 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDP-GPL: Differentially Private Graph Prompt Learning
Mar 13, 2025Graph Neural Networks (GNNs) have shown remarkable performance in various applications. Recently, graph prompt learning has emerged as a powerful GNN training paradigm, inspired by advances in language and vision foundation models. Here, a GNN is pre-trained on public data and then adapted to sensitive tasks using lightweight graph prompts. However, using prompts from sensitive data poses privacy risks. In this work, we are the first to investigate these practical risks in graph prompts by instantiating a membership inference attack that reveals significant privacy leakage. We also find that the standard privacy method, DP-SGD, fails to provide practical privacy-utility trade-offs in graph prompt learning, likely due to the small number of sensitive data points used to learn the prompts. As a solution, we propose DP-GPL for differentially private graph prompt learning based on the PATE framework, that generates a graph prompt with differential privacy guarantees. Our evaluation across various graph prompt learning methods, GNN architectures, and pre-training strategies demonstrates that our algorithm achieves high utility at strong privacy, effectively mitigating privacy concerns while preserving the powerful capabilities of prompted GNNs as powerful foundation models in the graph domain.
Controlled privacy leakage propagation throughout overlapping grouped learning
Mar 06, 2025Federated Learning (FL) is the standard protocol for collaborative learning. In FL, multiple workers jointly train a shared model. They exchange model updates calculated on their data, while keeping the raw data itself local. Since workers naturally form groups based on common interests and privacy policies, we are motivated to extend standard FL to reflect a setting with multiple, potentially overlapping groups. In this setup where workers can belong and contribute to more than one group at a time, complexities arise in understanding privacy leakage and in adhering to privacy policies. To address the challenges, we propose differential private overlapping grouped learning (DPOGL), a novel method to implement privacy guarantees within overlapping groups. Under the honest-but-curious threat model, we derive novel privacy guarantees between arbitrary pairs of workers. These privacy guarantees describe and quantify two key effects of privacy leakage in DP-OGL: propagation delay, i.e., the fact that information from one group will leak to other groups only with temporal offset through the common workers and information degradation, i.e., the fact that noise addition over model updates limits information leakage between workers. Our experiments show that applying DP-OGL enhances utility while maintaining strong privacy compared to standard FL setups.
* This paper was presented in part at the 2024 IEEE International Symposium on Information Theory (ISIT), Athens, Greece, 2024, pp. 386-391, doi: 10.1109/ISIT57864.2024.10619521. The paper was published in the IEEE Journal on Selected Areas in Information Theory (JSAIT)
Captured by Captions: On Memorization and its Mitigation in CLIP Models
Feb 11, 2025Multi-modal models, such as CLIP, have demonstrated strong performance in aligning visual and textual representations, excelling in tasks like image retrieval and zero-shot classification. Despite this success, the mechanisms by which these models utilize training data, particularly the role of memorization, remain unclear. In uni-modal models, both supervised and self-supervised, memorization has been shown to be essential for generalization. However, it is not well understood how these findings would apply to CLIP, which incorporates elements from both supervised learning via captions that provide a supervisory signal similar to labels, and from self-supervised learning via the contrastive objective. To bridge this gap in understanding, we propose a formal definition of memorization in CLIP (CLIPMem) and use it to quantify memorization in CLIP models. Our results indicate that CLIP's memorization behavior falls between the supervised and self-supervised paradigms, with "mis-captioned" samples exhibiting highest levels of memorization. Additionally, we find that the text encoder contributes more to memorization than the image encoder, suggesting that mitigation strategies should focus on the text domain. Building on these insights, we propose multiple strategies to reduce memorization while at the same time improving utility--something that had not been shown before for traditional learning paradigms where reducing memorization typically results in utility decrease.
Beautiful Images, Toxic Words: Understanding and Addressing Offensive Text in Generated Images
Feb 10, 2025State-of-the-art visual generation models, such as Diffusion Models (DMs) and Vision Auto-Regressive Models (VARs), produce highly realistic images. While prior work has successfully mitigated Not Safe For Work (NSFW) content in the visual domain, we identify a novel threat: the generation of NSFW text embedded within images. This includes offensive language, such as insults, racial slurs, and sexually explicit terms, posing significant risks to users. We show that all state-of-the-art DMs (e.g., SD3, Flux, DeepFloyd IF) and VARs (e.g., Infinity) are vulnerable to this issue. Through extensive experiments, we demonstrate that existing mitigation techniques, effective for visual content, fail to prevent harmful text generation while substantially degrading benign text generation. As an initial step toward addressing this threat, we explore safety fine-tuning of the text encoder underlying major DM architectures using a customized dataset. Thereby, we suppress NSFW generation while preserving overall image and text generation quality. Finally, to advance research in this area, we introduce ToxicBench, an open-source benchmark for evaluating NSFW text generation in images. ToxicBench provides a curated dataset of harmful prompts, new metrics, and an evaluation pipeline assessing both NSFW-ness and generation quality. Our benchmark aims to guide future efforts in mitigating NSFW text generation in text-to-image models.
Privacy Attacks on Image AutoRegressive Models
Feb 04, 2025



Image autoregressive (IAR) models have surpassed diffusion models (DMs) in both image quality (FID: 1.48 vs. 1.58) and generation speed. However, their privacy risks remain largely unexplored. To address this, we conduct a comprehensive privacy analysis comparing IARs to DMs. We develop a novel membership inference attack (MIA) that achieves a significantly higher success rate in detecting training images (TPR@FPR=1%: 86.38% for IARs vs. 4.91% for DMs). Using this MIA, we perform dataset inference (DI) and find that IARs require as few as six samples to detect dataset membership, compared to 200 for DMs, indicating higher information leakage. Additionally, we extract hundreds of training images from an IAR (e.g., 698 from VAR-d30). Our findings highlight a fundamental privacy-utility trade-off: while IARs excel in generation quality and speed, they are significantly more vulnerable to privacy attacks. This suggests that incorporating techniques from DMs, such as per-token probability modeling using diffusion, could help mitigate IARs' privacy risks. Our code is available at https://github.com/sprintml/privacy_attacks_against_iars.
CDI: Copyrighted Data Identification in Diffusion Models
Nov 19, 2024



Diffusion Models (DMs) benefit from large and diverse datasets for their training. Since this data is often scraped from the Internet without permission from the data owners, this raises concerns about copyright and intellectual property protections. While (illicit) use of data is easily detected for training samples perfectly re-created by a DM at inference time, it is much harder for data owners to verify if their data was used for training when the outputs from the suspect DM are not close replicas. Conceptually, membership inference attacks (MIAs), which detect if a given data point was used during training, present themselves as a suitable tool to address this challenge. However, we demonstrate that existing MIAs are not strong enough to reliably determine the membership of individual images in large, state-of-the-art DMs. To overcome this limitation, we propose CDI, a framework for data owners to identify whether their dataset was used to train a given DM. CDI relies on dataset inference techniques, i.e., instead of using the membership signal from a single data point, CDI leverages the fact that most data owners, such as providers of stock photography, visual media companies, or even individual artists, own datasets with multiple publicly exposed data points which might all be included in the training of a given DM. By selectively aggregating signals from existing MIAs and using new handcrafted methods to extract features for these datasets, feeding them to a scoring model, and applying rigorous statistical testing, CDI allows data owners with as little as 70 data points to identify with a confidence of more than 99% whether their data was used to train a given DM. Thereby, CDI represents a valuable tool for data owners to claim illegitimate use of their copyrighted data.
On the Privacy Risk of In-context Learning
Nov 15, 2024



Large language models (LLMs) are excellent few-shot learners. They can perform a wide variety of tasks purely based on natural language prompts provided to them. These prompts contain data of a specific downstream task -- often the private dataset of a party, e.g., a company that wants to leverage the LLM for their purposes. We show that deploying prompted models presents a significant privacy risk for the data used within the prompt by instantiating a highly effective membership inference attack. We also observe that the privacy risk of prompted models exceeds fine-tuned models at the same utility levels. After identifying the model's sensitivity to their prompts -- in the form of a significantly higher prediction confidence on the prompted data -- as a cause for the increased risk, we propose ensembling as a mitigation strategy. By aggregating over multiple different versions of a prompted model, membership inference risk can be decreased.
Localizing Memorization in SSL Vision Encoders
Sep 27, 2024



Recent work on studying memorization in self-supervised learning (SSL) suggests that even though SSL encoders are trained on millions of images, they still memorize individual data points. While effort has been put into characterizing the memorized data and linking encoder memorization to downstream utility, little is known about where the memorization happens inside SSL encoders. To close this gap, we propose two metrics for localizing memorization in SSL encoders on a per-layer (layermem) and per-unit basis (unitmem). Our localization methods are independent of the downstream task, do not require any label information, and can be performed in a forward pass. By localizing memorization in various encoder architectures (convolutional and transformer-based) trained on diverse datasets with contrastive and non-contrastive SSL frameworks, we find that (1) while SSL memorization increases with layer depth, highly memorizing units are distributed across the entire encoder, (2) a significant fraction of units in SSL encoders experiences surprisingly high memorization of individual data points, which is in contrast to models trained under supervision, (3) atypical (or outlier) data points cause much higher layer and unit memorization than standard data points, and (4) in vision transformers, most memorization happens in the fully-connected layers. Finally, we show that localizing memorization in SSL has the potential to improve fine-tuning and to inform pruning strategies.
Benchmarking Robust Self-Supervised Learning Across Diverse Downstream Tasks
Jul 18, 2024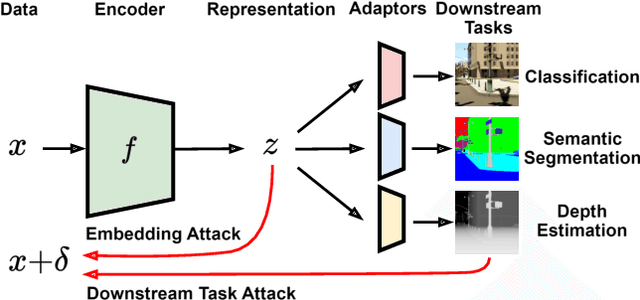
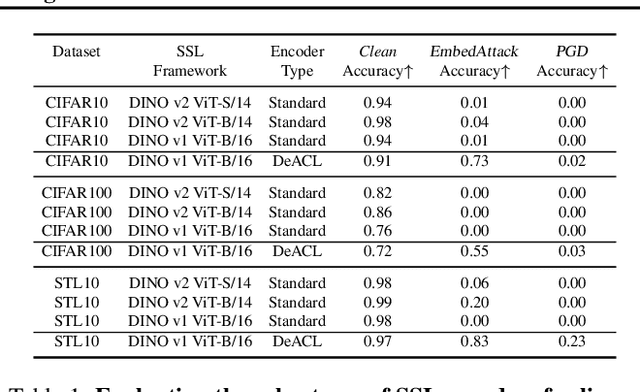
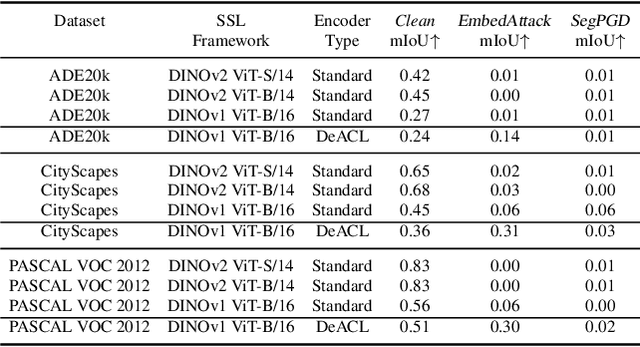
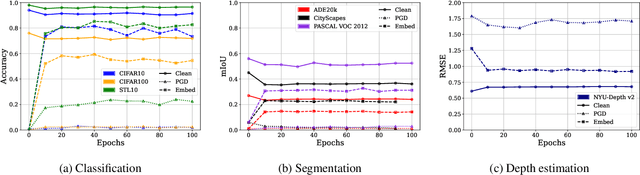
Large-scale vision models have become integral in many applications due to their unprecedented performance and versatility across downstream tasks. However, the robustness of these foundation models has primarily been explored for a single task, namely image classification. The vulnerability of other common vision tasks, such as semantic segmentation and depth estimation, remains largely unknown. We present a comprehensive empirical evaluation of the adversarial robustness of self-supervised vision encoders across multiple downstream tasks. Our attacks operate in the encoder embedding space and at the downstream task output level. In both cases, current state-of-the-art adversarial fine-tuning techniques tested only for classification significantly degrade clean and robust performance on other tasks. Since the purpose of a foundation model is to cater to multiple applications at once, our findings reveal the need to enhance encoder robustness more broadly. Our code is available at ${github.com/layer6ai-labs/ssl-robustness}$.
Beyond the Mean: Differentially Private Prototypes for Private Transfer Learning
Jun 12, 2024Machine learning (ML) models have been shown to leak private information from their training datasets. Differential Privacy (DP), typically implemented through the differential private stochastic gradient descent algorithm (DP-SGD), has become the standard solution to bound leakage from the models. Despite recent improvements, DP-SGD-based approaches for private learning still usually struggle in the high privacy ($\varepsilon\le1)$ and low data regimes, and when the private training datasets are imbalanced. To overcome these limitations, we propose Differentially Private Prototype Learning (DPPL) as a new paradigm for private transfer learning. DPPL leverages publicly pre-trained encoders to extract features from private data and generates DP prototypes that represent each private class in the embedding space and can be publicly released for inference. Since our DP prototypes can be obtained from only a few private training data points and without iterative noise addition, they offer high-utility predictions and strong privacy guarantees even under the notion of pure DP. We additionally show that privacy-utility trade-offs can be further improved when leveraging the public data beyond pre-training of the encoder: in particular, we can privately sample our DP prototypes from the publicly available data points used to train the encoder. Our experimental evaluation with four state-of-the-art encoders, four vision datasets, and under different data and imbalancedness regimes demonstrate DPPL's high performance under strong privacy guarantees in challenging private learning setups.