 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning Boosts Opinion Alignment in LLMs
Mar 01, 2026Opinion modeling aims to capture individual or group political preferences, enabling applications such as digital democracies, where models could help shape fairer and more popular policies. Given their versatility, strong generalization capabilities, and demonstrated success across diverse text-to-text applications, large language models (LLMs) are natural candidates for this task. However, due to their statistical nature and limited causal understanding, they tend to produce biased opinions when prompted naively. In this work, we study whether reasoning can improve opinion alignment. Motivated by the recent advancement in mathematical reasoning enabled by reinforcement learning (RL), we train models to produce profile-consistent answers through structured reasoning. We evaluate our approach on three datasets covering U.S., European, and Swiss politics. Results indicate that reasoning enhances opinion modeling and is competitive with strong baselines, but does not fully remove bias, highlighting the need for additional mechanisms to build faithful political digital twins using LLMs. By releasing both our method and datasets, we establish a solid baseline to support future research on LLM opinion alignment.
Recommender Systems for Democracy: Toward Adversarial Robustness in Voting Advice Applications
May 19, 2025
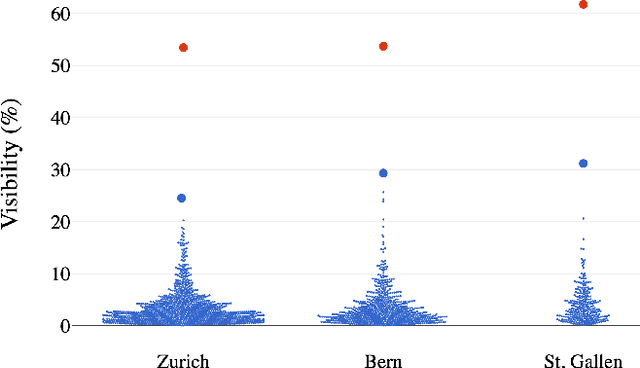


Voting advice applications (VAAs) help millions of voters understand which political parties or candidates best align with their views. This paper explores the potential risks these applications pose to the democratic process when targeted by adversarial entities. In particular, we expose 11 manipulation strategies and measure their impact using data from Switzerland's primary VAA, Smartvote, collected during the last two national elections. We find that altering application parameters, such as the matching method, can shift a party's recommendation frequency by up to 105%. Cherry-picking questionnaire items can increase party recommendation frequency by over 261%, while subtle changes to parties' or candidates' responses can lead to a 248% increase. To address these vulnerabilities, we propose adversarial robustness properties VAAs should satisfy, introduce empirical metrics for assessing the resilience of various matching methods, and suggest possible avenues for research toward mitigating the effect of manipulation. Our framework is key to ensuring secure and reliable AI-based VAAs poised to emerge in the near future.