 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Zero-shot Visual Search via Target and Context-aware Transformer
Nov 24, 2022



Visual search is a ubiquitous challenge in natural vision, including daily tasks such as finding a friend in a crowd or searching for a car in a parking lot. Human rely heavily on relevant target features to perform goal-directed visual search. Meanwhile, context is of critical importance for locating a target object in complex scenes as it helps narrow down the search area and makes the search process more efficient. However, few works have combined both target and context information in visual search computational models. Here we propose a zero-shot deep learning architecture, TCT (Target and Context-aware Transformer), that modulates self attention in the Vision Transformer with target and contextual relevant information to enable human-like zero-shot visual search performance. Target modulation is computed as patch-wise local relevance between the target and search images, whereas contextual modulation is applied in a global fashion. We conduct visual search experiments on TCT and other competitive visual search models on three natural scene datasets with varying levels of difficulty. TCT demonstrates human-like performance in terms of search efficiency and beats the SOTA models in challenging visual search tasks. Importantly, TCT generalizes well across datasets with novel objects without retraining or fine-tuning. Furthermore, we also introduce a new dataset to benchmark models for invariant visual search under incongruent contexts. TCT manages to search flexibly via target and context modulation, even under incongruent contexts.
Human or Machine? Turing Tests for Vision and Language
Nov 23, 2022As AI algorithms increasingly participate in daily activities that used to be the sole province of humans, we are inevitably called upon to consider how much machines are really like us. To address this question, we turn to the Turing test and systematically benchmark current AIs in their abilities to imitate humans. We establish a methodology to evaluate humans versus machines in Turing-like tests and systematically evaluate a representative set of selected domains, parameters, and variables. The experiments involved testing 769 human agents, 24 state-of-the-art AI agents, 896 human judges, and 8 AI judges, in 21,570 Turing tests across 6 tasks encompassing vision and language modalities. Surprisingly, the results reveal that current AIs are not far from being able to impersonate human judges across different ages, genders, and educational levels in complex visual and language challenges. In contrast, simple AI judges outperform human judges in distinguishing human answers versus machine answers. The curated large-scale Turing test datasets introduced here and their evaluation metrics provide valuable insights to assess whether an agent is human or not. The proposed formulation to benchmark human imitation ability in current AIs paves a way for the research community to expand Turing tests to other research areas and conditions. All of source code and data are publicly available at https://tinyurl.com/8x8nha7p
Reason from Context with Self-supervised Learning
Nov 23, 2022



A tiny object in the sky cannot be an elephant. Context reasoning is critical in visual recognition, where current inputs need to be interpreted in the light of previous experience and knowledge. To date, research into contextual reasoning in visual recognition has largely proceeded with supervised learning methods. The question of whether contextual knowledge can be captured with self-supervised learning regimes remains under-explored. Here, we established a methodology for context-aware self-supervised learning. We proposed a novel Self-supervised Learning Method for Context Reasoning (SeCo), where the only inputs to SeCo are unlabeled images with multiple objects present in natural scenes. Similar to the distinction between fovea and periphery in human vision, SeCo processes self-proposed target object regions and their contexts separately, and then employs a learnable external memory for retrieving and updating context-relevant target information. To evaluate the contextual associations learned by the computational models, we introduced two evaluation protocols, lift-the-flap and object priming, addressing the problems of "what" and "where" in context reasoning. In both tasks, SeCo outperformed all state-of-the-art (SOTA) self-supervised learning methods by a significant margin. Our network analysis revealed that the external memory in SeCo learns to store prior contextual knowledge, facilitating target identity inference in lift-the-flap task. Moreover, we conducted psychophysics experiments and introduced a Human benchmark in Object Priming dataset (HOP). Our quantitative and qualitative results demonstrate that SeCo approximates human-level performance and exhibits human-like behavior. All our source code and data are publicly available here.
White-Box Adversarial Policies in Deep Reinforcement Learning
Sep 05, 2022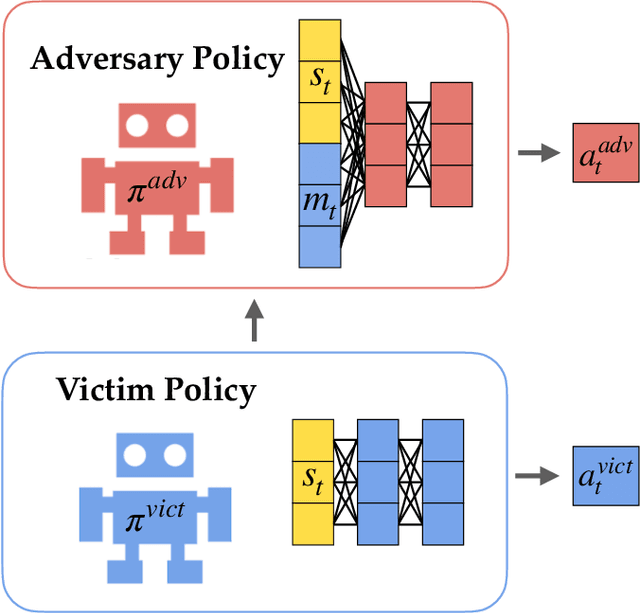
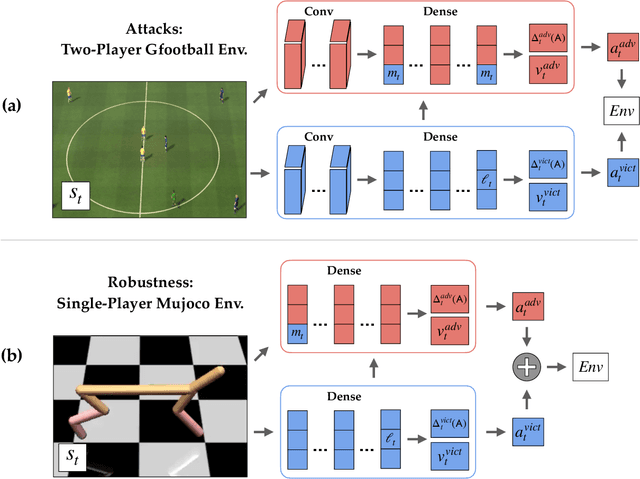
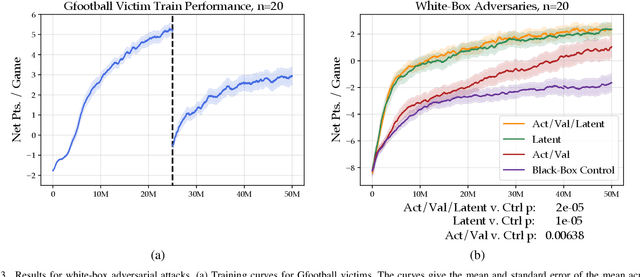
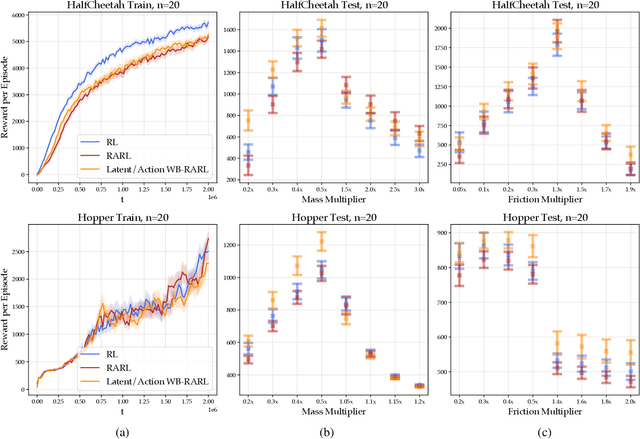
Adversarial examples against AI systems pose both risks via malicious attacks and opportunities for improving robustness via adversarial training. In multiagent settings, adversarial policies can be developed by training an adversarial agent to minimize a victim agent's rewards. Prior work has studied black-box attacks where the adversary only sees the state observations and effectively treats the victim as any other part of the environment. In this work, we experiment with white-box adversarial policies to study whether an agent's internal state can offer useful information for other agents. We make three contributions. First, we introduce white-box adversarial policies in which an attacker can observe a victim's internal state at each timestep. Second, we demonstrate that white-box access to a victim makes for better attacks in two-agent environments, resulting in both faster initial learning and higher asymptotic performance against the victim. Third, we show that training against white-box adversarial policies can be used to make learners in single-agent environments more robust to domain shifts.
What makes domain generalization hard?
Jun 15, 2022
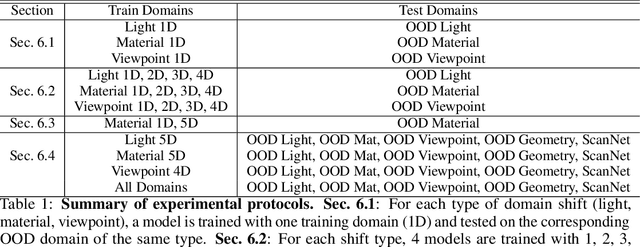
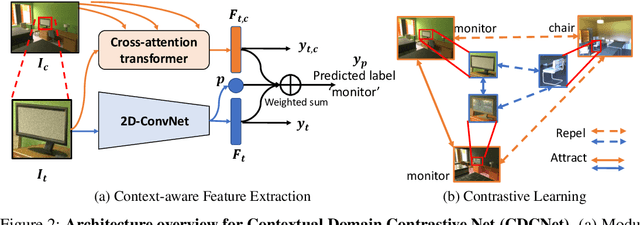
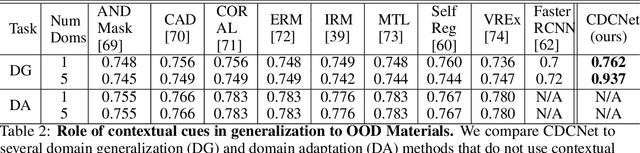
While several methodologies have been proposed for the daunting task of domain generalization, understanding what makes this task challenging has received little attention. Here we present SemanticDG (Semantic Domain Generalization): a benchmark with 15 photo-realistic domains with the same geometry, scene layout and camera parameters as the popular 3D ScanNet dataset, but with controlled domain shifts in lighting, materials, and viewpoints. Using this benchmark, we investigate the impact of each of these semantic shifts on generalization independently. Visual recognition models easily generalize to novel lighting, but struggle with distribution shifts in materials and viewpoints. Inspired by human vision, we hypothesize that scene context can serve as a bridge to help models generalize across material and viewpoint domain shifts and propose a context-aware vision transformer along with a contrastive loss over material and viewpoint changes to address these domain shifts. Our approach (dubbed as CDCNet) outperforms existing domain generalization methods by over an 18% margin. As a critical benchmark, we also conduct psychophysics experiments and find that humans generalize equally well across lighting, materials and viewpoints. The benchmark and computational model introduced here help understand the challenges associated with generalization across domains and provide initial steps towards extrapolation to semantic distribution shifts. We include all data and source code in the supplement.
Error-driven Input Modulation: Solving the Credit Assignment Problem without a Backward Pass
Jan 27, 2022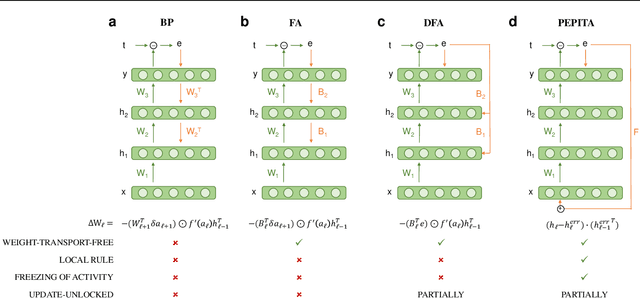

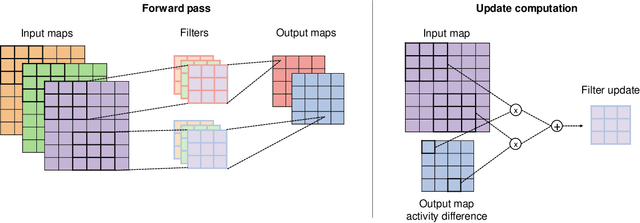
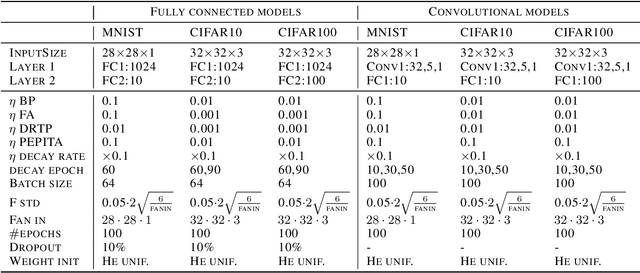
Supervised learning in artificial neural networks typically relies on backpropagation, where the weights are updated based on the error-function gradients and sequentially propagated from the output layer to the input layer. Although this approach has proven effective in a wide domain of applications, it lacks biological plausibility in many regards, including the weight symmetry problem, the dependence of learning on non-local signals, the freezing of neural activity during error propagation, and the update locking problem. Alternative training schemes - such as sign symmetry, feedback alignment, and direct feedback alignment - have been introduced, but invariably rely on a backward pass that hinders the possibility of solving all the issues simultaneously. Here, we propose to replace the backward pass with a second forward pass in which the input signal is modulated based on the error of the network. We show that this novel learning rule comprehensively addresses all the above-mentioned issues and can be applied to both fully connected and convolutional models. We test this learning rule on MNIST, CIFAR-10, and CIFAR-100. These results help incorporate biological principles into machine learning.
On the Efficacy of Co-Attention Transformer Layers in Visual Question Answering
Jan 11, 2022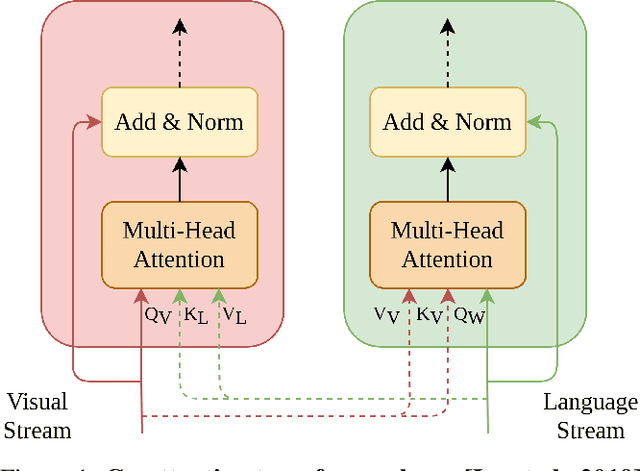

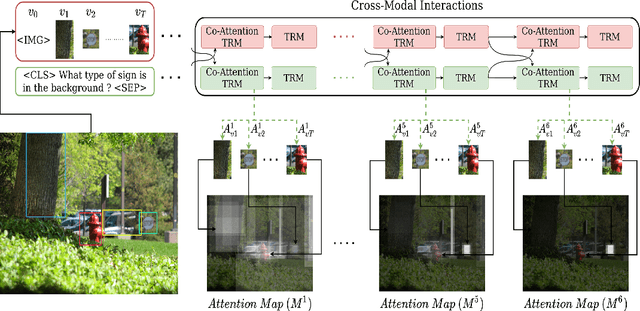

In recent years, multi-modal transformers have shown significant progress in Vision-Language tasks, such as Visual Question Answering (VQA), outperforming previous architectures by a considerable margin. This improvement in VQA is often attributed to the rich interactions between vision and language streams. In this work, we investigate the efficacy of co-attention transformer layers in helping the network focus on relevant regions while answering the question. We generate visual attention maps using the question-conditioned image attention scores in these co-attention layers. We evaluate the effect of the following critical components on visual attention of a state-of-the-art VQA model: (i) number of object region proposals, (ii) question part of speech (POS) tags, (iii) question semantics, (iv) number of co-attention layers, and (v) answer accuracy. We compare the neural network attention maps against human attention maps both qualitatively and quantitatively. Our findings indicate that co-attention transformer modules are crucial in attending to relevant regions of the image given a question. Importantly, we observe that the semantic meaning of the question is not what drives visual attention, but specific keywords in the question do. Our work sheds light on the function and interpretation of co-attention transformer layers, highlights gaps in current networks, and can guide the development of future VQA models and networks that simultaneously process visual and language streams.
One Thing to Fool them All: Generating Interpretable, Universal, and Physically-Realizable Adversarial Features
Oct 11, 2021

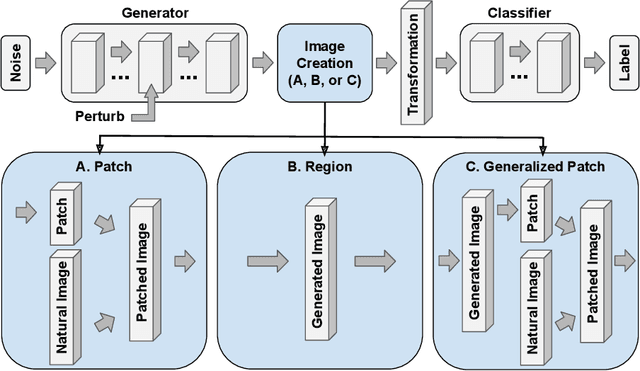
It is well understood that modern deep networks are vulnerable to adversarial attacks. However, conventional methods fail to produce adversarial perturbations that are intelligible to humans, and they pose limited threats in the physical world. To study feature-class associations in networks and better understand the real-world threats they face, we develop feature-level adversarial perturbations using deep image generators and a novel optimization objective. We term these feature-fool attacks. We show that they are versatile and use them to generate targeted feature-level attacks at the ImageNet scale that are simultaneously interpretable, universal to any source image, and physically-realizable. These attacks can also reveal spurious, semantically-describable feature/class associations, and we use them to guide the design of "copy/paste" adversaries in which one natural image is pasted into another to cause a targeted misclassification.
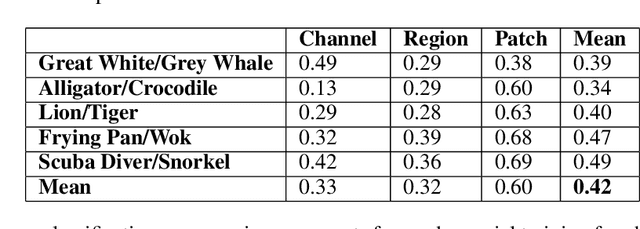
Visual Search Asymmetry: Deep Nets and Humans Share Similar Inherent Biases
Jun 05, 2021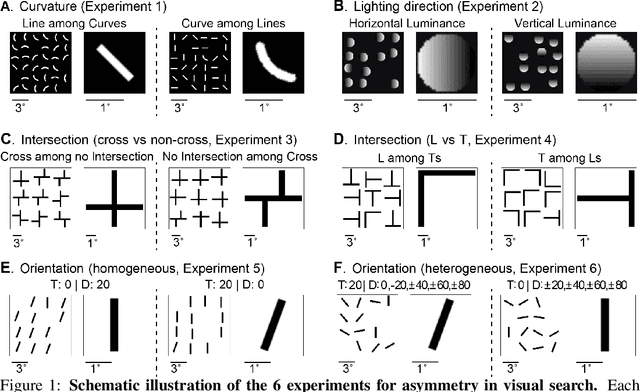
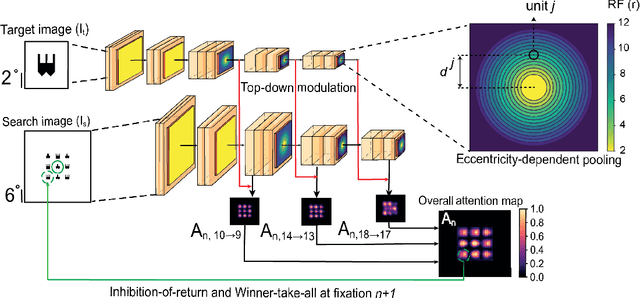
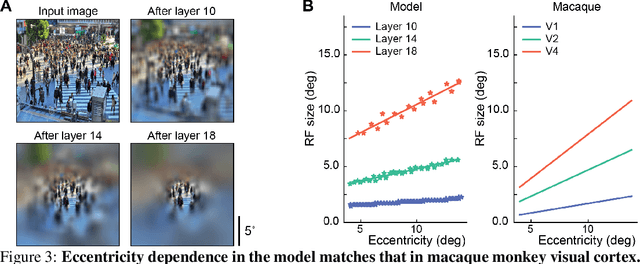
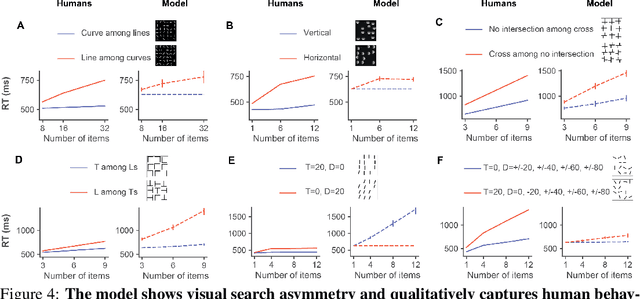
Visual search is a ubiquitous and often challenging daily task, exemplified by looking for the car keys at home or a friend in a crowd. An intriguing property of some classical search tasks is an asymmetry such that finding a target A among distractors B can be easier than finding B among A. To elucidate the mechanisms responsible for asymmetry in visual search, we propose a computational model that takes a target and a search image as inputs and produces a sequence of eye movements until the target is found. The model integrates eccentricity-dependent visual recognition with target-dependent top-down cues. We compared the model against human behavior in six paradigmatic search tasks that show asymmetry in humans. Without prior exposure to the stimuli or task-specific training, the model provides a plausible mechanism for search asymmetry. We hypothesized that the polarity of search asymmetry arises from experience with the natural environment. We tested this hypothesis by training the model on an augmented version of ImageNet where the biases of natural images were either removed or reversed. The polarity of search asymmetry disappeared or was altered depending on the training protocol. This study highlights how classical perceptual properties can emerge in neural network models, without the need for task-specific training, but rather as a consequence of the statistical properties of the developmental diet fed to the model. All source code and stimuli are publicly available https://github.com/kreimanlab/VisualSearchAsymmetry
What can human minimal videos tell us about dynamic recognition models?
Apr 19, 2021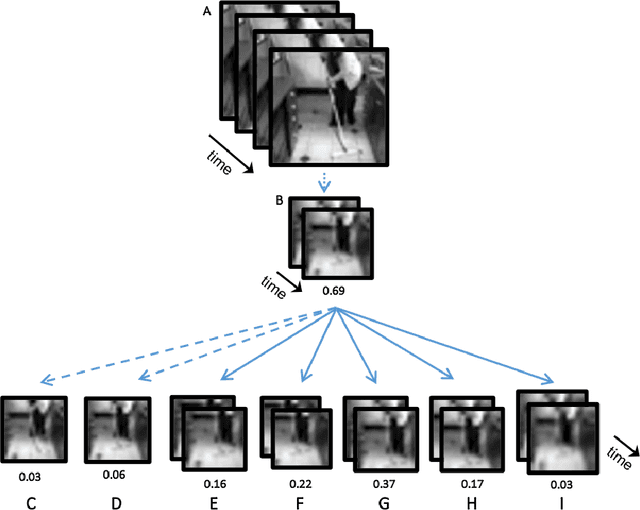

In human vision objects and their parts can be visually recognized from purely spatial or purely temporal information but the mechanisms integrating space and time are poorly understood. Here we show that human visual recognition of objects and actions can be achieved by efficiently combining spatial and motion cues in configurations where each source on its own is insufficient for recognition. This analysis is obtained by identifying minimal videos: these are short and tiny video clips in which objects, parts, and actions can be reliably recognized, but any reduction in either space or time makes them unrecognizable. State-of-the-art deep networks for dynamic visual recognition cannot replicate human behavior in these configurations. This gap between humans and machines points to critical mechanisms in human dynamic vision that are lacking in current models.