 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring SAIG Methods for an Objective Evaluation of XAI
Feb 09, 2026The evaluation of eXplainable Artificial Intelligence (XAI) methods is a rapidly growing field, characterized by a wide variety of approaches. This diversity highlights the complexity of the XAI evaluation, which, unlike traditional AI assessment, lacks a universally correct ground truth for the explanation, making objective evaluation challenging. One promising direction to address this issue involves the use of what we term Synthetic Artificial Intelligence Ground truth (SAIG) methods, which generate artificial ground truths to enable the direct evaluation of XAI techniques. This paper presents the first review and analysis of SAIG methods. We introduce a novel taxonomy to classify these approaches, identifying seven key features that distinguish different SAIG methods. Our comparative study reveals a concerning lack of consensus on the most effective XAI evaluation techniques, underscoring the need for further research and standardization in this area.
Enhancing Generalization in Sickle Cell Disease Diagnosis through Ensemble Methods and Feature Importance Analysis
Jan 19, 2026This work presents a novel approach for selecting the optimal ensemble-based classification method and features with a primarly focus on achieving generalization, based on the state-of-the-art, to provide diagnostic support for Sickle Cell Disease using peripheral blood smear images of red blood cells. We pre-processed and segmented the microscopic images to ensure the extraction of high-quality features. To ensure the reliability of our proposed system, we conducted an in-depth analysis of interpretability. Leveraging techniques established in the literature, we extracted features from blood cells and employed ensemble machine learning methods to classify their morphology. Furthermore, we have devised a methodology to identify the most critical features for classification, aimed at reducing complexity and training time and enhancing interpretability in opaque models. Lastly, we validated our results using a new dataset, where our model overperformed state-of-the-art models in terms of generalization. The results of classifier ensembled of Random Forest and Extra Trees classifier achieved an harmonic mean of precision and recall (F1-score) of 90.71\% and a Sickle Cell Disease diagnosis support score (SDS-score) of 93.33\%. These results demonstrate notable enhancement from previous ones with Gradient Boosting classifier (F1-score 87.32\% and SDS-score 89.51\%). To foster scientific progress, we have made available the parameters for each model, the implemented code library, and the confusion matrices with the raw data.
Towards an Evaluation Framework for Explainable Artificial Intelligence Systems for Health and Well-being
Apr 11, 2025The integration of Artificial Intelligence in the development of computer systems presents a new challenge: make intelligent systems explainable to humans. This is especially vital in the field of health and well-being, where transparency in decision support systems enables healthcare professionals to understand and trust automated decisions and predictions. To address this need, tools are required to guide the development of explainable AI systems. In this paper, we introduce an evaluation framework designed to support the development of explainable AI systems for health and well-being. Additionally, we present a case study that illustrates the application of the framework in practice. We believe that our framework can serve as a valuable tool not only for developing explainable AI systems in healthcare but also for any AI system that has a significant impact on individuals.
Crowdsourced human-based computational approach for tagging peripheral blood smear sample images from Sickle Cell Disease patients using non-expert users
Jan 13, 2025In this paper, we present a human-based computation approach for the analysis of peripheral blood smear (PBS) images images in patients with Sickle Cell Disease (SCD). We used the Mechanical Turk microtask market to crowdsource the labeling of PBS images. We then use the expert-tagged erythrocytesIDB dataset to assess the accuracy and reliability of our proposal. Our results showed that when a robust consensus is achieved among the Mechanical Turk workers, probability of error is very low, based on comparison with expert analysis. This suggests that our proposed approach can be used to annotate datasets of PBS images, which can then be used to train automated methods for the diagnosis of SCD. In future work, we plan to explore the potential integration of our findings with outcomes obtained through automated methodologies. This could lead to the development of more accurate and reliable methods for the diagnosis of SCD
Geometric-Based Nail Segmentation for Clinical Measurements
Jan 10, 2025A robust segmentation method that can be used to perform measurements on toenails is presented. The proposed method is used as the first step in a clinical trial to objectively quantify the incidence of a particular pathology. For such an assessment, it is necessary to distinguish a nail, which locally appears to be similar to the skin. Many algorithms have been used, each of which leverages different aspects of toenail appearance. We used the Hough transform to locate the tip of the toe and estimate the nail location and size. Subsequently, we classified the super-pixels of the image based on their geometric and photometric information. Thereafter, the watershed transform delineated the border of the nail. The method was validated using a 348-image medical dataset, achieving an accuracy of 0.993 and an F-measure of 0.925. The proposed method is considerably robust across samples, with respect to factors such as nail shape, skin pigmentation, illumination conditions, and appearance of large regions affected by a medical condition
Meta-evaluating stability measures: MAX-Senstivity & AVG-Sensitivity
Dec 14, 2024The use of eXplainable Artificial Intelligence (XAI) systems has introduced a set of challenges that need resolution. The XAI robustness, or stability, has been one of the goals of the community from its beginning. Multiple authors have proposed evaluating this feature using objective evaluation measures. Nonetheless, many questions remain. With this work, we propose a novel approach to meta-evaluate these metrics, i.e. analyze the correctness of the evaluators. We propose two new tests that allowed us to evaluate two different stability measures: AVG-Sensitiviy and MAX-Senstivity. We tested their reliability in the presence of perfect and robust explanations, generated with a Decision Tree; as well as completely random explanations and prediction. The metrics results showed their incapacity of identify as erroneous the random explanations, highlighting their overall unreliability.
A comprehensive study on fidelity metrics for XAI
Jan 19, 2024



The use of eXplainable Artificial Intelligence (XAI) systems has introduced a set of challenges that need resolution. Herein, we focus on how to correctly select an XAI method, an open questions within the field. The inherent difficulty of this task is due to the lack of a ground truth. Several authors have proposed metrics to approximate the fidelity of different XAI methods. These metrics lack verification and have concerning disagreements. In this study, we proposed a novel methodology to verify fidelity metrics, using a well-known transparent model, namely a decision tree. This model allowed us to obtain explanations with perfect fidelity. Our proposal constitutes the first objective benchmark for these metrics, facilitating a comparison of existing proposals, and surpassing existing methods. We applied our benchmark to assess the existing fidelity metrics in two different experiments, each using public datasets comprising 52,000 images. The images from these datasets had a size a 128 by 128 pixels and were synthetic data that simplified the training process. All metric values, indicated a lack of fidelity, with the best one showing a 30 \% deviation from the expected values for perfect explanation. Our experimentation led us to conclude that the current fidelity metrics are not reliable enough to be used in real scenarios. From this finding, we deemed it necessary to development new metrics, to avoid the detected problems, and we recommend the usage of our proposal as a benchmark within the scientific community to address these limitations.
A novel approach to generate datasets with XAI ground truth to evaluate image models
Feb 11, 2023With the increased usage of artificial intelligence (AI), it is imperative to understand how these models work internally. These needs have led to the development of a new field called eXplainable artificial intelligence (XAI). This field consists of on a set of techniques that allows us to theoretically determine the cause of the AI decisions. One unsolved question about XAI is how to measure the quality of explanations. In this study, we propose a new method to generate datasets with ground truth (GT). These datasets allow us to measure how faithful is a method without ad hoc solutions. We conducted a set of experiments that compared our GT with real model explanations and obtained excellent results confirming that our proposed method is correct.
Sickle-cell disease diagnosis support selecting the most appropriate machinelearning method: Towards a general and interpretable approach for cellmorphology analysis from microscopy images
Oct 09, 2020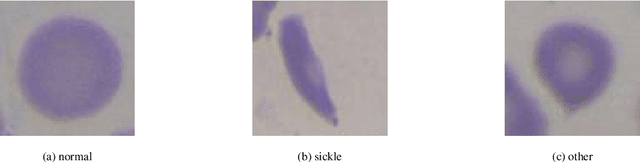

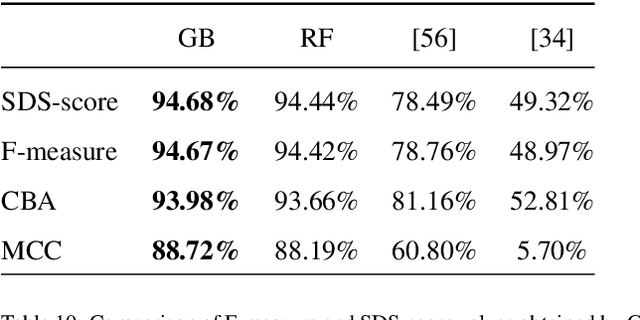

In this work we propose an approach to select the classification method and features, based on the state-of-the-art, with best performance for diagnostic support through peripheral blood smear images of red blood cells. In our case we used samples of patients with sickle-cell disease which can be generalized for other study cases. To trust the behavior of the proposed system, we also analyzed the interpretability. We pre-processed and segmented microscopic images, to ensure high feature quality. We applied the methods used in the literature to extract the features from blood cells and the machine learning methods to classify their morphology. Next, we searched for their best parameters from the resulting data in the feature extraction phase. Then, we found the best parameters for every classifier using Randomized and Grid search. For the sake of scientific progress, we published parameters for each classifier, the implemented code library, the confusion matrices with the raw data, and we used the public erythrocytesIDB dataset for validation. We also defined how to select the most important features for classification to decrease the complexity and the training time, and for interpretability purpose in opaque models. Finally, comparing the best performing classification methods with the state-of-the-art, we obtained better results even with interpretable model classifiers.
* 35 pages, 10 tables
Modelling depth for nonparametric foreground segmentation using RGBD devices
Sep 29, 2016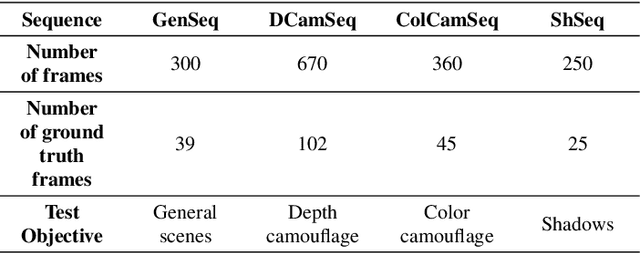


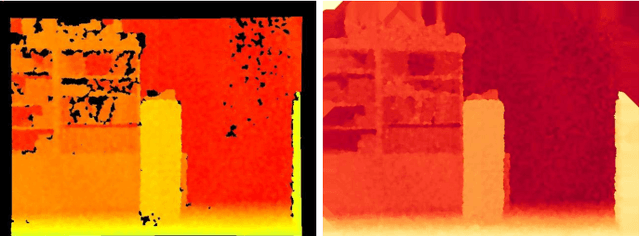
The problem of detecting changes in a scene and segmenting the foreground from background is still challenging, despite previous work. Moreover, new RGBD capturing devices include depth cues, which could be incorporated to improve foreground segmentation. In this work, we present a new nonparametric approach where a unified model mixes the device multiple information cues. In order to unify all the device channel cues, a new probabilistic depth data model is also proposed where we show how handle the inaccurate data to improve foreground segmentation. A new RGBD video dataset is presented in order to introduce a new standard for comparison purposes of this kind of algorithms. Results show that the proposed approach can handle several practical situations and obtain good results in all cases.