 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniversal Phone Recognition with a Multilingual Allophone System
Feb 26, 2020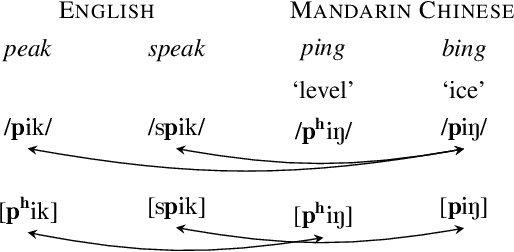

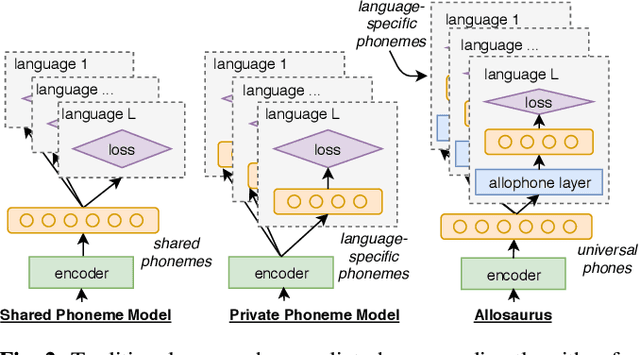

Multilingual models can improve language processing, particularly for low resource situations, by sharing parameters across languages. Multilingual acoustic models, however, generally ignore the difference between phonemes (sounds that can support lexical contrasts in a particular language) and their corresponding phones (the sounds that are actually spoken, which are language independent). This can lead to performance degradation when combining a variety of training languages, as identically annotated phonemes can actually correspond to several different underlying phonetic realizations. In this work, we propose a joint model of both language-independent phone and language-dependent phoneme distributions. In multilingual ASR experiments over 11 languages, we find that this model improves testing performance by 2% phoneme error rate absolute in low-resource conditions. Additionally, because we are explicitly modeling language-independent phones, we can build a (nearly-)universal phone recognizer that, when combined with the PHOIBLE large, manually curated database of phone inventories, can be customized into 2,000 language dependent recognizers. Experiments on two low-resourced indigenous languages, Inuktitut and Tusom, show that our recognizer achieves phone accuracy improvements of more than 17%, moving a step closer to speech recognition for all languages in the world.
Towards Zero-shot Learning for Automatic Phonemic Transcription
Feb 26, 2020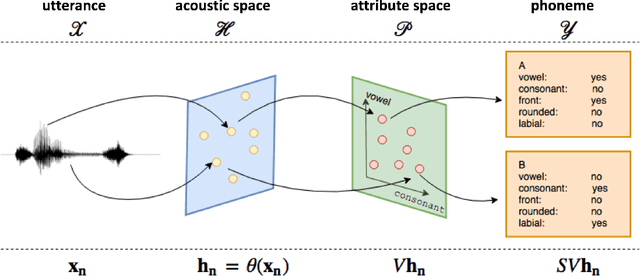
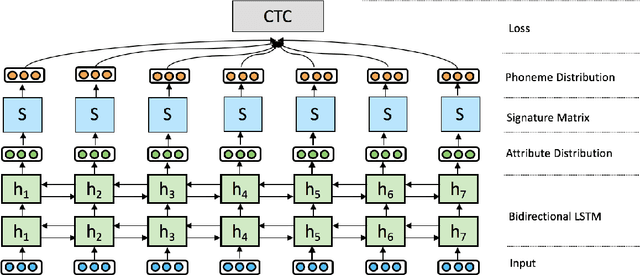
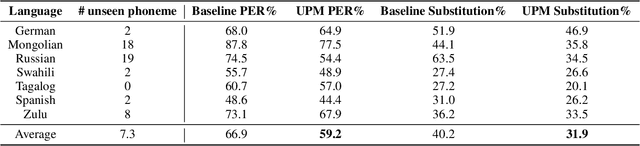
Automatic phonemic transcription tools are useful for low-resource language documentation. However, due to the lack of training sets, only a tiny fraction of languages have phonemic transcription tools. Fortunately, multilingual acoustic modeling provides a solution given limited audio training data. A more challenging problem is to build phonemic transcribers for languages with zero training data. The difficulty of this task is that phoneme inventories often differ between the training languages and the target language, making it infeasible to recognize unseen phonemes. In this work, we address this problem by adopting the idea of zero-shot learning. Our model is able to recognize unseen phonemes in the target language without any training data. In our model, we decompose phonemes into corresponding articulatory attributes such as vowel and consonant. Instead of predicting phonemes directly, we first predict distributions over articulatory attributes, and then compute phoneme distributions with a customized acoustic model. We evaluate our model by training it using 13 languages and testing it using 7 unseen languages. We find that it achieves 7.7% better phoneme error rate on average over a standard multilingual model.
Looking Enhances Listening: Recovering Missing Speech Using Images
Feb 13, 2020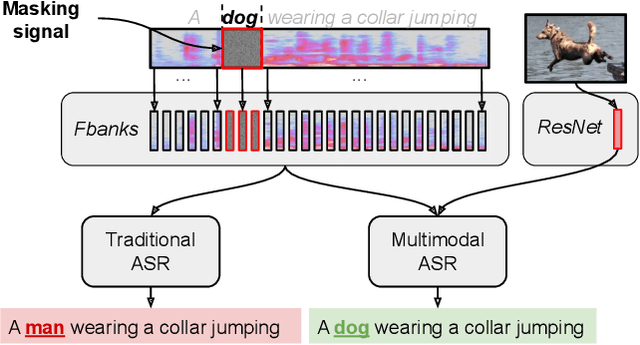
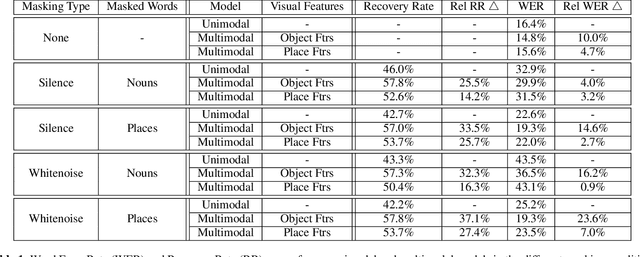
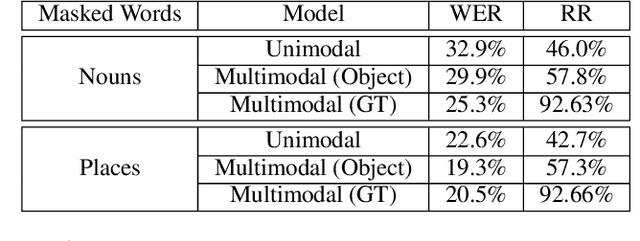

Speech is understood better by using visual context; for this reason, there have been many attempts to use images to adapt automatic speech recognition (ASR) systems. Current work, however, has shown that visually adapted ASR models only use images as a regularization signal, while completely ignoring their semantic content. In this paper, we present a set of experiments where we show the utility of the visual modality under noisy conditions. Our results show that multimodal ASR models can recover words which are masked in the input acoustic signal, by grounding its transcriptions using the visual representations. We observe that integrating visual context can result in up to 35% relative improvement in masked word recovery. These results demonstrate that end-to-end multimodal ASR systems can become more robust to noise by leveraging the visual context.
Gun Source and Muzzle Head Detection
Jan 29, 2020
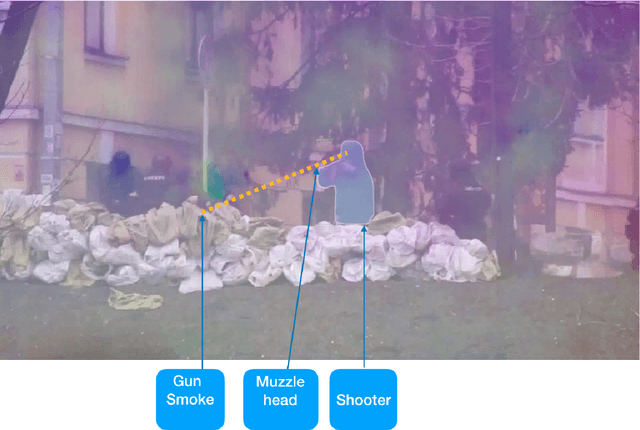


There is a surging need across the world for protection against gun violence. There are three main areas that we have identified as challenging in research that tries to curb gun violence: temporal location of gunshots, gun type prediction and gun source (shooter) detection. Our task is gun source detection and muzzle head detection, where the muzzle head is the round opening of the firing end of the gun. We would like to locate the muzzle head of the gun in the video visually, and identify who has fired the shot. In our formulation, we turn the problem of muzzle head detection into two sub-problems of human object detection and gun smoke detection. Our assumption is that the muzzle head typically lies between the gun smoke caused by the shot and the shooter. We have interesting results both in bounding the shooter as well as detecting the gun smoke. In our experiments, we are successful in detecting the muzzle head by detecting the gun smoke and the shooter.
On Compositionality in Neural Machine Translation
Dec 14, 2019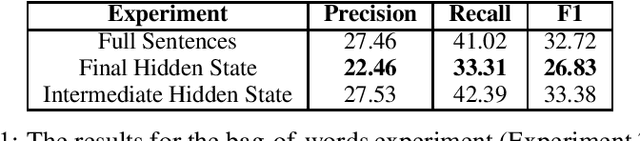

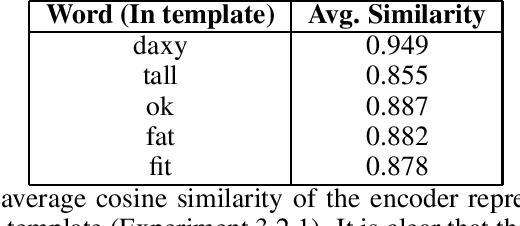

We investigate two specific manifestations of compositionality in Neural Machine Translation (NMT) : (1) Productivity - the ability of the model to extend its predictions beyond the observed length in training data and (2) Systematicity - the ability of the model to systematically recombine known parts and rules. We evaluate a standard Sequence to Sequence model on tests designed to assess these two properties in NMT. We quantitatively demonstrate that inadequate temporal processing, in the form of poor encoder representations is a bottleneck for both Productivity and Systematicity. We propose a simple pre-training mechanism which alleviates model performance on the two properties and leads to a significant improvement in BLEU scores.
Adversarial Music: Real World Audio Adversary Against Wake-word Detection System
Dec 06, 2019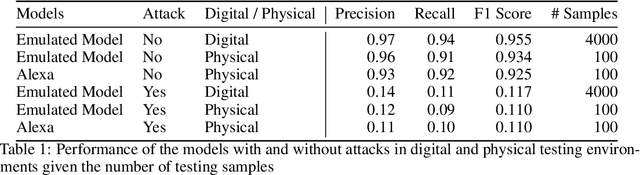
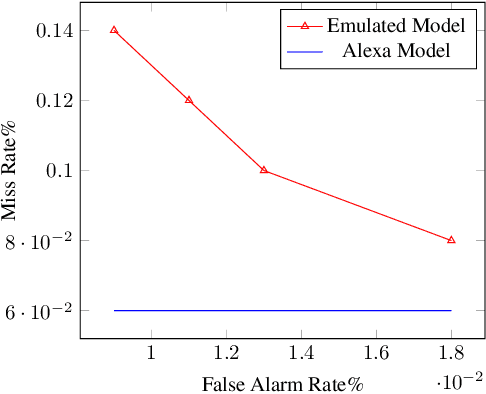

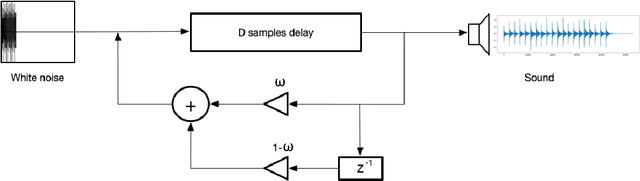
Voice Assistants (VAs) such as Amazon Alexa or Google Assistant rely on wake-word detection to respond to people's commands, which could potentially be vulnerable to audio adversarial examples. In this work, we target our attack on the wake-word detection system, jamming the model with some inconspicuous background music to deactivate the VAs while our audio adversary is present. We implemented an emulated wake-word detection system of Amazon Alexa based on recent publications. We validated our models against the real Alexa in terms of wake-word detection accuracy. Then we computed our audio adversaries with consideration of expectation over transform and we implemented our audio adversary with a differentiable synthesizer. Next, we verified our audio adversaries digitally on hundreds of samples of utterances collected from the real world. Our experiments show that we can effectively reduce the recognition F1 score of our emulated model from 93.4% to 11.0%. Finally, we tested our audio adversary over the air, and verified it works effectively against Alexa, reducing its F1 score from 92.5% to 11.0%.; We also verified that non-adversarial music does not disable Alexa as effectively as our music at the same sound level. To the best of our knowledge, this is the first real-world adversarial attack against a commercial-grade VA wake-word detection system. Our code and demo videos can be accessed at \url{https://www.junchengbillyli.com/AdversarialMusic}
* 9 pages, In Proceedings of NeurIPS 2019 Conference
Enforcing Encoder-Decoder Modularity in Sequence-to-Sequence Models
Nov 09, 2019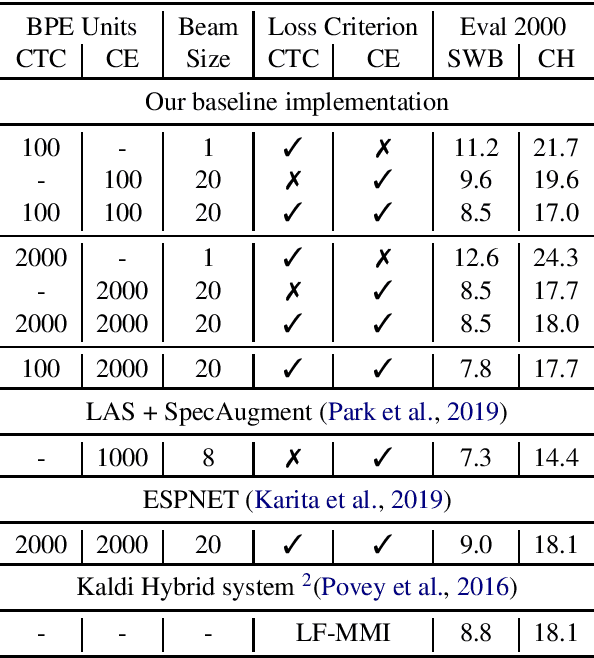
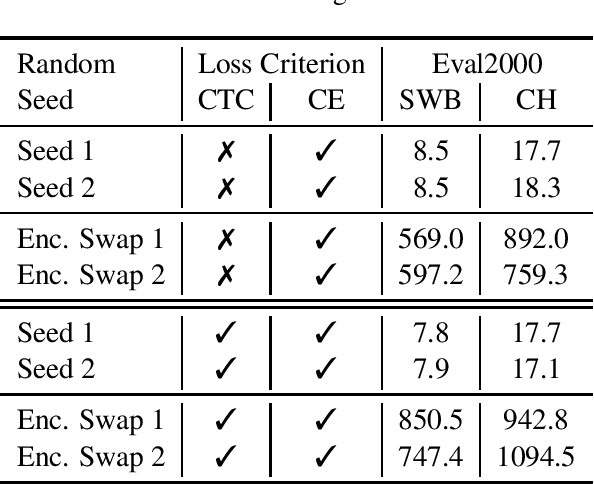
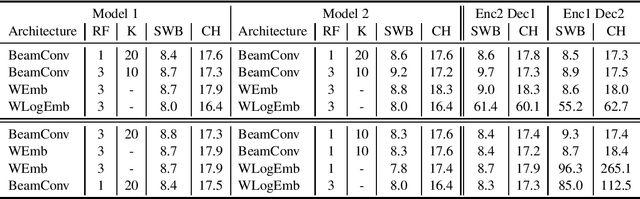
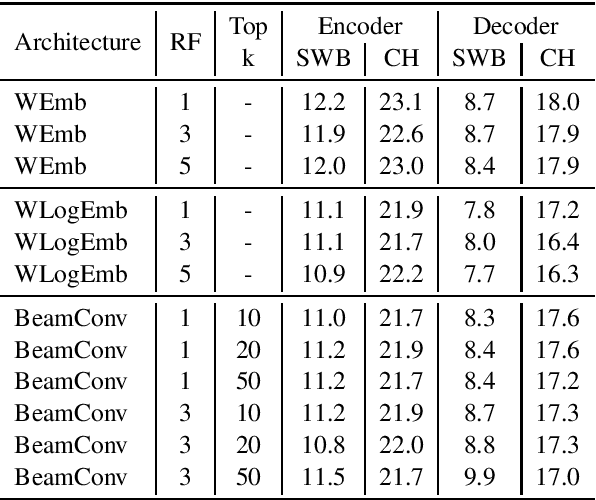
Inspired by modular software design principles of independence, interchangeability, and clarity of interface, we introduce a method for enforcing encoder-decoder modularity in seq2seq models without sacrificing the overall model quality or its full differentiability. We discretize the encoder output units into a predefined interpretable vocabulary space using the Connectionist Temporal Classification (CTC) loss. Our modular systems achieve near SOTA performance on the 300h Switchboard benchmark, with WER of 8.3% and 17.6% on the SWB and CH subsets, using seq2seq models with encoder and decoder modules which are independent and interchangeable.
Multitask Learning For Different Subword Segmentations In Neural Machine Translation
Oct 27, 2019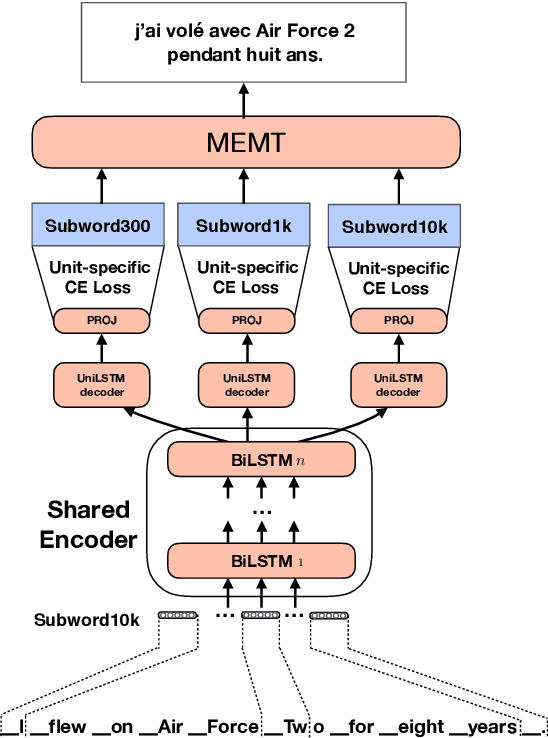
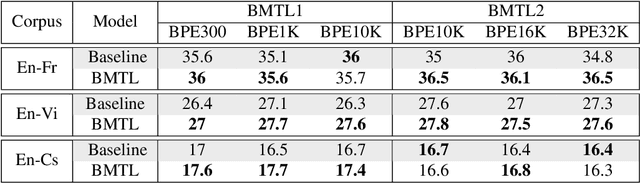
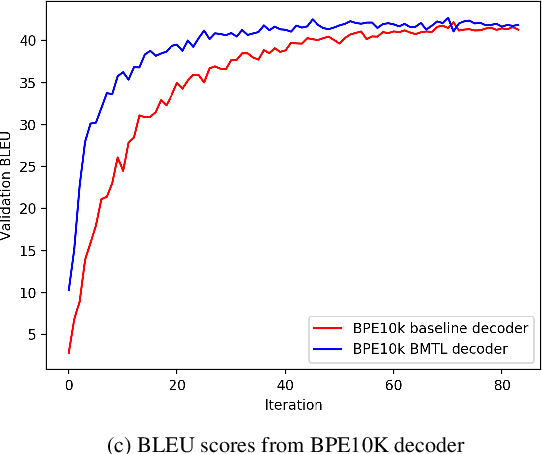
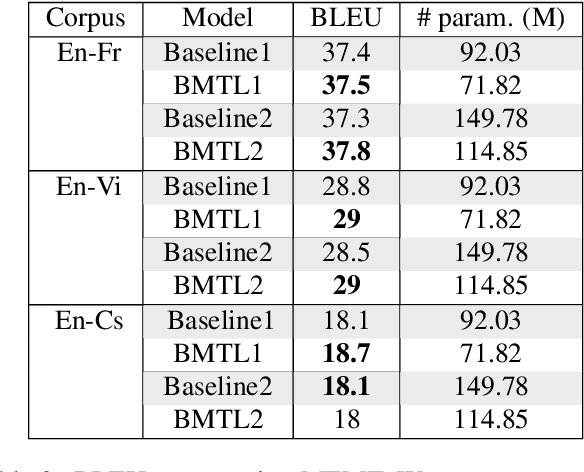
In Neural Machine Translation (NMT) the usage of subwords and characters as source and target units offers a simple and flexible solution for translation of rare and unseen words. However, selecting the optimal subword segmentation involves a trade-off between expressiveness and flexibility, and is language and dataset-dependent. We present Block Multitask Learning (BMTL), a novel NMT architecture that predicts multiple targets of different granularities simultaneously, removing the need to search for the optimal segmentation strategy. Our multi-task model exhibits improvements of up to 1.7 BLEU points on each decoder over single-task baseline models with the same number of parameters on datasets from two language pairs of IWSLT15 and one from IWSLT19. The multiple hypotheses generated at different granularities can be combined as a post-processing step to give better translations, which improves over hypothesis combination from baseline models while using substantially fewer parameters.
On Leveraging the Visual Modality for Neural Machine Translation
Oct 07, 2019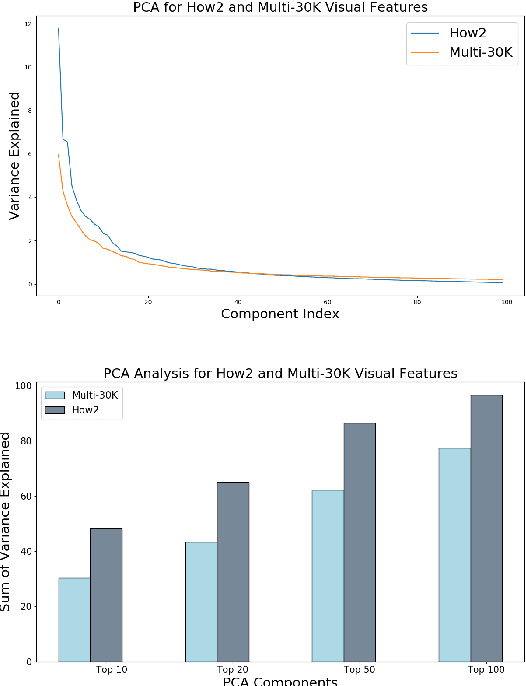


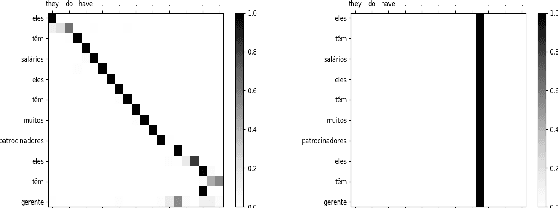
Leveraging the visual modality effectively for Neural Machine Translation (NMT) remains an open problem in computational linguistics. Recently, Caglayan et al. posit that the observed gains are limited mainly due to the very simple, short, repetitive sentences of the Multi30k dataset (the only multimodal MT dataset available at the time), which renders the source text sufficient for context. In this work, we further investigate this hypothesis on a new large scale multimodal Machine Translation (MMT) dataset, How2, which has 1.57 times longer mean sentence length than Multi30k and no repetition. We propose and evaluate three novel fusion techniques, each of which is designed to ensure the utilization of visual context at different stages of the Sequence-to-Sequence transduction pipeline, even under full linguistic context. However, we still obtain only marginal gains under full linguistic context and posit that visual embeddings extracted from deep vision models (ResNet for Multi30k, ResNext for How2) do not lend themselves to increasing the discriminativeness between the vocabulary elements at token level prediction in NMT. We demonstrate this qualitatively by analyzing attention distribution and quantitatively through Principal Component Analysis, arriving at the conclusion that it is the quality of the visual embeddings rather than the length of sentences, which need to be improved in existing MMT datasets.
On Dimensional Linguistic Properties of the Word Embedding Space
Oct 05, 2019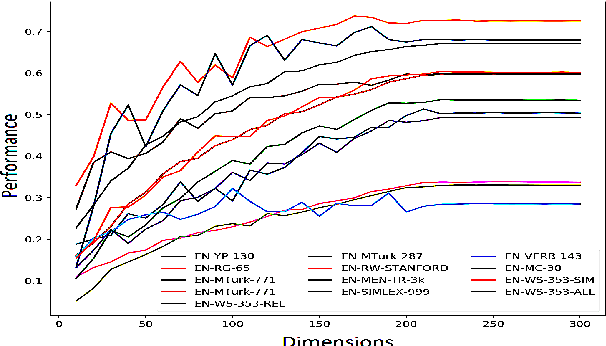
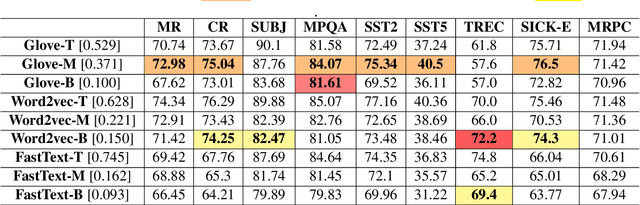
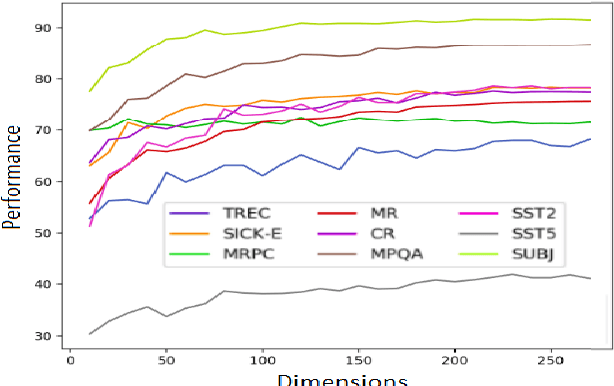
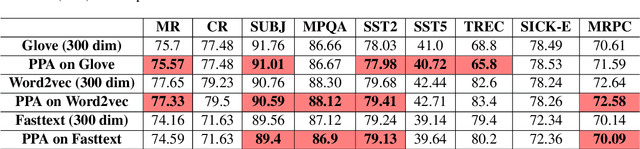
Word embeddings have become a staple of several natural language processing tasks, yet much remains to be understood about their properties. In this work, we analyze word embeddings in terms of their principal components and arrive at a number of novel conclusions. In particular, we characterize the utility of variance explained by the principal components (widely used as a fundamental tool to assess the quality of the resulting representations) as a proxy for downstream performance. Further, through dimensional linguistic probing of the embedding space, we show that the syntactic information captured by a principal component does not depend on the amount of variance it explains. Consequently, we investigate the limitations of variance based embedding post-processing techniques and demonstrate that such post-processing is counter-productive in a number of scenarios such as sentence classification and machine translation tasks. Finally, we offer a few guidelines on variance based embedding post-processing. We have released the source code along with the paper.