 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-efficient Deep Reinforcement Learning for Dexterous Manipulation
Apr 10, 2017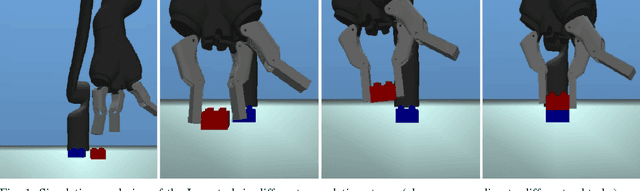
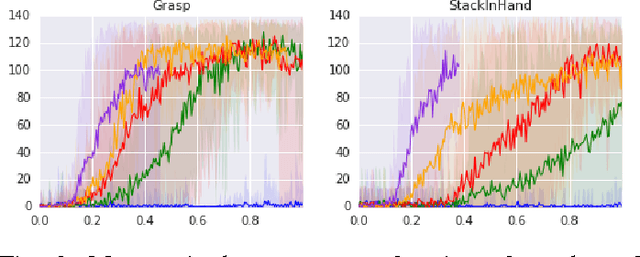
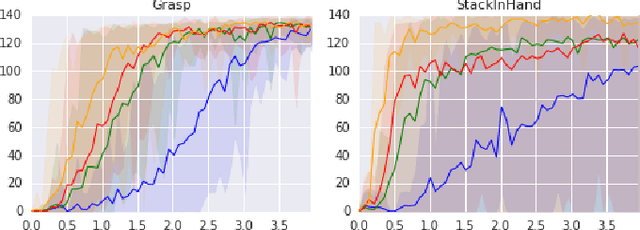
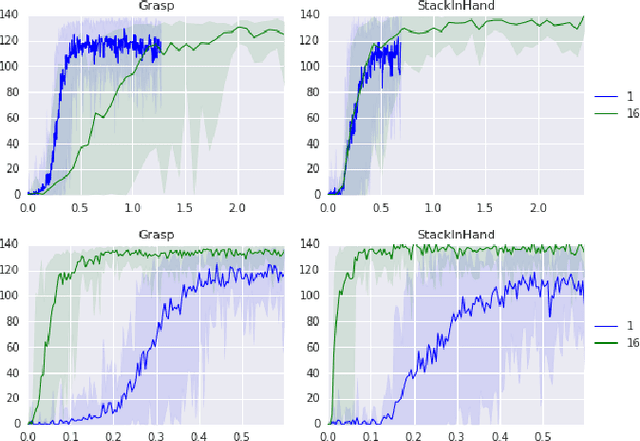
Deep learning and reinforcement learning methods have recently been used to solve a variety of problems in continuous control domains. An obvious application of these techniques is dexterous manipulation tasks in robotics which are difficult to solve using traditional control theory or hand-engineered approaches. One example of such a task is to grasp an object and precisely stack it on another. Solving this difficult and practically relevant problem in the real world is an important long-term goal for the field of robotics. Here we take a step towards this goal by examining the problem in simulation and providing models and techniques aimed at solving it. We introduce two extensions to the Deep Deterministic Policy Gradient algorithm (DDPG), a model-free Q-learning based method, which make it significantly more data-efficient and scalable. Our results show that by making extensive use of off-policy data and replay, it is possible to find control policies that robustly grasp objects and stack them. Further, our results hint that it may soon be feasible to train successful stacking policies by collecting interactions on real robots.