 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQalb: Largest State-of-the-Art Urdu Large Language Model for 230M Speakers with Systematic Continued Pre-training
Jan 13, 2026Despite remarkable progress in large language models, Urdu-a language spoken by over 230 million people-remains critically underrepresented in modern NLP systems. Existing multilingual models demonstrate poor performance on Urdu-specific tasks, struggling with the language's complex morphology, right-to-left Nastaliq script, and rich literary traditions. Even the base LLaMA-3.1 8B-Instruct model shows limited capability in generating fluent, contextually appropriate Urdu text. We introduce Qalb, an Urdu language model developed through a two-stage approach: continued pre-training followed by supervised fine-tuning. Starting from LLaMA 3.1 8B, we perform continued pre-training on a dataset of 1.97 billion tokens. This corpus comprises 1.84 billion tokens of diverse Urdu text-spanning news archives, classical and contemporary literature, government documents, and social media-combined with 140 million tokens of English Wikipedia data to prevent catastrophic forgetting. We then fine-tune the resulting model on the Alif Urdu-instruct dataset. Through extensive evaluation on Urdu-specific benchmarks, Qalb demonstrates substantial improvements, achieving a weighted average score of 90.34 and outperforming the previous state-of-the-art Alif-1.0-Instruct model (87.1) by 3.24 points, while also surpassing the base LLaMA-3.1 8B-Instruct model by 44.64 points. Qalb achieves state-of-the-art performance with comprehensive evaluation across seven diverse tasks including Classification, Sentiment Analysis, and Reasoning. Our results demonstrate that continued pre-training on diverse, high-quality language data, combined with targeted instruction fine-tuning, effectively adapts foundation models to low-resource languages.
Within-basket Recommendation via Neural Pattern Associator
Jan 25, 2024



Within-basket recommendation (WBR) refers to the task of recommending items to the end of completing a non-empty shopping basket during a shopping session. While the latest innovations in this space demonstrate remarkable performance improvement on benchmark datasets, they often overlook the complexity of user behaviors in practice, such as 1) co-existence of multiple shopping intentions, 2) multi-granularity of such intentions, and 3) interleaving behavior (switching intentions) in a shopping session. This paper presents Neural Pattern Associator (NPA), a deep item-association-mining model that explicitly models the aforementioned factors. Specifically, inspired by vector quantization, the NPA model learns to encode common user intentions (or item-combination patterns) as quantized representations (a.k.a. codebook), which permits identification of users's shopping intentions via attention-driven lookup during the reasoning phase. This yields coherent and self-interpretable recommendations. We evaluated the proposed NPA model across multiple extensive datasets, encompassing the domains of grocery e-commerce (shopping basket completion) and music (playlist extension), where our quantitative evaluations show that the NPA model significantly outperforms a wide range of existing WBR solutions, reflecting the benefit of explicitly modeling complex user intentions.
Content-Based Image Retrieval Based on Late Fusion of Binary and Local Descriptors
Mar 24, 2017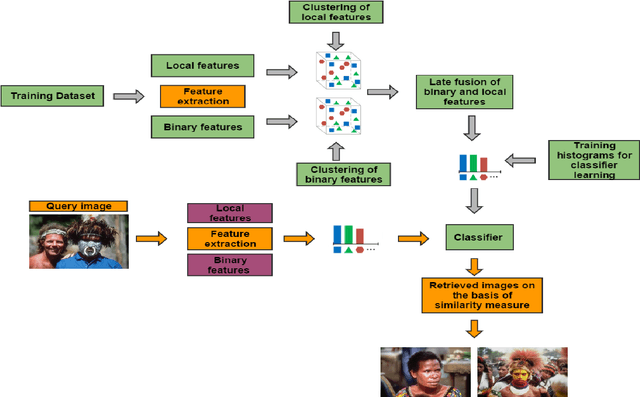

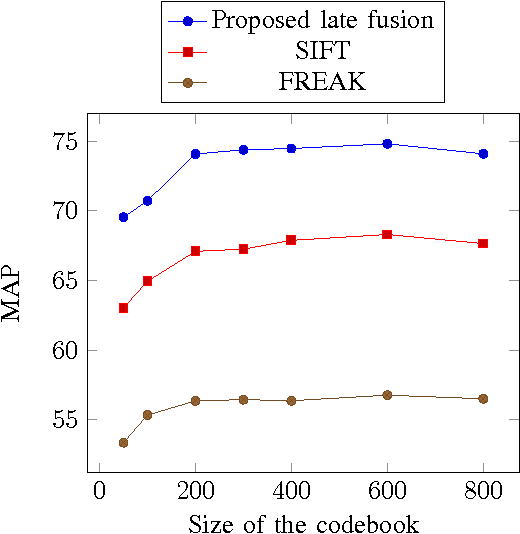

One of the challenges in Content-Based Image Retrieval (CBIR) is to reduce the semantic gaps between low-level features and high-level semantic concepts. In CBIR, the images are represented in the feature space and the performance of CBIR depends on the type of selected feature representation. Late fusion also known as visual words integration is applied to enhance the performance of image retrieval. The recent advances in image retrieval diverted the focus of research towards the use of binary descriptors as they are reported computationally efficient. In this paper, we aim to investigate the late fusion of Fast Retina Keypoint (FREAK) and Scale Invariant Feature Transform (SIFT). The late fusion of binary and local descriptor is selected because among binary descriptors, FREAK has shown good results in classification-based problems while SIFT is robust to translation, scaling, rotation and small distortions. The late fusion of FREAK and SIFT integrates the performance of both feature descriptors for an effective image retrieval. Experimental results and comparisons show that the proposed late fusion enhances the performances of image retrieval.