 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic Data in Human Analysis: A Survey
Aug 19, 2022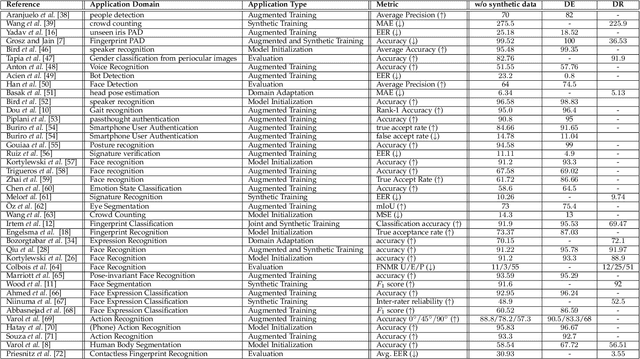



Deep neural networks have become prevalent in human analysis, boosting the performance of applications, such as biometric recognition, action recognition, as well as person re-identification. However, the performance of such networks scales with the available training data. In human analysis, the demand for large-scale datasets poses a severe challenge, as data collection is tedious, time-expensive, costly and must comply with data protection laws. Current research investigates the generation of \textit{synthetic data} as an efficient and privacy-ensuring alternative to collecting real data in the field. This survey introduces the basic definitions and methodologies, essential when generating and employing synthetic data for human analysis. We conduct a survey that summarises current state-of-the-art methods and the main benefits of using synthetic data. We also provide an overview of publicly available synthetic datasets and generation models. Finally, we discuss limitations, as well as open research problems in this field. This survey is intended for researchers and practitioners in the field of human analysis.
THORN: Temporal Human-Object Relation Network for Action Recognition
Apr 20, 2022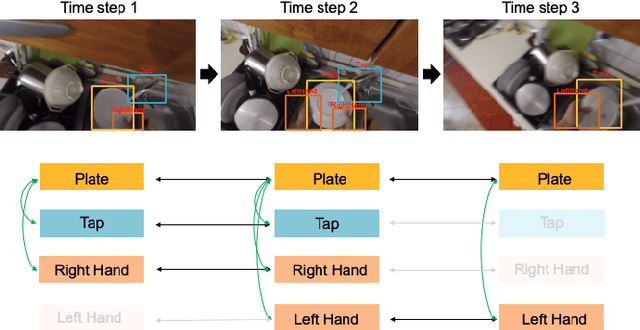
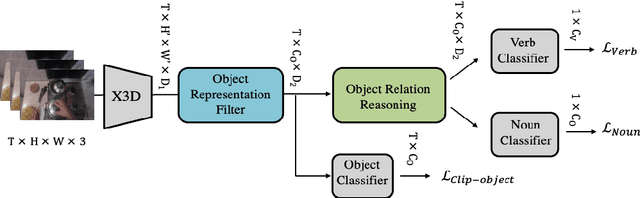
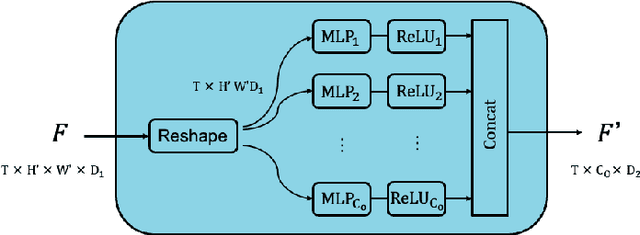
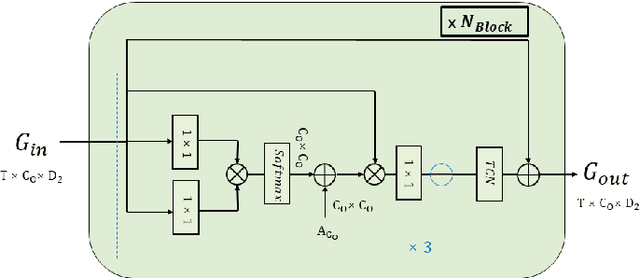
Most action recognition models treat human activities as unitary events. However, human activities often follow a certain hierarchy. In fact, many human activities are compositional. Also, these actions are mostly human-object interactions. In this paper we propose to recognize human action by leveraging the set of interactions that define an action. In this work, we present an end-to-end network: THORN, that can leverage important human-object and object-object interactions to predict actions. This model is built on top of a 3D backbone network. The key components of our model are: 1) An object representation filter for modeling object. 2) An object relation reasoning module to capture object relations. 3) A classification layer to predict the action labels. To show the robustness of THORN, we evaluate it on EPIC-Kitchen55 and EGTEA Gaze+, two of the largest and most challenging first-person and human-object interaction datasets. THORN achieves state-of-the-art performance on both datasets.
Latent Image Animator: Learning to Animate Images via Latent Space Navigation
Mar 17, 2022

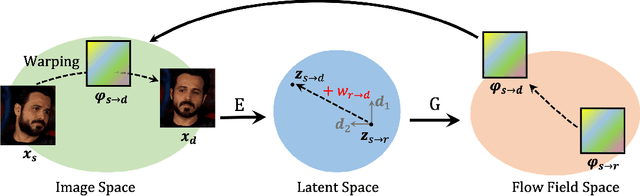
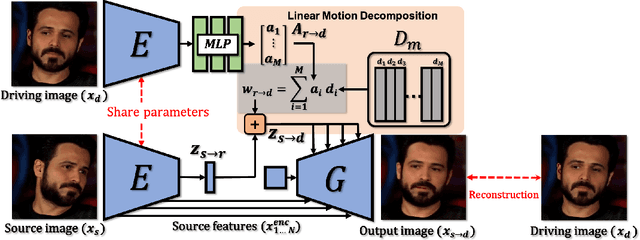
Due to the remarkable progress of deep generative models, animating images has become increasingly efficient, whereas associated results have become increasingly realistic. Current animation-approaches commonly exploit structure representation extracted from driving videos. Such structure representation is instrumental in transferring motion from driving videos to still images. However, such approaches fail in case the source image and driving video encompass large appearance variation. Moreover, the extraction of structure information requires additional modules that endow the animation-model with increased complexity. Deviating from such models, we here introduce the Latent Image Animator (LIA), a self-supervised autoencoder that evades need for structure representation. LIA is streamlined to animate images by linear navigation in the latent space. Specifically, motion in generated video is constructed by linear displacement of codes in the latent space. Towards this, we learn a set of orthogonal motion directions simultaneously, and use their linear combination, in order to represent any displacement in the latent space. Extensive quantitative and qualitative analysis suggests that our model systematically and significantly outperforms state-of-art methods on VoxCeleb, Taichi and TED-talk datasets w.r.t. generated quality.
Unsupervised Lifelong Person Re-identification via Contrastive Rehearsal
Mar 12, 2022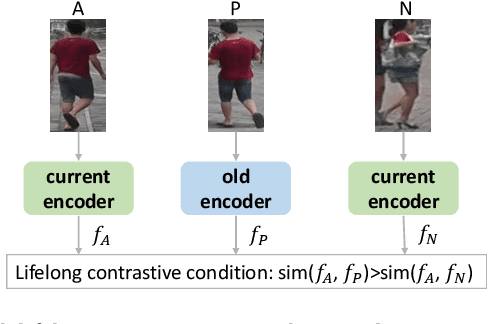
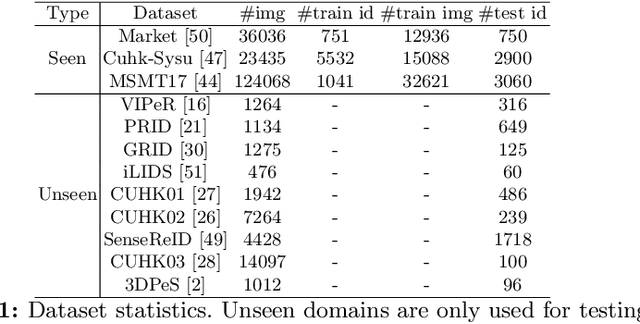
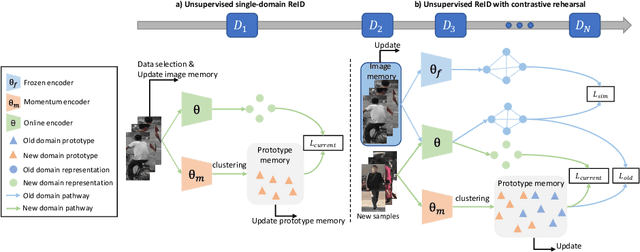
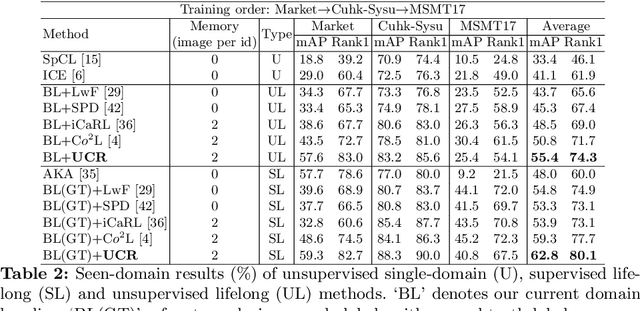
Existing unsupervised person re-identification (ReID) methods focus on adapting a model trained on a source domain to a fixed target domain. However, an adapted ReID model usually only works well on a certain target domain, but can hardly memorize the source domain knowledge and generalize to upcoming unseen data. In this paper, we propose unsupervised lifelong person ReID, which focuses on continuously conducting unsupervised domain adaptation on new domains without forgetting the knowledge learnt from old domains. To tackle unsupervised lifelong ReID, we conduct a contrastive rehearsal on a small number of stored old samples while sequentially adapting to new domains. We further set an image-to-image similarity constraint between old and new models to regularize the model updates in a way that suits old knowledge. We sequentially train our model on several large-scale datasets in an unsupervised manner and test it on all seen domains as well as several unseen domains to validate the generalizability of our method. Our proposed unsupervised lifelong method achieves strong generalizability, which significantly outperforms previous lifelong methods on both seen and unseen domains. Code will be made available at https://github.com/chenhao2345/UCR.
Multimodal Personality Recognition using Cross-Attention Transformer and Behaviour Encoding
Dec 22, 2021
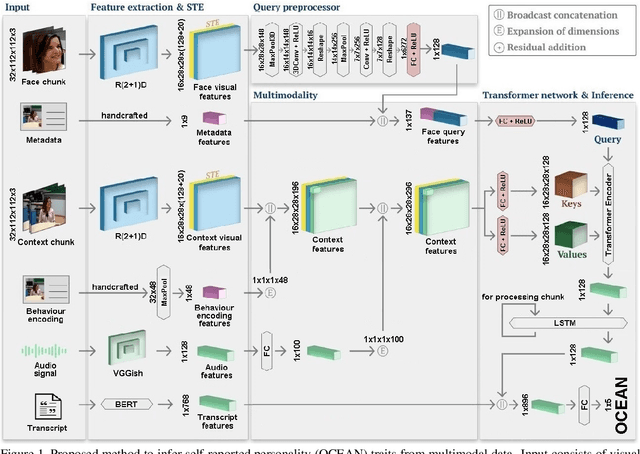
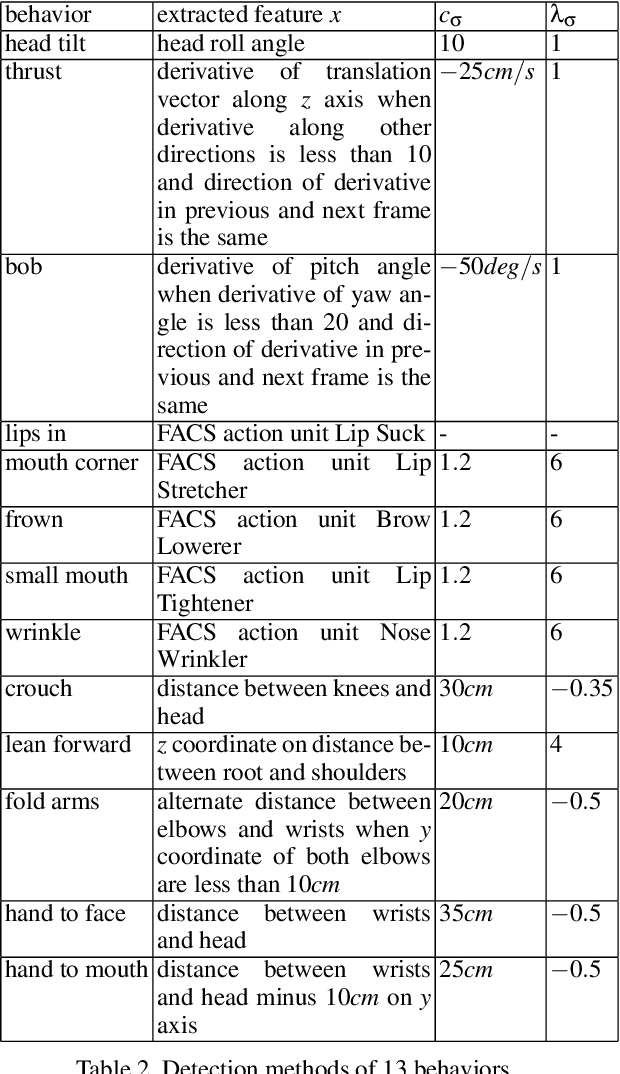
Personality computing and affective computing have gained recent interest in many research areas. The datasets for the task generally have multiple modalities like video, audio, language and bio-signals. In this paper, we propose a flexible model for the task which exploits all available data. The task involves complex relations and to avoid using a large model for video processing specifically, we propose the use of behaviour encoding which boosts performance with minimal change to the model. Cross-attention using transformers has become popular in recent times and is utilised for fusion of different modalities. Since long term relations may exist, breaking the input into chunks is not desirable, thus the proposed model processes the entire input together. Our experiments show the importance of each of the above contributions
MS-TCT: Multi-Scale Temporal ConvTransformer for Action Detection
Dec 07, 2021
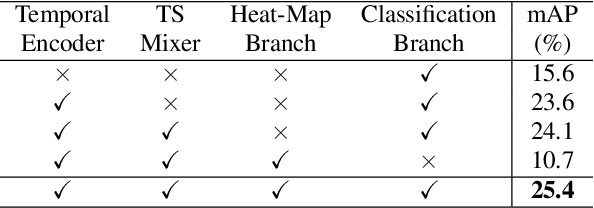
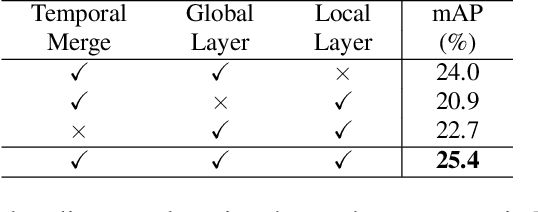
Action detection is an essential and challenging task, especially for densely labelled datasets of untrimmed videos. The temporal relation is complex in those datasets, including challenges like composite action, and co-occurring action. For detecting actions in those complex videos, efficiently capturing both short-term and long-term temporal information in the video is critical. To this end, we propose a novel ConvTransformer network for action detection. This network comprises three main components: (1) Temporal Encoder module extensively explores global and local temporal relations at multiple temporal resolutions. (2) Temporal Scale Mixer module effectively fuses the multi-scale features to have a unified feature representation. (3) Classification module is used to learn the instance center-relative position and predict the frame-level classification scores. The extensive experiments on multiple datasets, including Charades, TSU and MultiTHUMOS, confirm the effectiveness of our proposed method. Our network outperforms the state-of-the-art methods on all three datasets.
CTRN: Class-Temporal Relational Network for Action Detection
Oct 26, 2021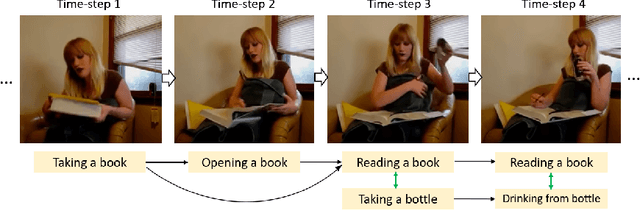
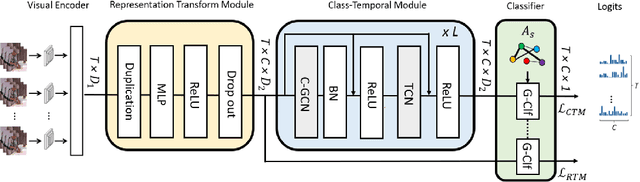

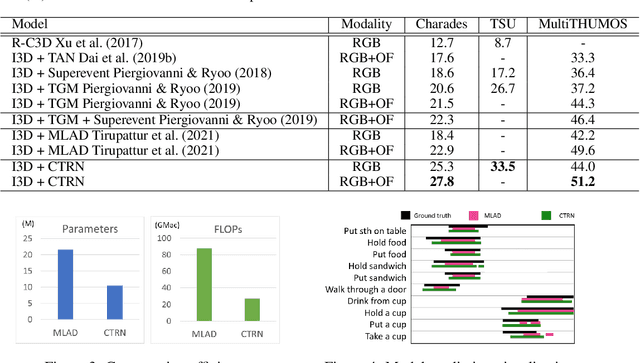
Action detection is an essential and challenging task, especially for densely labelled datasets of untrimmed videos. There are many real-world challenges in those datasets, such as composite action, co-occurring action, and high temporal variation of instance duration. For handling these challenges, we propose to explore both the class and temporal relations of detected actions. In this work, we introduce an end-to-end network: Class-Temporal Relational Network (CTRN). It contains three key components: (1) The Representation Transform Module filters the class-specific features from the mixed representations to build graph-structured data. (2) The Class-Temporal Module models the class and temporal relations in a sequential manner. (3) G-classifier leverages the privileged knowledge of the snippet-wise co-occurring action pairs to further improve the co-occurring action detection. We evaluate CTRN on three challenging densely labelled datasets and achieve state-of-the-art performance, reflecting the effectiveness and robustness of our method.
Weakly-supervised Joint Anomaly Detection and Classification
Aug 20, 2021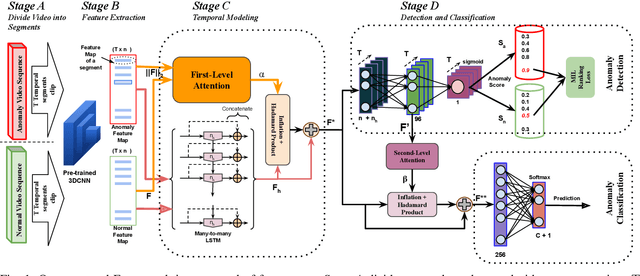
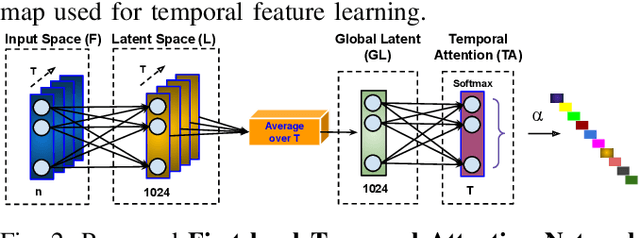
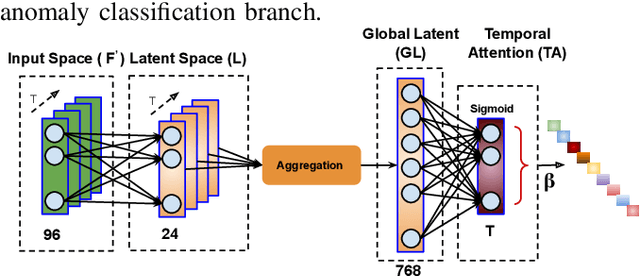

Anomaly activities such as robbery, explosion, accidents, etc. need immediate actions for preventing loss of human life and property in real world surveillance systems. Although the recent automation in surveillance systems are capable of detecting the anomalies, but they still need human efforts for categorizing the anomalies and taking necessary preventive actions. This is due to the lack of methodology performing both anomaly detection and classification for real world scenarios. Thinking of a fully automatized surveillance system, which is capable of both detecting and classifying the anomalies that need immediate actions, a joint anomaly detection and classification method is a pressing need. The task of joint detection and classification of anomalies becomes challenging due to the unavailability of dense annotated videos pertaining to anomalous classes, which is a crucial factor for training modern deep architecture. Furthermore, doing it through manual human effort seems impossible. Thus, we propose a method that jointly handles the anomaly detection and classification in a single framework by adopting a weakly-supervised learning paradigm. In weakly-supervised learning instead of dense temporal annotations, only video-level labels are sufficient for learning. The proposed model is validated on a large-scale publicly available UCF-Crime dataset, achieving state-of-the-art results.
Learning an Augmented RGB Representation with Cross-Modal Knowledge Distillation for Action Detection
Aug 08, 2021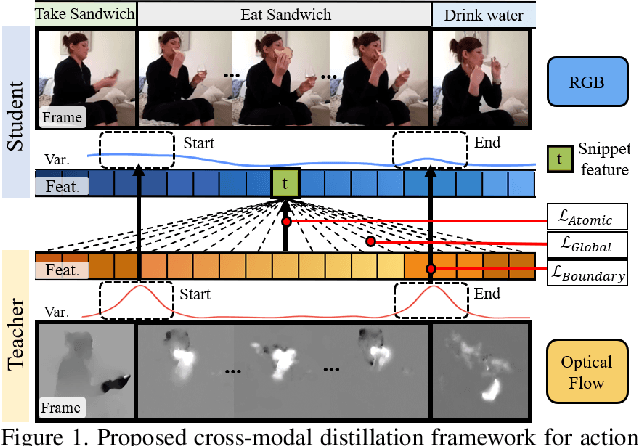
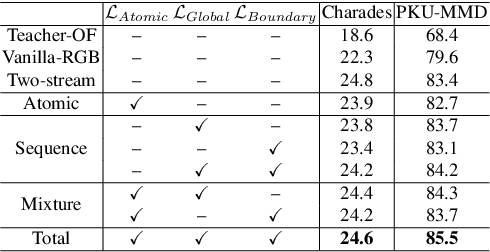
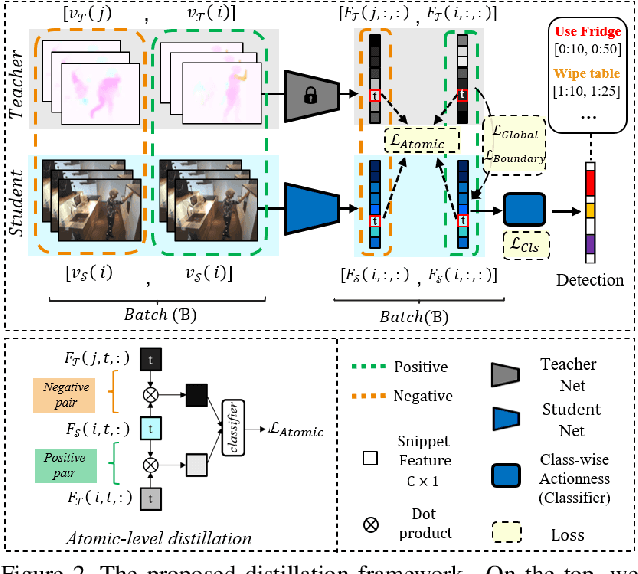

In video understanding, most cross-modal knowledge distillation (KD) methods are tailored for classification tasks, focusing on the discriminative representation of the trimmed videos. However, action detection requires not only categorizing actions, but also localizing them in untrimmed videos. Therefore, transferring knowledge pertaining to temporal relations is critical for this task which is missing in the previous cross-modal KD frameworks. To this end, we aim at learning an augmented RGB representation for action detection, taking advantage of additional modalities at training time through KD. We propose a KD framework consisting of two levels of distillation. On one hand, atomic-level distillation encourages the RGB student to learn the sub-representation of the actions from the teacher in a contrastive manner. On the other hand, sequence-level distillation encourages the student to learn the temporal knowledge from the teacher, which consists of transferring the Global Contextual Relations and the Action Boundary Saliency. The result is an Augmented-RGB stream that can achieve competitive performance as the two-stream network while using only RGB at inference time. Extensive experimental analysis shows that our proposed distillation framework is generic and outperforms other popular cross-modal distillation methods in action detection task.
UNIK: A Unified Framework for Real-world Skeleton-based Action Recognition
Jul 19, 2021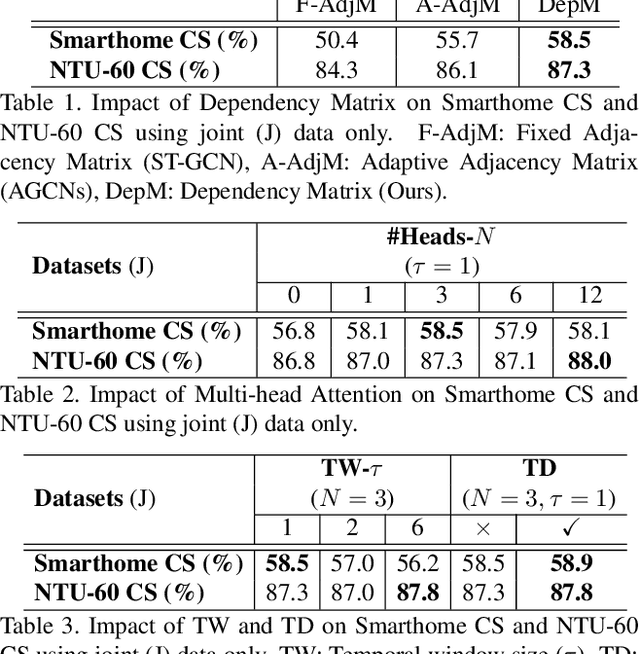
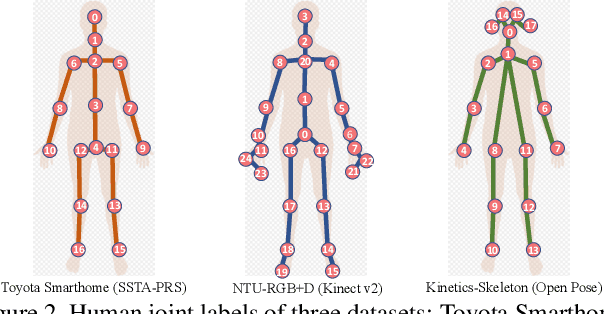
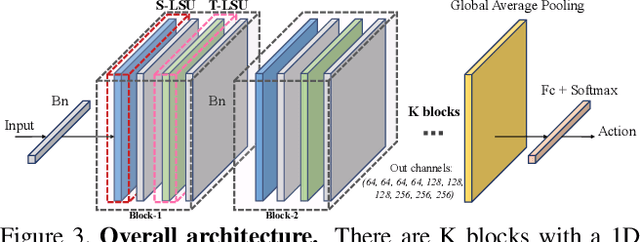
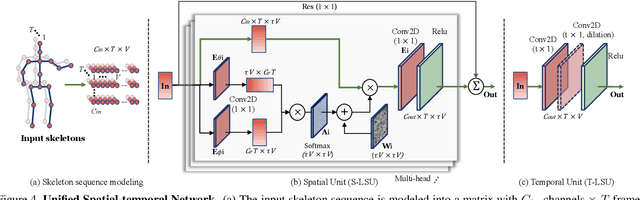
Action recognition based on skeleton data has recently witnessed increasing attention and progress. State-of-the-art approaches adopting Graph Convolutional networks (GCNs) can effectively extract features on human skeletons relying on the pre-defined human topology. Despite associated progress, GCN-based methods have difficulties to generalize across domains, especially with different human topological structures. In this context, we introduce UNIK, a novel skeleton-based action recognition method that is not only effective to learn spatio-temporal features on human skeleton sequences but also able to generalize across datasets. This is achieved by learning an optimal dependency matrix from the uniform distribution based on a multi-head attention mechanism. Subsequently, to study the cross-domain generalizability of skeleton-based action recognition in real-world videos, we re-evaluate state-of-the-art approaches as well as the proposed UNIK in light of a novel Posetics dataset. This dataset is created from Kinetics-400 videos by estimating, refining and filtering poses. We provide an analysis on how much performance improves on smaller benchmark datasets after pre-training on Posetics for the action classification task. Experimental results show that the proposed UNIK, with pre-training on Posetics, generalizes well and outperforms state-of-the-art when transferred onto four target action classification datasets: Toyota Smarthome, Penn Action, NTU-RGB+D 60 and NTU-RGB+D 120.