 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnyCBMs: How to Turn Any Black Box into a Concept Bottleneck Model
May 26, 2024



Interpretable deep learning aims at developing neural architectures whose decision-making processes could be understood by their users. Among these techniqes, Concept Bottleneck Models enhance the interpretability of neural networks by integrating a layer of human-understandable concepts. These models, however, necessitate training a new model from the beginning, consuming significant resources and failing to utilize already trained large models. To address this issue, we introduce "AnyCBM", a method that transforms any existing trained model into a Concept Bottleneck Model with minimal impact on computational resources. We provide both theoretical and experimental insights showing the effectiveness of AnyCBMs in terms of classification performances and effectivenss of concept-based interventions on downstream tasks.
Explainable Malware Detection with Tailored Logic Explained Networks
May 05, 2024Malware detection is a constant challenge in cybersecurity due to the rapid development of new attack techniques. Traditional signature-based approaches struggle to keep pace with the sheer volume of malware samples. Machine learning offers a promising solution, but faces issues of generalization to unseen samples and a lack of explanation for the instances identified as malware. However, human-understandable explanations are especially important in security-critical fields, where understanding model decisions is crucial for trust and legal compliance. While deep learning models excel at malware detection, their black-box nature hinders explainability. Conversely, interpretable models often fall short in performance. To bridge this gap in this application domain, we propose the use of Logic Explained Networks (LENs), which are a recently proposed class of interpretable neural networks providing explanations in the form of First-Order Logic (FOL) rules. This paper extends the application of LENs to the complex domain of malware detection, specifically using the large-scale EMBER dataset. In the experimental results we show that LENs achieve robustness that exceeds traditional interpretable methods and that are rivaling black-box models. Moreover, we introduce a tailored version of LENs that is shown to generate logic explanations with higher fidelity with respect to the model's predictions.
Climbing the Ladder of Interpretability with Counterfactual Concept Bottleneck Models
Feb 02, 2024



Current deep learning models are not designed to simultaneously address three fundamental questions: predict class labels to solve a given classification task (the "What?"), explain task predictions (the "Why?"), and imagine alternative scenarios that could result in different predictions (the "What if?"). The inability to answer these questions represents a crucial gap in deploying reliable AI agents, calibrating human trust, and deepening human-machine interaction. To bridge this gap, we introduce CounterFactual Concept Bottleneck Models (CF-CBMs), a class of models designed to efficiently address the above queries all at once without the need to run post-hoc searches. Our results show that CF-CBMs produce: accurate predictions (the "What?"), simple explanations for task predictions (the "Why?"), and interpretable counterfactuals (the "What if?"). CF-CBMs can also sample or estimate the most probable counterfactual to: (i) explain the effect of concept interventions on tasks, (ii) show users how to get a desired class label, and (iii) propose concept interventions via "task-driven" interventions.
Relational Concept Based Models
Aug 23, 2023



The design of interpretable deep learning models working in relational domains poses an open challenge: interpretable deep learning methods, such as Concept-Based Models (CBMs), are not designed to solve relational problems, while relational models are not as interpretable as CBMs. To address this problem, we propose Relational Concept-Based Models, a family of relational deep learning methods providing interpretable task predictions. Our experiments, ranging from image classification to link prediction in knowledge graphs, show that relational CBMs (i) match generalization performance of existing relational black-boxes (as opposed to non-relational CBMs), (ii) support the generation of quantified concept-based explanations, (iii) effectively respond to test-time interventions, and (iv) withstand demanding settings including out-of-distribution scenarios, limited training data regimes, and scarce concept supervisions.
Categorical Foundations of Explainable AI: A Unifying Formalism of Structures and Semantics
Apr 27, 2023Explainable AI (XAI) aims to answer ethical and legal questions associated with the deployment of AI models. However, a considerable number of domain-specific reviews highlight the need of a mathematical foundation for the key notions in the field, considering that even the term "explanation" still lacks a precise definition. These reviews also advocate for a sound and unifying formalism for explainable AI, to avoid the emergence of ill-posed questions, and to help researchers navigate a rapidly growing body of knowledge. To the authors knowledge, this paper is the first attempt to fill this gap by formalizing a unifying theory of XAI. Employing the framework of category theory, and feedback monoidal categories in particular, we first provide formal definitions for all essential terms in explainable AI. Then we propose a taxonomy of the field following the proposed structure, showing how the introduced theory can be used to categorize all the main classes of XAI systems currently studied in literature. In summary, the foundation of XAI proposed in this paper represents a significant tool to properly frame future research lines, and a precious guidance for new researchers approaching the field.
Interpretable Neural-Symbolic Concept Reasoning
Apr 27, 2023



Deep learning methods are highly accurate, yet their opaque decision process prevents them from earning full human trust. Concept-based models aim to address this issue by learning tasks based on a set of human-understandable concepts. However, state-of-the-art concept-based models rely on high-dimensional concept embedding representations which lack a clear semantic meaning, thus questioning the interpretability of their decision process. To overcome this limitation, we propose the Deep Concept Reasoner (DCR), the first interpretable concept-based model that builds upon concept embeddings. In DCR, neural networks do not make task predictions directly, but they build syntactic rule structures using concept embeddings. DCR then executes these rules on meaningful concept truth degrees to provide a final interpretable and semantically-consistent prediction in a differentiable manner. Our experiments show that DCR: (i) improves up to +25% w.r.t. state-of-the-art interpretable concept-based models on challenging benchmarks (ii) discovers meaningful logic rules matching known ground truths even in the absence of concept supervision during training, and (iii), facilitates the generation of counterfactual examples providing the learnt rules as guidance.
Enhancing Embedding Representations of Biomedical Data using Logic Knowledge
Mar 23, 2023



Knowledge Graph Embeddings (KGE) have become a quite popular class of models specifically devised to deal with ontologies and graph structure data, as they can implicitly encode statistical dependencies between entities and relations in a latent space. KGE techniques are particularly effective for the biomedical domain, where it is quite common to deal with large knowledge graphs underlying complex interactions between biological and chemical objects. Recently in the literature, the PharmKG dataset has been proposed as one of the most challenging knowledge graph biomedical benchmark, with hundreds of thousands of relational facts between genes, diseases and chemicals. Despite KGEs can scale to very large relational domains, they generally fail at representing more complex relational dependencies between facts, like logic rules, which may be fundamental in complex experimental settings. In this paper, we exploit logic rules to enhance the embedding representations of KGEs on the PharmKG dataset. To this end, we adopt Relational Reasoning Network (R2N), a recently proposed neural-symbolic approach showing promising results on knowledge graph completion tasks. An R2N uses the available logic rules to build a neural architecture that reasons over KGE latent representations. In the experiments, we show that our approach is able to significantly improve the current state-of-the-art on the PharmKG dataset. Finally, we provide an ablation study to experimentally compare the effect of alternative sets of rules according to different selection criteria and varying the number of considered rules.
Extending Logic Explained Networks to Text Classification
Nov 04, 2022



Recently, Logic Explained Networks (LENs) have been proposed as explainable-by-design neural models providing logic explanations for their predictions. However, these models have only been applied to vision and tabular data, and they mostly favour the generation of global explanations, while local ones tend to be noisy and verbose. For these reasons, we propose LENp, improving local explanations by perturbing input words, and we test it on text classification. Our results show that (i) LENp provides better local explanations than LIME in terms of sensitivity and faithfulness, and (ii) logic explanations are more useful and user-friendly than feature scoring provided by LIME as attested by a human survey.
Concept Embedding Models
Sep 19, 2022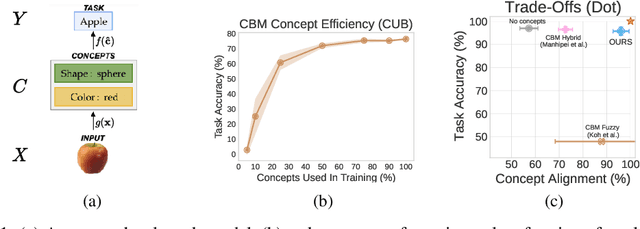

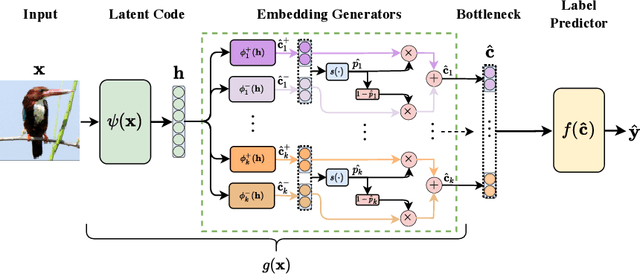

Deploying AI-powered systems requires trustworthy models supporting effective human interactions, going beyond raw prediction accuracy. Concept bottleneck models promote trustworthiness by conditioning classification tasks on an intermediate level of human-like concepts. This enables human interventions which can correct mispredicted concepts to improve the model's performance. However, existing concept bottleneck models are unable to find optimal compromises between high task accuracy, robust concept-based explanations, and effective interventions on concepts -- particularly in real-world conditions where complete and accurate concept supervisions are scarce. To address this, we propose Concept Embedding Models, a novel family of concept bottleneck models which goes beyond the current accuracy-vs-interpretability trade-off by learning interpretable high-dimensional concept representations. Our experiments demonstrate that Concept Embedding Models (1) attain better or competitive task accuracy w.r.t. standard neural models without concepts, (2) provide concept representations capturing meaningful semantics including and beyond their ground truth labels, (3) support test-time concept interventions whose effect in test accuracy surpasses that in standard concept bottleneck models, and (4) scale to real-world conditions where complete concept supervisions are scarce.
Logic Explained Networks
Aug 11, 2021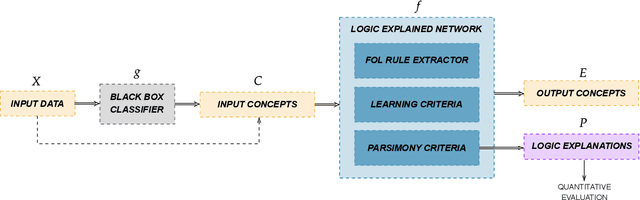

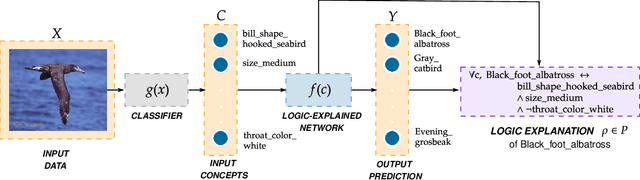

The large and still increasing popularity of deep learning clashes with a major limit of neural network architectures, that consists in their lack of capability in providing human-understandable motivations of their decisions. In situations in which the machine is expected to support the decision of human experts, providing a comprehensible explanation is a feature of crucial importance. The language used to communicate the explanations must be formal enough to be implementable in a machine and friendly enough to be understandable by a wide audience. In this paper, we propose a general approach to Explainable Artificial Intelligence in the case of neural architectures, showing how a mindful design of the networks leads to a family of interpretable deep learning models called Logic Explained Networks (LENs). LENs only require their inputs to be human-understandable predicates, and they provide explanations in terms of simple First-Order Logic (FOL) formulas involving such predicates. LENs are general enough to cover a large number of scenarios. Amongst them, we consider the case in which LENs are directly used as special classifiers with the capability of being explainable, or when they act as additional networks with the role of creating the conditions for making a black-box classifier explainable by FOL formulas. Despite supervised learning problems are mostly emphasized, we also show that LENs can learn and provide explanations in unsupervised learning settings. Experimental results on several datasets and tasks show that LENs may yield better classifications than established white-box models, such as decision trees and Bayesian rule lists, while providing more compact and meaningful explanations.