 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUltra-fast feature learning for the training of two-layer neural networks in the two-timescale regime
Apr 25, 2025We study the convergence of gradient methods for the training of mean-field single hidden layer neural networks with square loss. Observing this is a separable non-linear least-square problem which is linear w.r.t. the outer layer's weights, we consider a Variable Projection (VarPro) or two-timescale learning algorithm, thereby eliminating the linear variables and reducing the learning problem to the training of the feature distribution. Whereas most convergence rates or the training of neural networks rely on a neural tangent kernel analysis where features are fixed, we show such a strategy enables provable convergence rates for the sampling of a teacher feature distribution. Precisely, in the limit where the regularization strength vanishes, we show that the dynamic of the feature distribution corresponds to a weighted ultra-fast diffusion equation. Relying on recent results on the asymptotic behavior of such PDEs, we obtain guarantees for the convergence of the trained feature distribution towards the teacher feature distribution in a teacher-student setup.
Understanding the training of infinitely deep and wide ResNets with Conditional Optimal Transport
Mar 19, 2024We study the convergence of gradient flow for the training of deep neural networks. If Residual Neural Networks are a popular example of very deep architectures, their training constitutes a challenging optimization problem due notably to the non-convexity and the non-coercivity of the objective. Yet, in applications, those tasks are successfully solved by simple optimization algorithms such as gradient descent. To better understand this phenomenon, we focus here on a ``mean-field'' model of infinitely deep and arbitrarily wide ResNet, parameterized by probability measures over the product set of layers and parameters and with constant marginal on the set of layers. Indeed, in the case of shallow neural networks, mean field models have proven to benefit from simplified loss-landscapes and good theoretical guarantees when trained with gradient flow for the Wasserstein metric on the set of probability measures. Motivated by this approach, we propose to train our model with gradient flow w.r.t. the conditional Optimal Transport distance: a restriction of the classical Wasserstein distance which enforces our marginal condition. Relying on the theory of gradient flows in metric spaces we first show the well-posedness of the gradient flow equation and its consistency with the training of ResNets at finite width. Performing a local Polyak-\L{}ojasiewicz analysis, we then show convergence of the gradient flow for well-chosen initializations: if the number of features is finite but sufficiently large and the risk is sufficiently small at initialization, the gradient flow converges towards a global minimizer. This is the first result of this type for infinitely deep and arbitrarily wide ResNets.
Global convergence of ResNets: From finite to infinite width using linear parameterization
Dec 10, 2021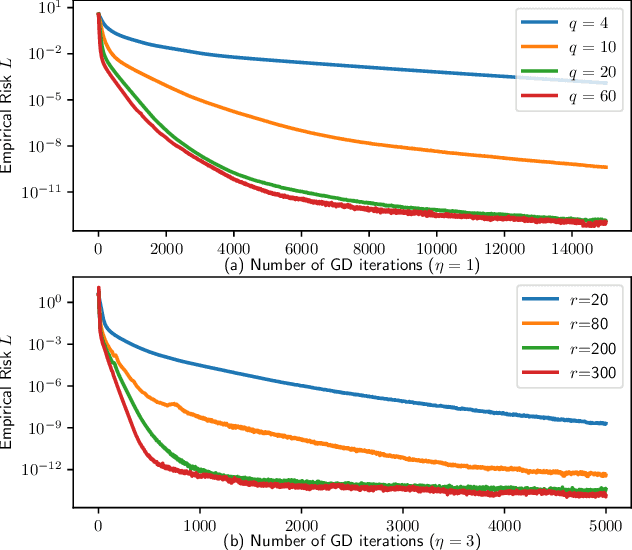
Overparametrization is a key factor in the absence of convexity to explain global convergence of gradient descent (GD) for neural networks. Beside the well studied lazy regime, infinite width (mean field) analysis has been developed for shallow networks, using on convex optimization technics. To bridge the gap between the lazy and mean field regimes, we study Residual Networks (ResNets) in which the residual block has linear parametrization while still being nonlinear. Such ResNets admit both infinite depth and width limits, encoding residual blocks in a Reproducing Kernel Hilbert Space (RKHS). In this limit, we prove a local Polyak-Lojasiewicz inequality. Thus, every critical point is a global minimizer and a local convergence result of GD holds, retrieving the lazy regime. In contrast with other mean-field studies, it applies to both parametric and non-parametric cases under an expressivity condition on the residuals. Our analysis leads to a practical and quantified recipe: starting from a universal RKHS, Random Fourier Features are applied to obtain a finite dimensional parameterization satisfying with high-probability our expressivity condition.