 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMix and Match: Context Pairing for Scalable Topic-Controlled Educational Summarisation
Apr 20, 2026Topic-controlled summarisation enables users to generate summaries focused on specific aspects of source documents. This paper investigates a data augmentation strategy for training small language models (sLMs) to perform topic-controlled summarisation. We propose a pairwise data augmentation method that combines contexts from different documents to create contrastive training examples, enabling models to learn the relationship between topics and summaries more effectively. Using the SciTLDR dataset enriched with Wikipedia-derived topics, we systematically evaluate how augmentation scale affects model performance. Results show consistent improvements in win rate and semantic alignment as the augmentation scale increases, while the amount of real training data remains fixed. Consequently, a T5-base model trained with our augmentation approach achieves competitive performance relative to larger models, despite using significantly fewer parameters and substantially fewer real training examples.
Context Tricks for Cheap Semantic Segmentation
Feb 17, 2015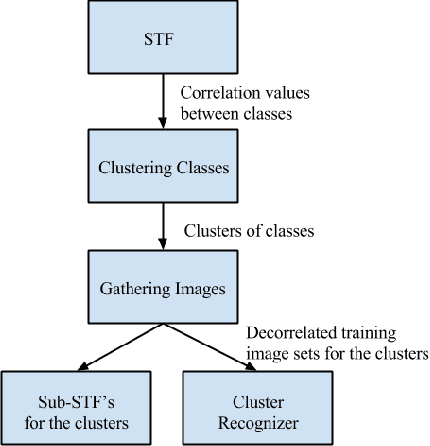
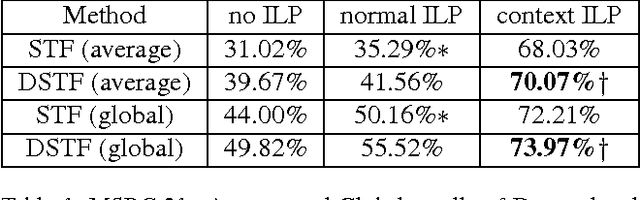
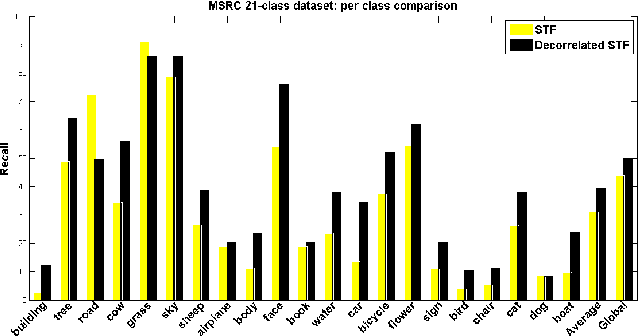
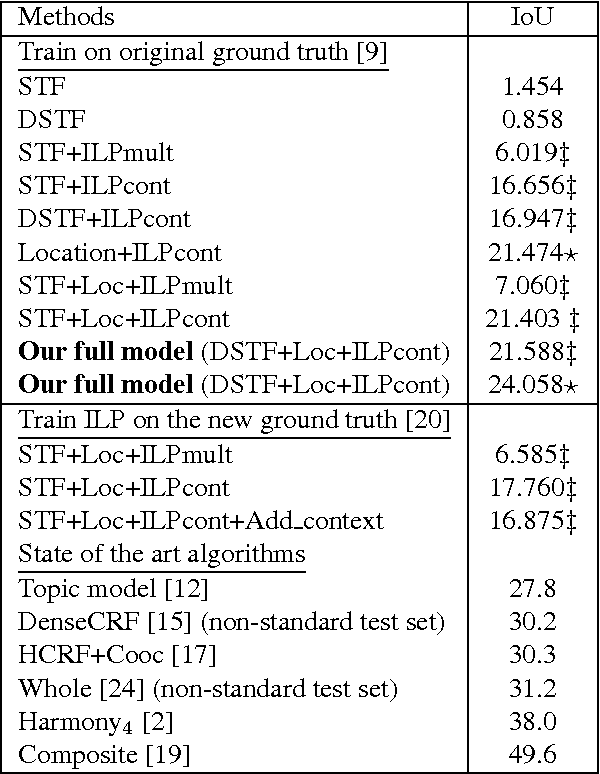
Accurate semantic labeling of image pixels is difficult because intra-class variability is often greater than inter-class variability. In turn, fast semantic segmentation is hard because accurate models are usually too complicated to also run quickly at test-time. Our experience with building and running semantic segmentation systems has also shown a reasonably obvious bottleneck on model complexity, imposed by small training datasets. We therefore propose two simple complementary strategies that leverage context to give better semantic segmentation, while scaling up or down to train on different-sized datasets. As easy modifications for existing semantic segmentation algorithms, we introduce Decorrelated Semantic Texton Forests, and the Context Sensitive Image Level Prior. The proposed modifications are tested using a Semantic Texton Forest (STF) system, and the modifications are validated on two standard benchmark datasets, MSRC-21 and PascalVOC-2010. In Python based comparisons, our system is insignificantly slower than STF at test-time, yet produces superior semantic segmentations overall, with just push-button training.