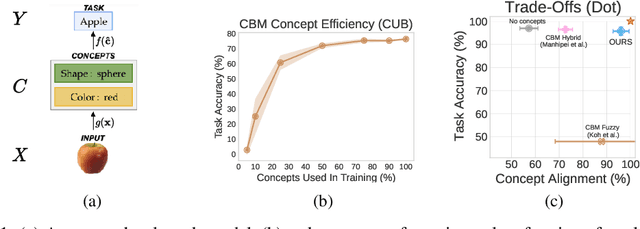

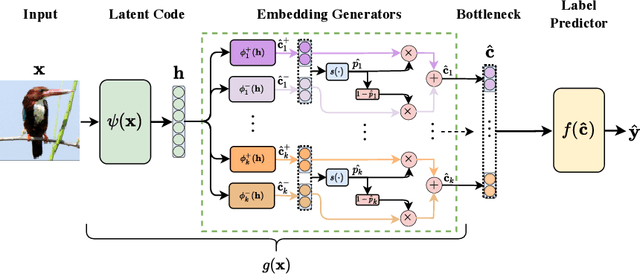

Deploying AI-powered systems requires trustworthy models supporting effective human interactions, going beyond raw prediction accuracy. Concept bottleneck models promote trustworthiness by conditioning classification tasks on an intermediate level of human-like concepts. This enables human interventions which can correct mispredicted concepts to improve the model's performance. However, existing concept bottleneck models are unable to find optimal compromises between high task accuracy, robust concept-based explanations, and effective interventions on concepts -- particularly in real-world conditions where complete and accurate concept supervisions are scarce. To address this, we propose Concept Embedding Models, a novel family of concept bottleneck models which goes beyond the current accuracy-vs-interpretability trade-off by learning interpretable high-dimensional concept representations. Our experiments demonstrate that Concept Embedding Models (1) attain better or competitive task accuracy w.r.t. standard neural models without concepts, (2) provide concept representations capturing meaningful semantics including and beyond their ground truth labels, (3) support test-time concept interventions whose effect in test accuracy surpasses that in standard concept bottleneck models, and (4) scale to real-world conditions where complete concept supervisions are scarce.
Encoding Concepts in Graph Neural Networks
Aug 07, 2022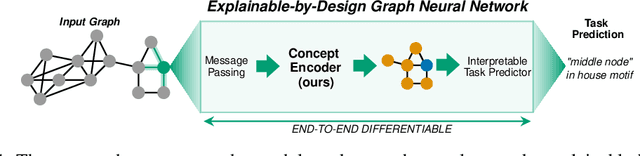

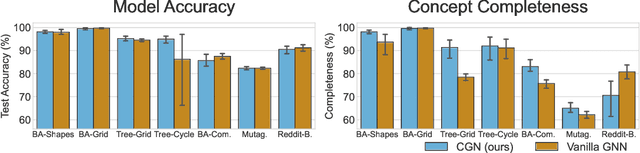
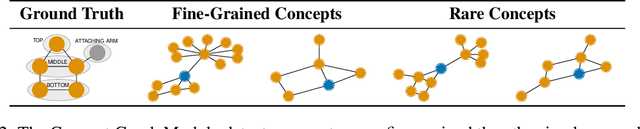
The opaque reasoning of Graph Neural Networks induces a lack of human trust. Existing graph network explainers attempt to address this issue by providing post-hoc explanations, however, they fail to make the model itself more interpretable. To fill this gap, we introduce the Concept Encoder Module, the first differentiable concept-discovery approach for graph networks. The proposed approach makes graph networks explainable by design by first discovering graph concepts and then using these to solve the task. Our results demonstrate that this approach allows graph networks to: (i) attain model accuracy comparable with their equivalent vanilla versions, (ii) discover meaningful concepts that achieve high concept completeness and purity scores, (iii) provide high-quality concept-based logic explanations for their prediction, and (iv) support effective interventions at test time: these can increase human trust as well as significantly improve model performance.
Knowledge-driven Active Learning
Oct 15, 2021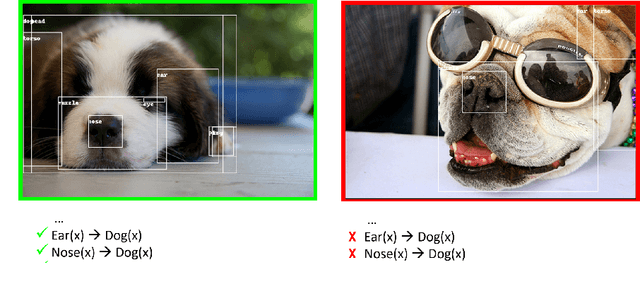

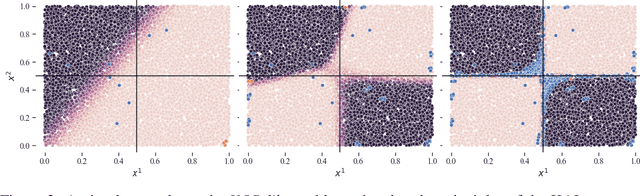

In the last few years, Deep Learning models have become increasingly popular. However, their deployment is still precluded in those contexts where the amount of supervised data is limited and manual labelling expensive. Active learning strategies aim at solving this problem by requiring supervision only on few unlabelled samples, which improve the most model performances after adding them to the training set. Most strategies are based on uncertain sample selection, and even often restricted to samples lying close to the decision boundary. Here we propose a very different approach, taking into consideration domain knowledge. Indeed, in the case of multi-label classification, the relationships among classes offer a way to spot incoherent predictions, i.e., predictions where the model may most likely need supervision. We have developed a framework where first-order-logic knowledge is converted into constraints and their violation is checked as a natural guide for sample selection. We empirically demonstrate that knowledge-driven strategy outperforms standard strategies, particularly on those datasets where domain knowledge is complete. Furthermore, we show how the proposed approach enables discovering data distributions lying far from training data. Finally, the proposed knowledge-driven strategy can be also easily used in object-detection problems where standard uncertainty-based techniques are difficult to apply.
Graph Neural Networks for Graph Drawing
Sep 21, 2021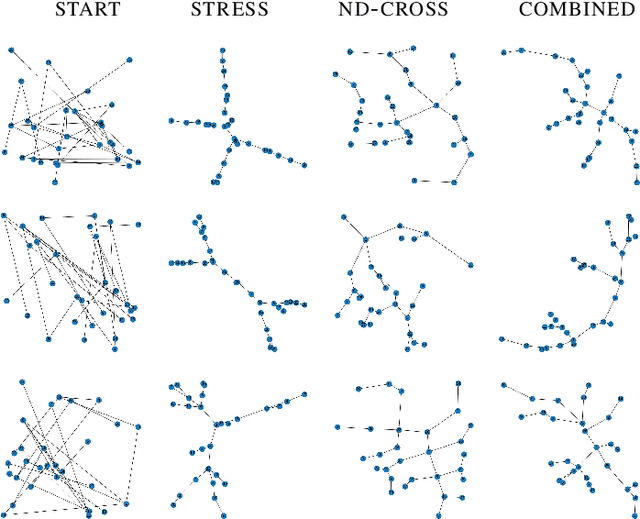
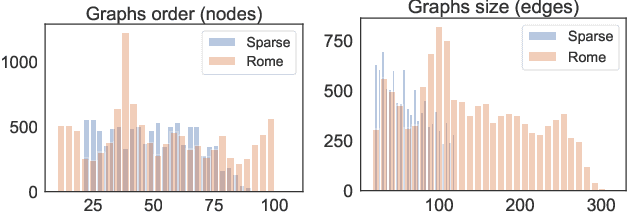


Graph Drawing techniques have been developed in the last few years with the purpose of producing aesthetically pleasing node-link layouts. Recently, the employment of differentiable loss functions has paved the road to the massive usage of Gradient Descent and related optimization algorithms. In this paper, we propose a novel framework for the development of Graph Neural Drawers (GND), machines that rely on neural computation for constructing efficient and complex maps. GND are Graph Neural Networks (GNNs) whose learning process can be driven by any provided loss function, such as the ones commonly employed in Graph Drawing. Moreover, we prove that this mechanism can be guided by loss functions computed by means of Feedforward Neural Networks, on the basis of supervision hints that express beauty properties, like the minimization of crossing edges. In this context, we show that GNNs can nicely be enriched by positional features to deal also with unlabelled vertexes. We provide a proof-of-concept by constructing a loss function for the edge-crossing and provide quantitative and qualitative comparisons among different GNN models working under the proposed framework.
Logic Explained Networks
Aug 11, 2021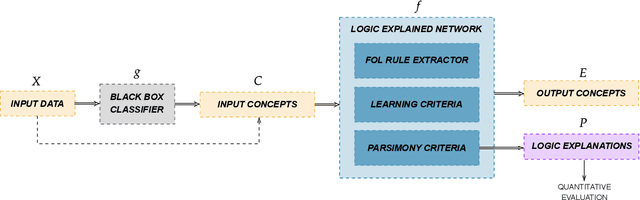

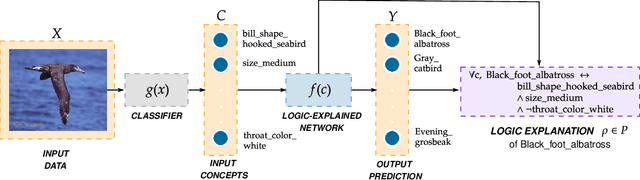

The large and still increasing popularity of deep learning clashes with a major limit of neural network architectures, that consists in their lack of capability in providing human-understandable motivations of their decisions. In situations in which the machine is expected to support the decision of human experts, providing a comprehensible explanation is a feature of crucial importance. The language used to communicate the explanations must be formal enough to be implementable in a machine and friendly enough to be understandable by a wide audience. In this paper, we propose a general approach to Explainable Artificial Intelligence in the case of neural architectures, showing how a mindful design of the networks leads to a family of interpretable deep learning models called Logic Explained Networks (LENs). LENs only require their inputs to be human-understandable predicates, and they provide explanations in terms of simple First-Order Logic (FOL) formulas involving such predicates. LENs are general enough to cover a large number of scenarios. Amongst them, we consider the case in which LENs are directly used as special classifiers with the capability of being explainable, or when they act as additional networks with the role of creating the conditions for making a black-box classifier explainable by FOL formulas. Despite supervised learning problems are mostly emphasized, we also show that LENs can learn and provide explanations in unsupervised learning settings. Experimental results on several datasets and tasks show that LENs may yield better classifications than established white-box models, such as decision trees and Bayesian rule lists, while providing more compact and meaningful explanations.
Entropy-based Logic Explanations of Neural Networks
Jun 22, 2021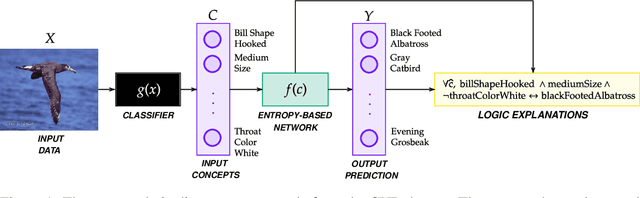
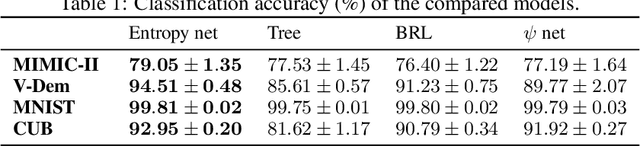
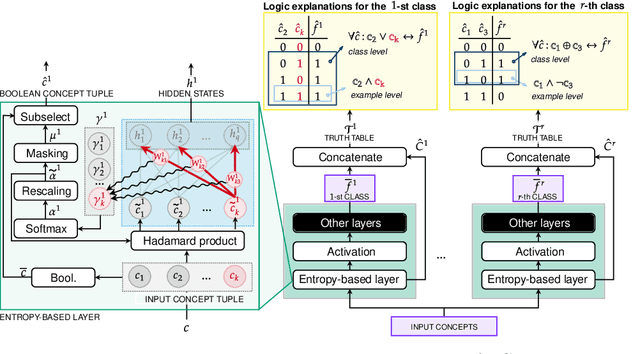
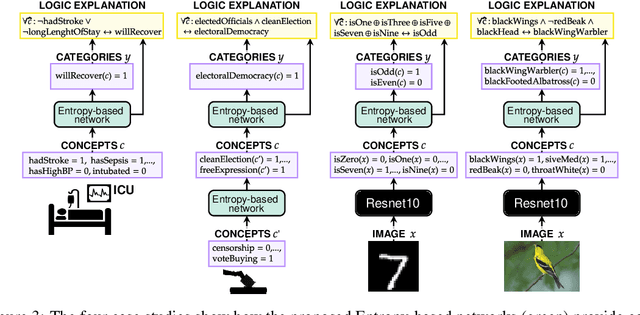
Explainable artificial intelligence has rapidly emerged since lawmakers have started requiring interpretable models for safety-critical domains. Concept-based neural networks have arisen as explainable-by-design methods as they leverage human-understandable symbols (i.e. concepts) to predict class memberships. However, most of these approaches focus on the identification of the most relevant concepts but do not provide concise, formal explanations of how such concepts are leveraged by the classifier to make predictions. In this paper, we propose a novel end-to-end differentiable approach enabling the extraction of logic explanations from neural networks using the formalism of First-Order Logic. The method relies on an entropy-based criterion which automatically identifies the most relevant concepts. We consider four different case studies to demonstrate that: (i) this entropy-based criterion enables the distillation of concise logic explanations in safety-critical domains from clinical data to computer vision; (ii) the proposed approach outperforms state-of-the-art white-box models in terms of classification accuracy.
LENs: a Python library for Logic Explained Networks
May 25, 2021LENs is a Python module integrating a variety of state-of-the-art approaches to provide logic explanations from neural networks. This package focuses on bringing these methods to non-specialists. It has minimal dependencies and it is distributed under the Apache 2.0 licence allowing both academic and commercial use. Source code and documentation can be downloaded from the github repository: https://github.com/pietrobarbiero/logic_explainer_networks.
Gradient-based Competitive Learning: Theory
Sep 06, 2020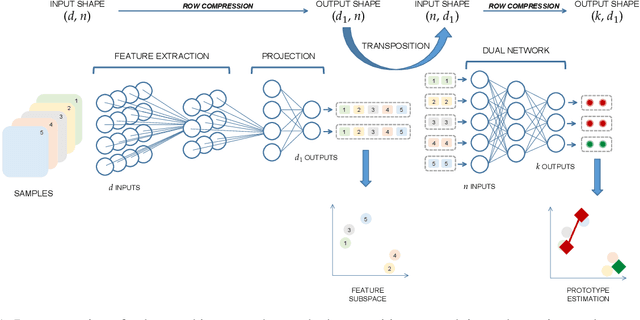
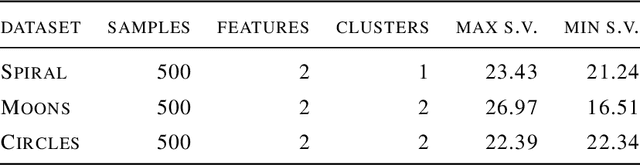

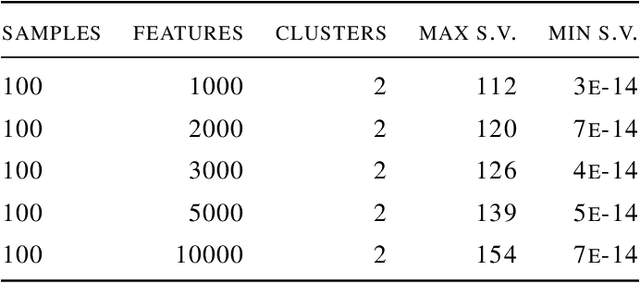
Deep learning has been widely used for supervised learning and classification/regression problems. Recently, a novel area of research has applied this paradigm to unsupervised tasks; indeed, a gradient-based approach extracts, efficiently and autonomously, the relevant features for handling input data. However, state-of-the-art techniques focus mostly on algorithmic efficiency and accuracy rather than mimic the input manifold. On the contrary, competitive learning is a powerful tool for replicating the input distribution topology. This paper introduces a novel perspective in this area by combining these two techniques: unsupervised gradient-based and competitive learning. The theory is based on the intuition that neural networks are able to learn topological structures by working directly on the transpose of the input matrix. At this purpose, the vanilla competitive layer and its dual are presented. The former is just an adaptation of a standard competitive layer for deep clustering, while the latter is trained on the transposed matrix. Their equivalence is extensively proven both theoretically and experimentally. However, the dual layer is better suited for handling very high-dimensional datasets. The proposed approach has a great potential as it can be generalized to a vast selection of topological learning tasks, such as non-stationary and hierarchical clustering; furthermore, it can also be integrated within more complex architectures such as autoencoders and generative adversarial networks.