 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePED-ANOVA: Efficiently Quantifying Hyperparameter Importance in Arbitrary Subspaces
Apr 20, 2023The recent rise in popularity of Hyperparameter Optimization (HPO) for deep learning has highlighted the role that good hyperparameter (HP) space design can play in training strong models. In turn, designing a good HP space is critically dependent on understanding the role of different HPs. This motivates research on HP Importance (HPI), e.g., with the popular method of functional ANOVA (f-ANOVA). However, the original f-ANOVA formulation is inapplicable to the subspaces most relevant to algorithm designers, such as those defined by top performance. To overcome this problem, we derive a novel formulation of f-ANOVA for arbitrary subspaces and propose an algorithm that uses Pearson divergence (PED) to enable a closed-form computation of HPI. We demonstrate that this new algorithm, dubbed PED-ANOVA, is able to successfully identify important HPs in different subspaces while also being extremely computationally efficient.
Can Fairness be Automated? Guidelines and Opportunities for Fairness-aware AutoML
Mar 15, 2023


The field of automated machine learning (AutoML) introduces techniques that automate parts of the development of machine learning (ML) systems, accelerating the process and reducing barriers for novices. However, decisions derived from ML models can reproduce, amplify, or even introduce unfairness in our societies, causing harm to (groups of) individuals. In response, researchers have started to propose AutoML systems that jointly optimize fairness and predictive performance to mitigate fairness-related harm. However, fairness is a complex and inherently interdisciplinary subject, and solely posing it as an optimization problem can have adverse side effects. With this work, we aim to raise awareness among developers of AutoML systems about such limitations of fairness-aware AutoML, while also calling attention to the potential of AutoML as a tool for fairness research. We present a comprehensive overview of different ways in which fairness-related harm can arise and the ensuing implications for the design of fairness-aware AutoML. We conclude that while fairness cannot be automated, fairness-aware AutoML can play an important role in the toolbox of an ML practitioner. We highlight several open technical challenges for future work in this direction. Additionally, we advocate for the creation of more user-centered assistive systems designed to tackle challenges encountered in fairness work.
Neural Architecture Search: Insights from 1000 Papers
Jan 25, 2023



In the past decade, advances in deep learning have resulted in breakthroughs in a variety of areas, including computer vision, natural language understanding, speech recognition, and reinforcement learning. Specialized, high-performing neural architectures are crucial to the success of deep learning in these areas. Neural architecture search (NAS), the process of automating the design of neural architectures for a given task, is an inevitable next step in automating machine learning and has already outpaced the best human-designed architectures on many tasks. In the past few years, research in NAS has been progressing rapidly, with over 1000 papers released since 2020 (Deng and Lindauer, 2021). In this survey, we provide an organized and comprehensive guide to neural architecture search. We give a taxonomy of search spaces, algorithms, and speedup techniques, and we discuss resources such as benchmarks, best practices, other surveys, and open-source libraries.
Multi-objective Tree-structured Parzen Estimator Meets Meta-learning
Dec 13, 2022Hyperparameter optimization (HPO) is essential for the better performance of deep learning, and practitioners often need to consider the trade-off between multiple metrics, such as error rate, latency, memory requirements, robustness, and algorithmic fairness. Due to this demand and the heavy computation of deep learning, the acceleration of multi-objective (MO) optimization becomes ever more important. Although meta-learning has been extensively studied to speedup HPO, existing methods are not applicable to the MO tree-structured parzen estimator (MO-TPE), a simple yet powerful MO-HPO algorithm. In this paper, we extend TPE's acquisition function to the meta-learning setting, using a task similarity defined by the overlap in promising domains of each task. In a comprehensive set of experiments, we demonstrate that our method accelerates MO-TPE on tabular HPO benchmarks and yields state-of-the-art performance. Our method was also validated externally by winning the AutoML 2022 competition on "Multiobjective Hyperparameter Optimization for Transformers".
Mind the Gap: Measuring Generalization Performance Across Multiple Objectives
Dec 08, 2022



Modern machine learning models are often constructed taking into account multiple objectives, e.g., to minimize inference time while also maximizing accuracy. Multi-objective hyperparameter optimization (MHPO) algorithms return such candidate models and the approximation of the Pareto front is used to assess their performance. However, when estimating generalization performance of an approximation of a Pareto front found on a validation set by computing the performance of the individual models on the test set, models might no longer be Pareto-optimal. This makes it unclear how to measure performance. To resolve this, we provide a novel evaluation protocol that allows measuring the generalization performance of MHPO methods and to study its capabilities for comparing two optimization experiments.
c-TPE: Generalizing Tree-structured Parzen Estimator with Inequality Constraints for Continuous and Categorical Hyperparameter Optimization
Nov 26, 2022



Hyperparameter optimization (HPO) is crucial for strong performance of deep learning algorithms. A widely-used versatile HPO method is a variant of Bayesian optimization called tree-structured Parzen estimator (TPE), which splits data into good and bad groups and uses the density ratio of those groups as an acquisition function (AF). However, real-world applications often have some constraints, such as memory requirements, or latency. In this paper, we present an extension of TPE to constrained optimization (c-TPE) via simple factorization of AFs. The experiments demonstrate c-TPE is robust to various constraint levels and exhibits the best average rank performance among existing methods with statistical significance on search spaces with categorical parameters on 81 settings.
Towards Discovering Neural Architectures from Scratch
Nov 03, 2022



The discovery of neural architectures from scratch is the long-standing goal of Neural Architecture Search (NAS). Searching over a wide spectrum of neural architectures can facilitate the discovery of previously unconsidered but well-performing architectures. In this work, we take a large step towards discovering neural architectures from scratch by expressing architectures algebraically. This algebraic view leads to a more general method for designing search spaces, which allows us to compactly represent search spaces that are 100s of orders of magnitude larger than common spaces from the literature. Further, we propose a Bayesian Optimization strategy to efficiently search over such huge spaces, and demonstrate empirically that both our search space design and our search strategy can be superior to existing baselines. We open source our algebraic NAS approach and provide APIs for PyTorch and TensorFlow.
On the Importance of Architectures and Hyperparameters for Fairness in Face Recognition
Oct 18, 2022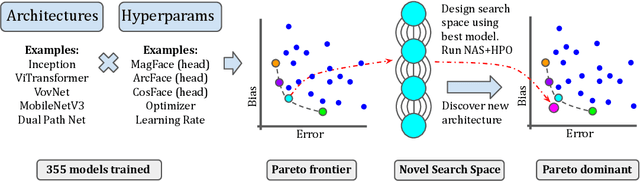

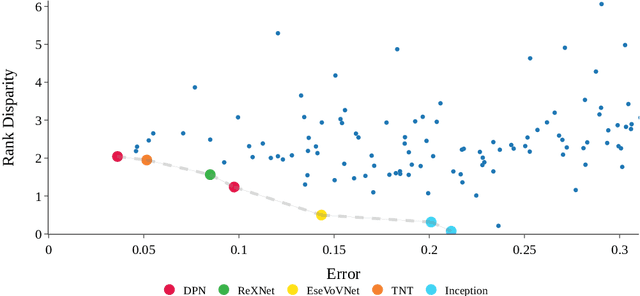

Face recognition systems are deployed across the world by government agencies and contractors for sensitive and impactful tasks, such as surveillance and database matching. Despite their widespread use, these systems are known to exhibit bias across a range of sociodemographic dimensions, such as gender and race. Nonetheless, an array of works proposing pre-processing, training, and post-processing methods have failed to close these gaps. Here, we take a very different approach to this problem, identifying that both architectures and hyperparameters of neural networks are instrumental in reducing bias. We first run a large-scale analysis of the impact of architectures and training hyperparameters on several common fairness metrics and show that the implicit convention of choosing high-accuracy architectures may be suboptimal for fairness. Motivated by our findings, we run the first neural architecture search for fairness, jointly with a search for hyperparameters. We output a suite of models which Pareto-dominate all other competitive architectures in terms of accuracy and fairness. Furthermore, we show that these models transfer well to other face recognition datasets with similar and distinct protected attributes. We release our code and raw result files so that researchers and practitioners can replace our fairness metrics with a bias measure of their choice.
NAS-Bench-Suite-Zero: Accelerating Research on Zero Cost Proxies
Oct 06, 2022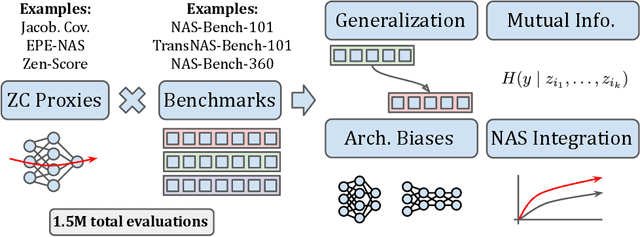
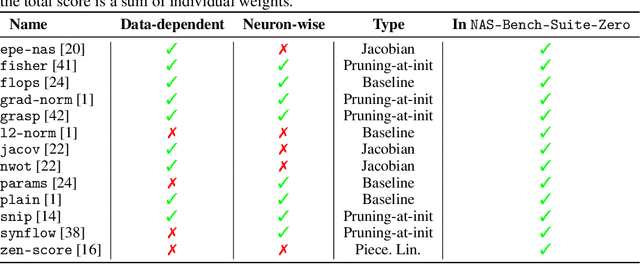
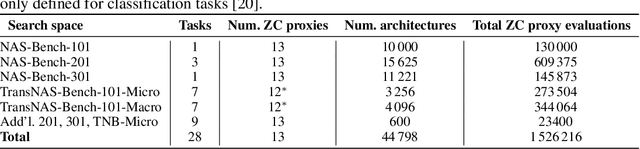
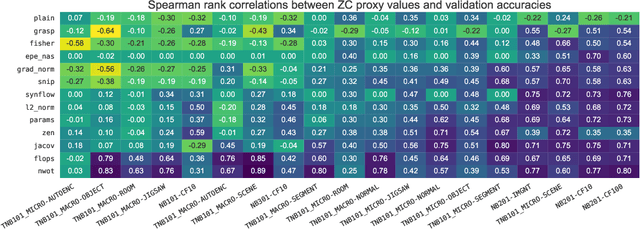
Zero-cost proxies (ZC proxies) are a recent architecture performance prediction technique aiming to significantly speed up algorithms for neural architecture search (NAS). Recent work has shown that these techniques show great promise, but certain aspects, such as evaluating and exploiting their complementary strengths, are under-studied. In this work, we create NAS-Bench-Suite: we evaluate 13 ZC proxies across 28 tasks, creating by far the largest dataset (and unified codebase) for ZC proxies, enabling orders-of-magnitude faster experiments on ZC proxies, while avoiding confounding factors stemming from different implementations. To demonstrate the usefulness of NAS-Bench-Suite, we run a large-scale analysis of ZC proxies, including a bias analysis, and the first information-theoretic analysis which concludes that ZC proxies capture substantial complementary information. Motivated by these findings, we present a procedure to improve the performance of ZC proxies by reducing biases such as cell size, and we also show that incorporating all 13 ZC proxies into the surrogate models used by NAS algorithms can improve their predictive performance by up to 42%. Our code and datasets are available at https://github.com/automl/naslib/tree/zerocost.
T3VIP: Transformation-based 3D Video Prediction
Sep 19, 2022
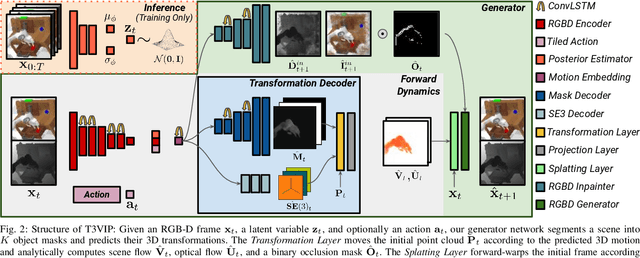
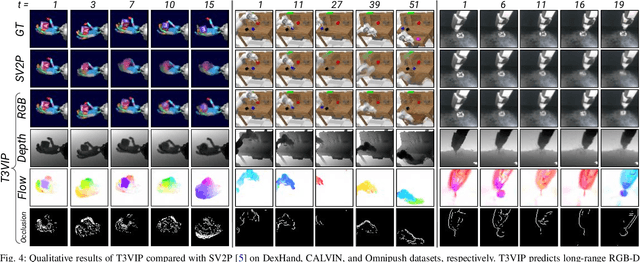
For autonomous skill acquisition, robots have to learn about the physical rules governing the 3D world dynamics from their own past experience to predict and reason about plausible future outcomes. To this end, we propose a transformation-based 3D video prediction (T3VIP) approach that explicitly models the 3D motion by decomposing a scene into its object parts and predicting their corresponding rigid transformations. Our model is fully unsupervised, captures the stochastic nature of the real world, and the observational cues in image and point cloud domains constitute its learning signals. To fully leverage all the 2D and 3D observational signals, we equip our model with automatic hyperparameter optimization (HPO) to interpret the best way of learning from them. To the best of our knowledge, our model is the first generative model that provides an RGB-D video prediction of the future for a static camera. Our extensive evaluation with simulated and real-world datasets demonstrates that our formulation leads to interpretable 3D models that predict future depth videos while achieving on-par performance with 2D models on RGB video prediction. Moreover, we demonstrate that our model outperforms 2D baselines on visuomotor control. Videos, code, dataset, and pre-trained models are available at http://t3vip.cs.uni-freiburg.de.