 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Transformations with Encoder-Decoder Networks
Oct 19, 2017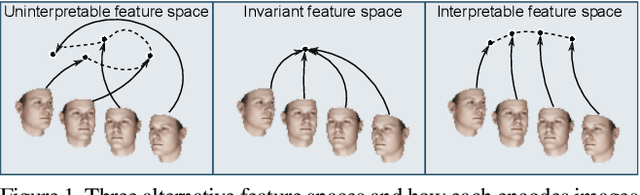
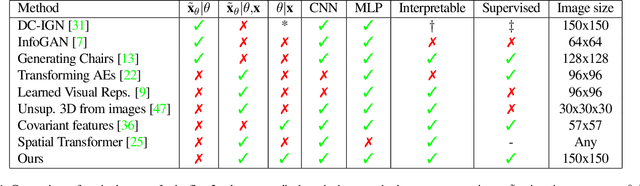
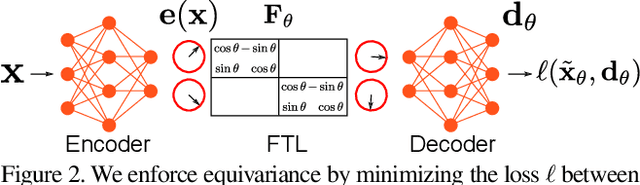
Deep feature spaces have the capacity to encode complex transformations of their input data. However, understanding the relative feature-space relationship between two transformed encoded images is difficult. For instance, what is the relative feature space relationship between two rotated images? What is decoded when we interpolate in feature space? Ideally, we want to disentangle confounding factors, such as pose, appearance, and illumination, from object identity. Disentangling these is difficult because they interact in very nonlinear ways. We propose a simple method to construct a deep feature space, with explicitly disentangled representations of several known transformations. A person or algorithm can then manipulate the disentangled representation, for example, to re-render an image with explicit control over parameterized degrees of freedom. The feature space is constructed using a transforming encoder-decoder network with a custom feature transform layer, acting on the hidden representations. We demonstrate the advantages of explicit disentangling on a variety of datasets and transformations, and as an aid for traditional tasks, such as classification.
Unsupervised Monocular Depth Estimation with Left-Right Consistency
Apr 12, 2017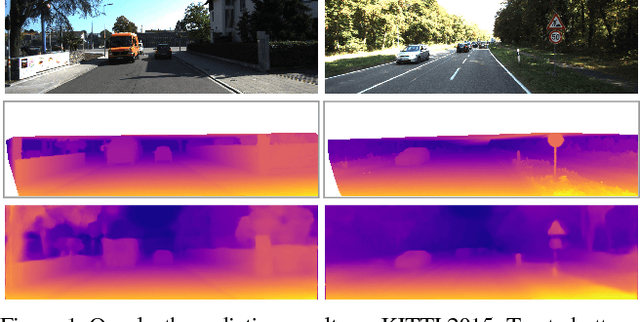

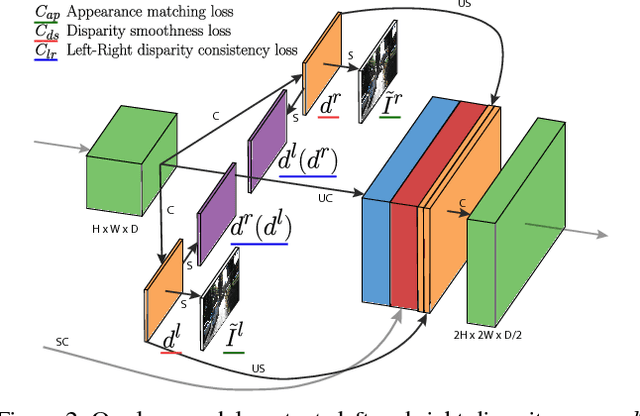
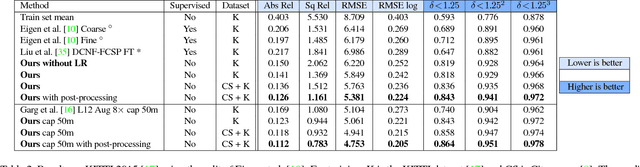
Learning based methods have shown very promising results for the task of depth estimation in single images. However, most existing approaches treat depth prediction as a supervised regression problem and as a result, require vast quantities of corresponding ground truth depth data for training. Just recording quality depth data in a range of environments is a challenging problem. In this paper, we innovate beyond existing approaches, replacing the use of explicit depth data during training with easier-to-obtain binocular stereo footage. We propose a novel training objective that enables our convolutional neural network to learn to perform single image depth estimation, despite the absence of ground truth depth data. Exploiting epipolar geometry constraints, we generate disparity images by training our network with an image reconstruction loss. We show that solving for image reconstruction alone results in poor quality depth images. To overcome this problem, we propose a novel training loss that enforces consistency between the disparities produced relative to both the left and right images, leading to improved performance and robustness compared to existing approaches. Our method produces state of the art results for monocular depth estimation on the KITTI driving dataset, even outperforming supervised methods that have been trained with ground truth depth.
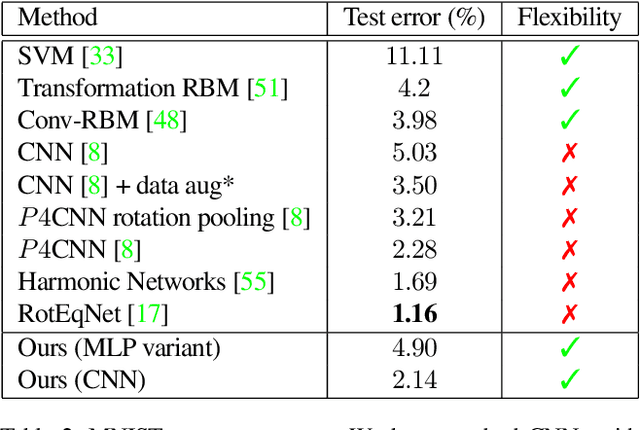
Harmonic Networks: Deep Translation and Rotation Equivariance
Apr 11, 2017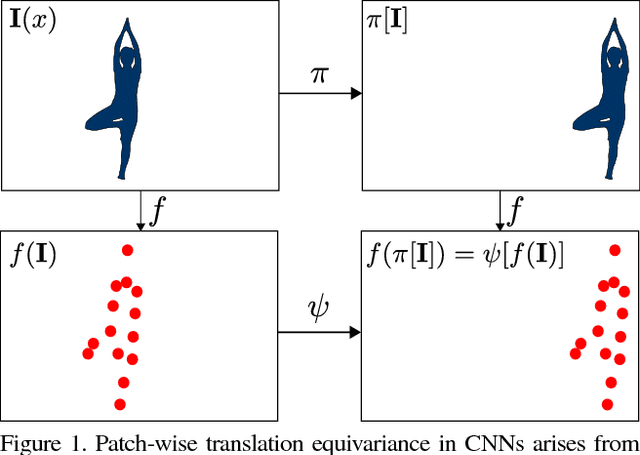
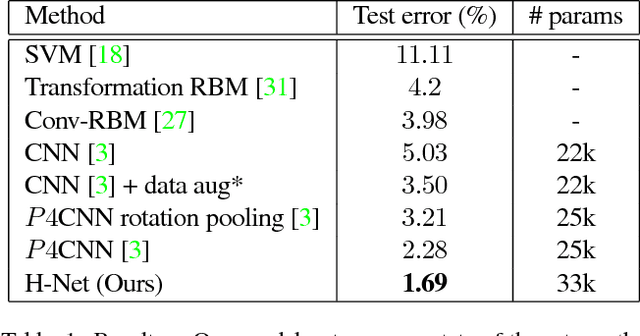
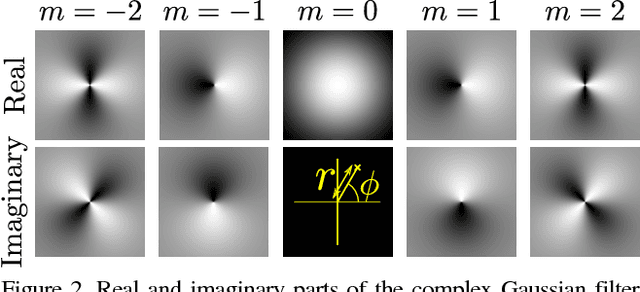
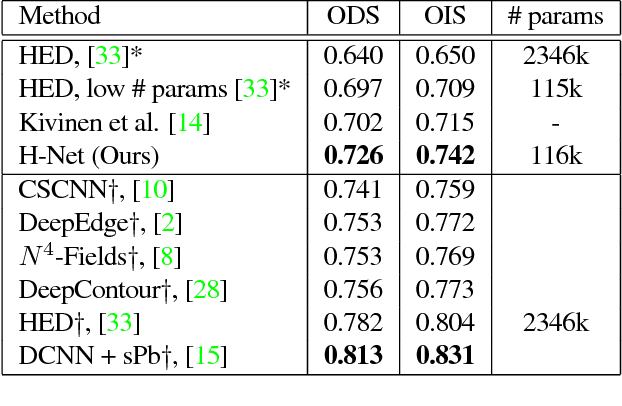
Translating or rotating an input image should not affect the results of many computer vision tasks. Convolutional neural networks (CNNs) are already translation equivariant: input image translations produce proportionate feature map translations. This is not the case for rotations. Global rotation equivariance is typically sought through data augmentation, but patch-wise equivariance is more difficult. We present Harmonic Networks or H-Nets, a CNN exhibiting equivariance to patch-wise translation and 360-rotation. We achieve this by replacing regular CNN filters with circular harmonics, returning a maximal response and orientation for every receptive field patch. H-Nets use a rich, parameter-efficient and low computational complexity representation, and we show that deep feature maps within the network encode complicated rotational invariants. We demonstrate that our layers are general enough to be used in conjunction with the latest architectures and techniques, such as deep supervision and batch normalization. We also achieve state-of-the-art classification on rotated-MNIST, and competitive results on other benchmark challenges.
Swipe Mosaics from Video
Sep 26, 2016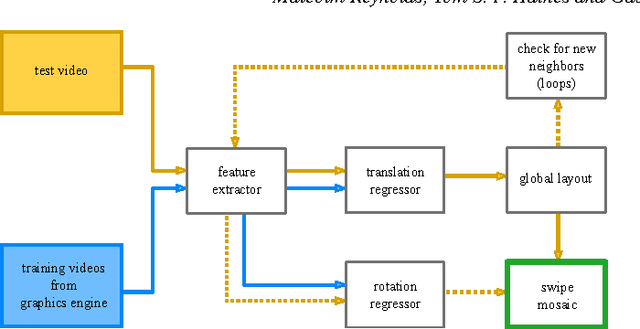

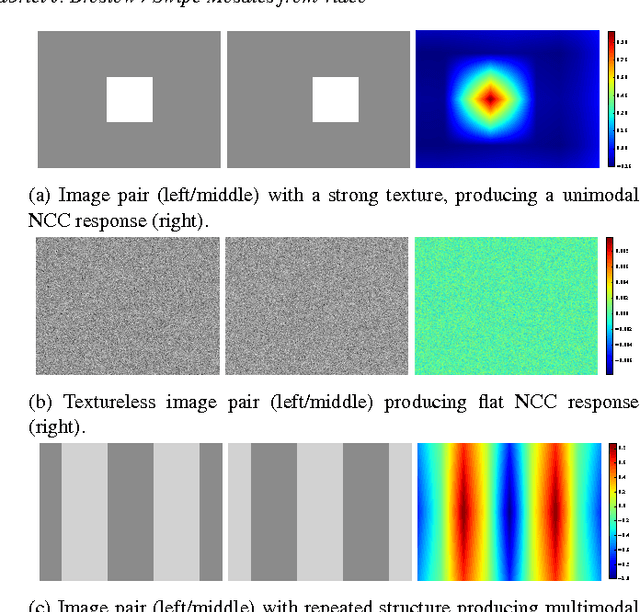
A panoramic image mosaic is an attractive visualization for viewing many overlapping photos, but its images must be both captured and processed correctly to produce an acceptable composite. We propose Swipe Mosaics, an interactive visualization that places the individual video frames on a 2D planar map that represents the layout of the physical scene. Compared to traditional panoramic mosaics, our capture is easier because the user can both translate the camera center and film moving subjects. Processing and display degrade gracefully if the footage lacks distinct, overlapping, non-repeating texture. Our proposed visual odometry algorithm produces a distribution over (x,y) translations for image pairs. Inferring a distribution of possible camera motions allows us to better cope with parallax, lack of texture, dynamic scenes, and other phenomena that hurt deterministic reconstruction techniques. Robustness is obtained by training on synthetic scenes with known camera motions. We show that Swipe Mosaics are easy to generate, support a wide range of difficult scenes, and are useful for documenting a scene for closer inspection.
Hierarchical Subquery Evaluation for Active Learning on a Graph
Apr 30, 2015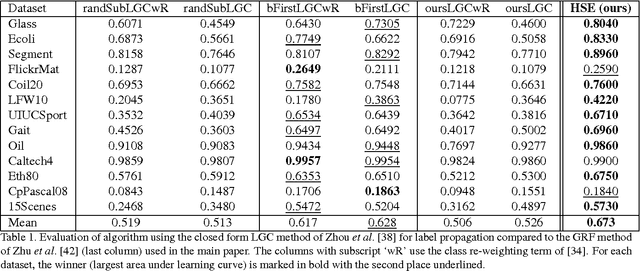
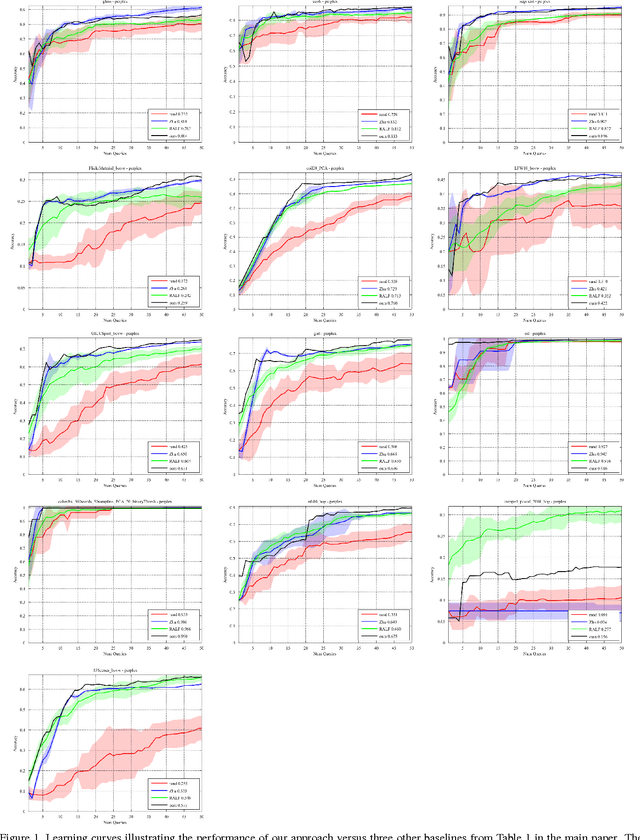
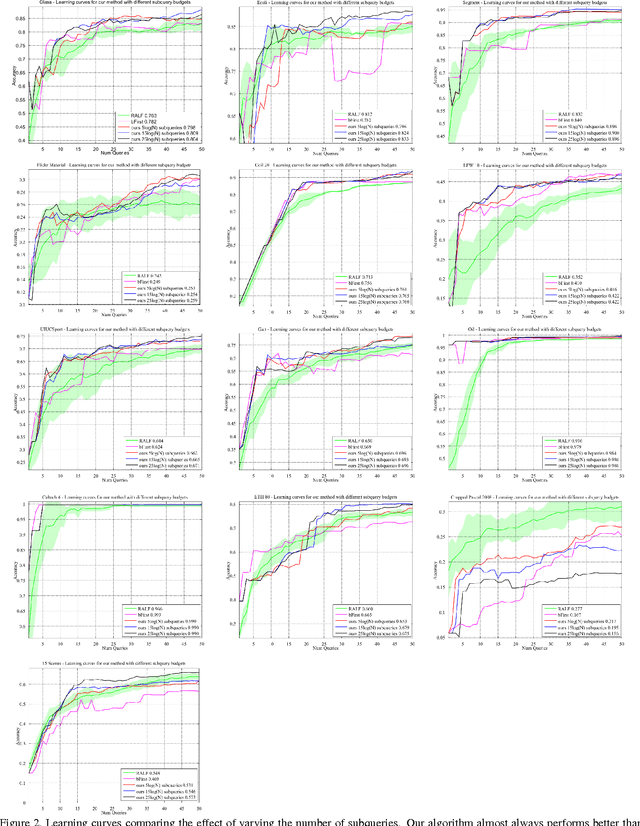
To train good supervised and semi-supervised object classifiers, it is critical that we not waste the time of the human experts who are providing the training labels. Existing active learning strategies can have uneven performance, being efficient on some datasets but wasteful on others, or inconsistent just between runs on the same dataset. We propose perplexity based graph construction and a new hierarchical subquery evaluation algorithm to combat this variability, and to release the potential of Expected Error Reduction. Under some specific circumstances, Expected Error Reduction has been one of the strongest-performing informativeness criteria for active learning. Until now, it has also been prohibitively costly to compute for sizeable datasets. We demonstrate our highly practical algorithm, comparing it to other active learning measures on classification datasets that vary in sparsity, dimensionality, and size. Our algorithm is consistent over multiple runs and achieves high accuracy, while querying the human expert for labels at a frequency that matches their desired time budget.
Becoming the Expert - Interactive Multi-Class Machine Teaching
Apr 28, 2015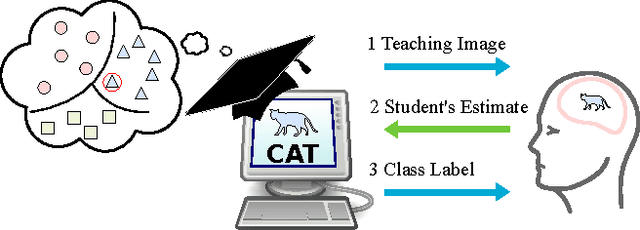


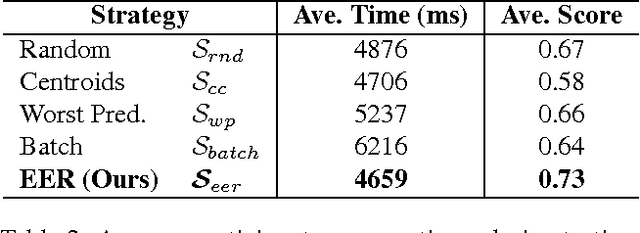
Compared to machines, humans are extremely good at classifying images into categories, especially when they possess prior knowledge of the categories at hand. If this prior information is not available, supervision in the form of teaching images is required. To learn categories more quickly, people should see important and representative images first, followed by less important images later - or not at all. However, image-importance is individual-specific, i.e. a teaching image is important to a student if it changes their overall ability to discriminate between classes. Further, students keep learning, so while image-importance depends on their current knowledge, it also varies with time. In this work we propose an Interactive Machine Teaching algorithm that enables a computer to teach challenging visual concepts to a human. Our adaptive algorithm chooses, online, which labeled images from a teaching set should be shown to the student as they learn. We show that a teaching strategy that probabilistically models the student's ability and progress, based on their correct and incorrect answers, produces better 'experts'. We present results using real human participants across several varied and challenging real-world datasets.
Context Tricks for Cheap Semantic Segmentation
Feb 17, 2015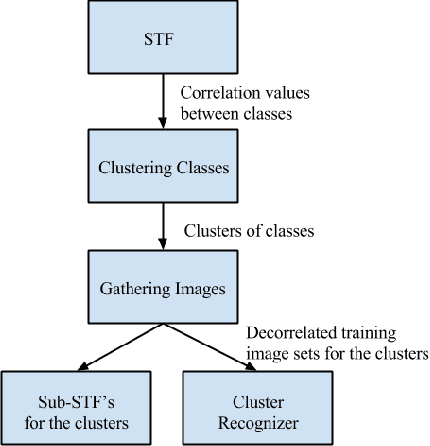
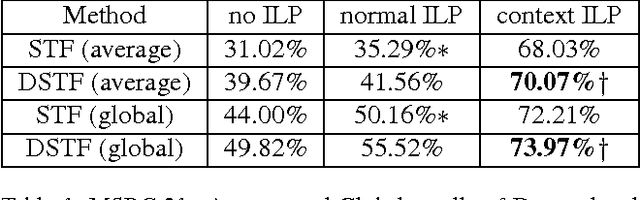
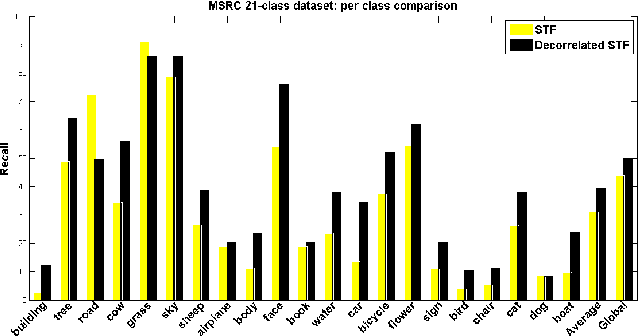
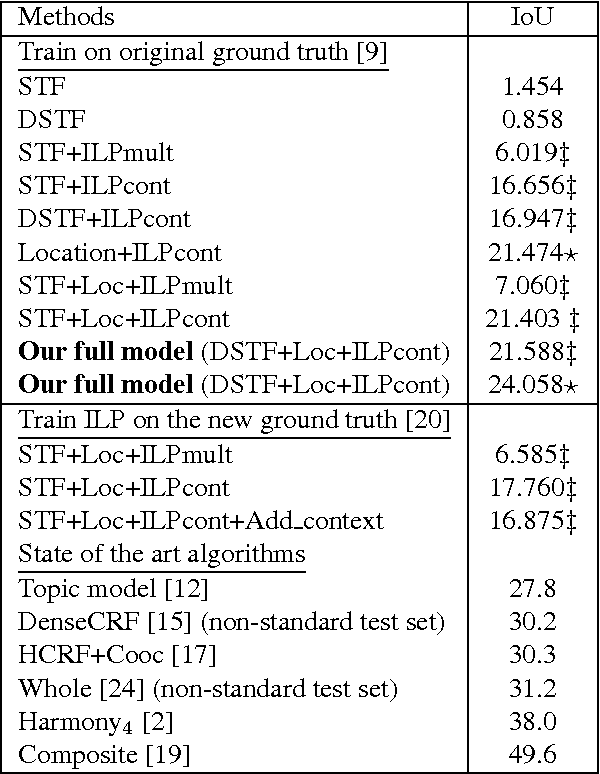
Accurate semantic labeling of image pixels is difficult because intra-class variability is often greater than inter-class variability. In turn, fast semantic segmentation is hard because accurate models are usually too complicated to also run quickly at test-time. Our experience with building and running semantic segmentation systems has also shown a reasonably obvious bottleneck on model complexity, imposed by small training datasets. We therefore propose two simple complementary strategies that leverage context to give better semantic segmentation, while scaling up or down to train on different-sized datasets. As easy modifications for existing semantic segmentation algorithms, we introduce Decorrelated Semantic Texton Forests, and the Context Sensitive Image Level Prior. The proposed modifications are tested using a Semantic Texton Forest (STF) system, and the modifications are validated on two standard benchmark datasets, MSRC-21 and PascalVOC-2010. In Python based comparisons, our system is insignificantly slower than STF at test-time, yet produces superior semantic segmentations overall, with just push-button training.