 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying Privacy Risks of Masked Language Models Using Membership Inference Attacks
Mar 08, 2022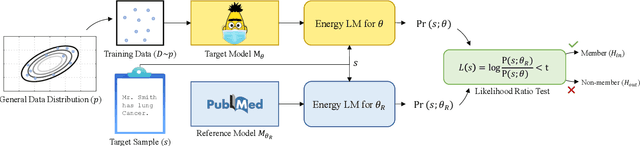


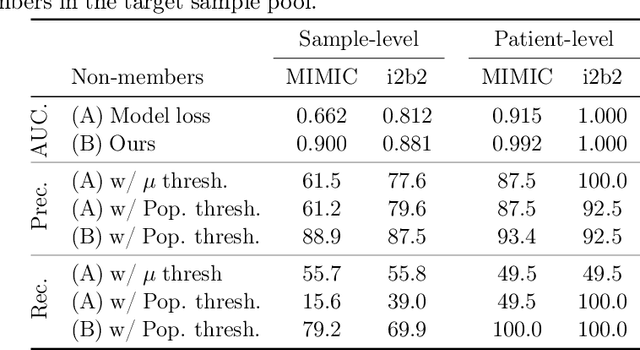
The wide adoption and application of Masked language models~(MLMs) on sensitive data (from legal to medical) necessitates a thorough quantitative investigation into their privacy vulnerabilities -- to what extent do MLMs leak information about their training data? Prior attempts at measuring leakage of MLMs via membership inference attacks have been inconclusive, implying the potential robustness of MLMs to privacy attacks. In this work, we posit that prior attempts were inconclusive because they based their attack solely on the MLM's model score. We devise a stronger membership inference attack based on likelihood ratio hypothesis testing that involves an additional reference MLM to more accurately quantify the privacy risks of memorization in MLMs. We show that masked language models are extremely susceptible to likelihood ratio membership inference attacks: Our empirical results, on models trained on medical notes, show that our attack improves the AUC of prior membership inference attacks from 0.66 to an alarmingly high 0.90 level, with a significant improvement in the low-error region: at 1% false positive rate, our attack is 51X more powerful than prior work.
What Does it Mean for a Language Model to Preserve Privacy?
Feb 14, 2022
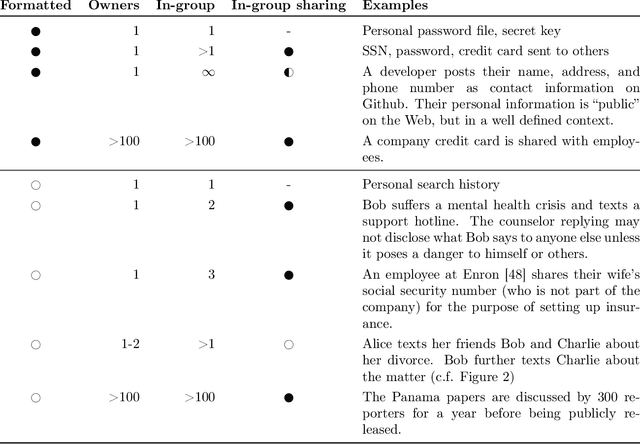
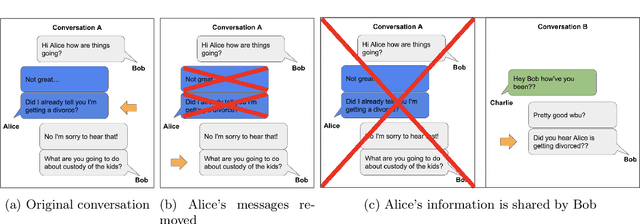
Natural language reflects our private lives and identities, making its privacy concerns as broad as those of real life. Language models lack the ability to understand the context and sensitivity of text, and tend to memorize phrases present in their training sets. An adversary can exploit this tendency to extract training data. Depending on the nature of the content and the context in which this data was collected, this could violate expectations of privacy. Thus there is a growing interest in techniques for training language models that preserve privacy. In this paper, we discuss the mismatch between the narrow assumptions made by popular data protection techniques (data sanitization and differential privacy), and the broadness of natural language and of privacy as a social norm. We argue that existing protection methods cannot guarantee a generic and meaningful notion of privacy for language models. We conclude that language models should be trained on text data which was explicitly produced for public use.
UserIdentifier: Implicit User Representations for Simple and Effective Personalized Sentiment Analysis
Oct 01, 2021
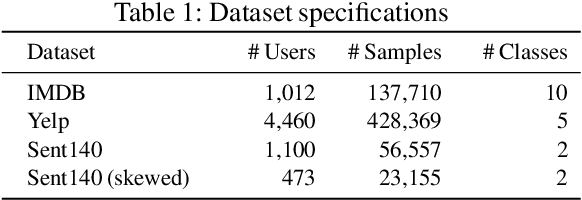
Global models are trained to be as generalizable as possible, with user invariance considered desirable since the models are shared across multitudes of users. As such, these models are often unable to produce personalized responses for individual users, based on their data. Contrary to widely-used personalization techniques based on few-shot learning, we propose UserIdentifier, a novel scheme for training a single shared model for all users. Our approach produces personalized responses by adding fixed, non-trainable user identifiers to the input data. We empirically demonstrate that this proposed method outperforms the prefix-tuning based state-of-the-art approach by up to 13%, on a suite of sentiment analysis datasets. We also show that, unlike prior work, this method needs neither any additional model parameters nor any extra rounds of few-shot fine-tuning.
Style Pooling: Automatic Text Style Obfuscation for Improved Classification Fairness
Sep 10, 2021
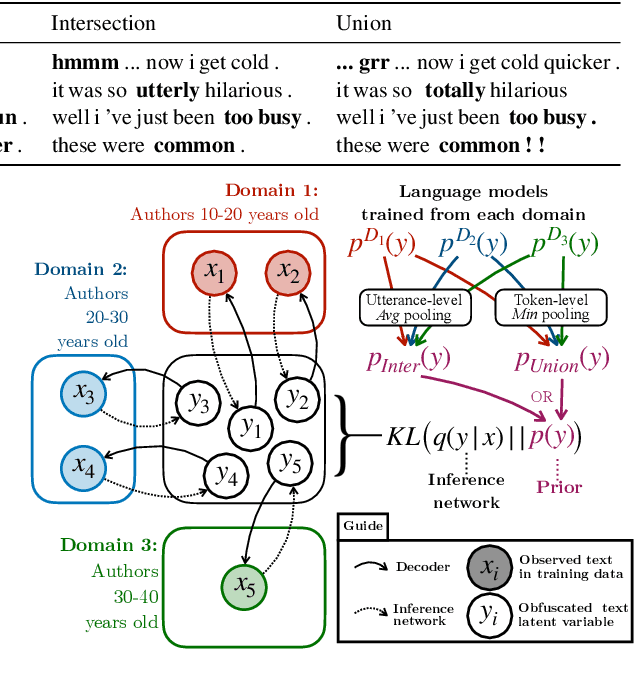
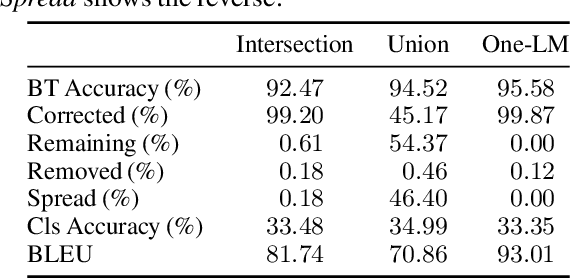
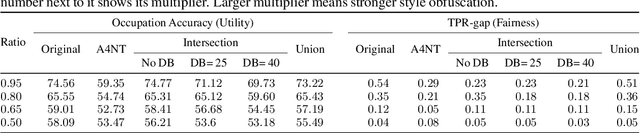
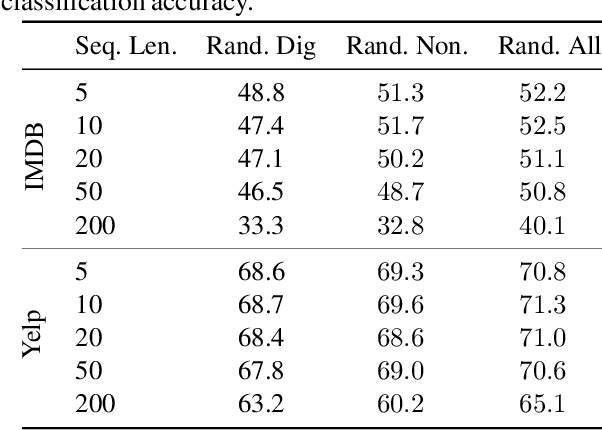
Text style can reveal sensitive attributes of the author (e.g. race or age) to the reader, which can, in turn, lead to privacy violations and bias in both human and algorithmic decisions based on text. For example, the style of writing in job applications might reveal protected attributes of the candidate which could lead to bias in hiring decisions, regardless of whether hiring decisions are made algorithmically or by humans. We propose a VAE-based framework that obfuscates stylistic features of human-generated text through style transfer by automatically re-writing the text itself. Our framework operationalizes the notion of obfuscated style in a flexible way that enables two distinct notions of obfuscated style: (1) a minimal notion that effectively intersects the various styles seen in training, and (2) a maximal notion that seeks to obfuscate by adding stylistic features of all sensitive attributes to text, in effect, computing a union of styles. Our style-obfuscation framework can be used for multiple purposes, however, we demonstrate its effectiveness in improving the fairness of downstream classifiers. We also conduct a comprehensive study on style pooling's effect on fluency, semantic consistency, and attribute removal from text, in two and three domain style obfuscation.
Efficient Hyperparameter Optimization for Differentially Private Deep Learning
Aug 09, 2021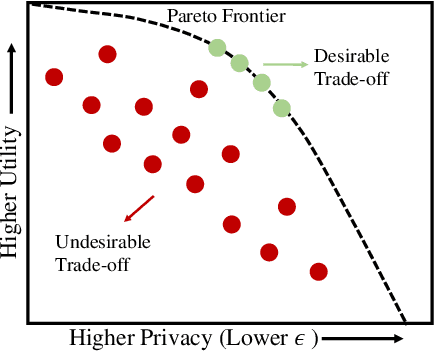
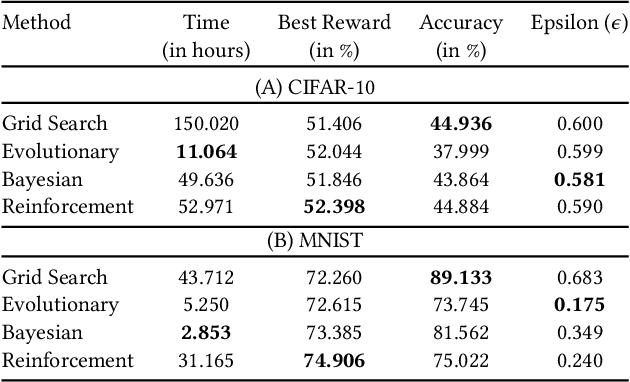
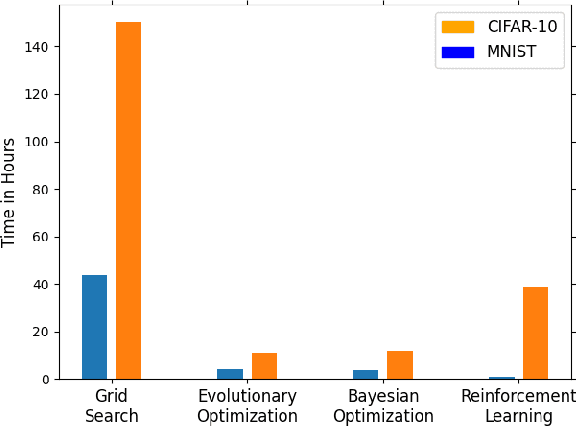
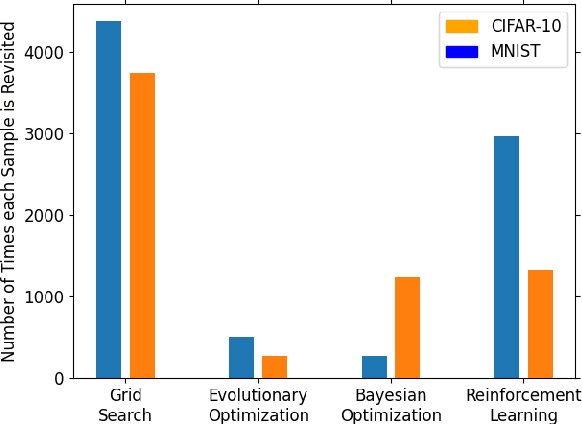
Tuning the hyperparameters in the differentially private stochastic gradient descent (DPSGD) is a fundamental challenge. Unlike the typical SGD, private datasets cannot be used many times for hyperparameter search in DPSGD; e.g., via a grid search. Therefore, there is an essential need for algorithms that, within a given search space, can find near-optimal hyperparameters for the best achievable privacy-utility tradeoffs efficiently. We formulate this problem into a general optimization framework for establishing a desirable privacy-utility tradeoff, and systematically study three cost-effective algorithms for being used in the proposed framework: evolutionary, Bayesian, and reinforcement learning. Our experiments, for hyperparameter tuning in DPSGD conducted on MNIST and CIFAR-10 datasets, show that these three algorithms significantly outperform the widely used grid search baseline. As this paper offers a first-of-a-kind framework for hyperparameter tuning in DPSGD, we discuss existing challenges and open directions for future studies. As we believe our work has implications to be utilized in the pipeline of private deep learning, we open-source our code at https://github.com/AmanPriyanshu/DP-HyperparamTuning.
Benchmarking Differential Privacy and Federated Learning for BERT Models
Jun 26, 2021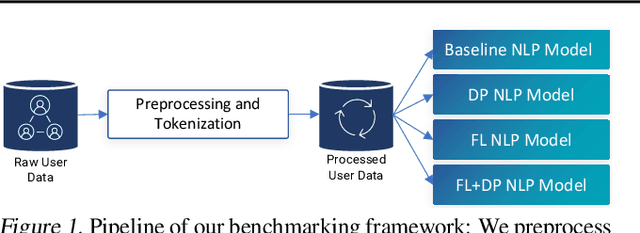
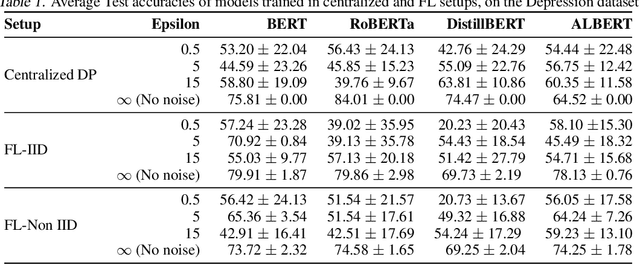
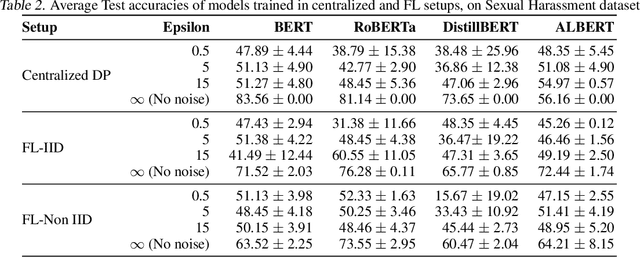
Natural Language Processing (NLP) techniques can be applied to help with the diagnosis of medical conditions such as depression, using a collection of a person's utterances. Depression is a serious medical illness that can have adverse effects on how one feels, thinks, and acts, which can lead to emotional and physical problems. Due to the sensitive nature of such data, privacy measures need to be taken for handling and training models with such data. In this work, we study the effects that the application of Differential Privacy (DP) has, in both a centralized and a Federated Learning (FL) setup, on training contextualized language models (BERT, ALBERT, RoBERTa and DistilBERT). We offer insights on how to privately train NLP models and what architectures and setups provide more desirable privacy utility trade-offs. We envisage this work to be used in future healthcare and mental health studies to keep medical history private. Therefore, we provide an open-source implementation of this work.
When Differential Privacy Meets Interpretability: A Case Study
Jun 25, 2021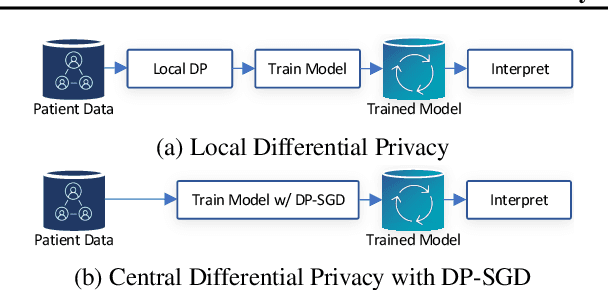



Given the increase in the use of personal data for training Deep Neural Networks (DNNs) in tasks such as medical imaging and diagnosis, differentially private training of DNNs is surging in importance and there is a large body of work focusing on providing better privacy-utility trade-off. However, little attention is given to the interpretability of these models, and how the application of DP affects the quality of interpretations. We propose an extensive study into the effects of DP training on DNNs, especially on medical imaging applications, on the APTOS dataset.
DP-SGD vs PATE: Which Has Less Disparate Impact on Model Accuracy?
Jun 22, 2021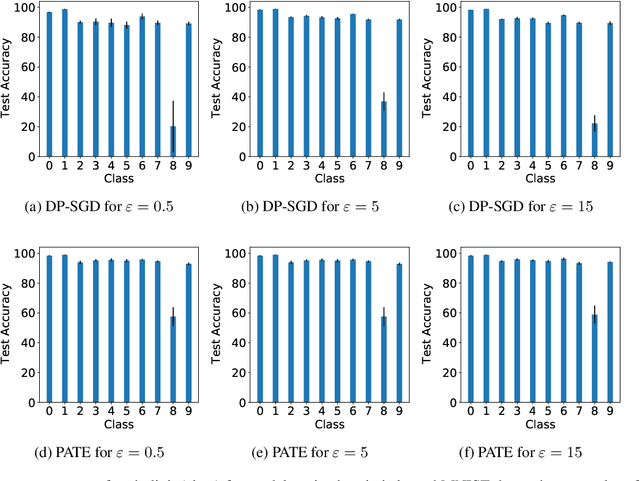
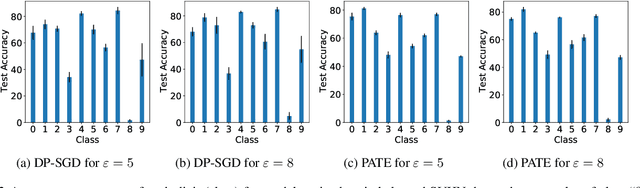
Recent advances in differentially private deep learning have demonstrated that application of differential privacy, specifically the DP-SGD algorithm, has a disparate impact on different sub-groups in the population, which leads to a significantly high drop-in model utility for sub-populations that are under-represented (minorities), compared to well-represented ones. In this work, we aim to compare PATE, another mechanism for training deep learning models using differential privacy, with DP-SGD in terms of fairness. We show that PATE does have a disparate impact too, however, it is much less severe than DP-SGD. We draw insights from this observation on what might be promising directions in achieving better fairness-privacy trade-offs.
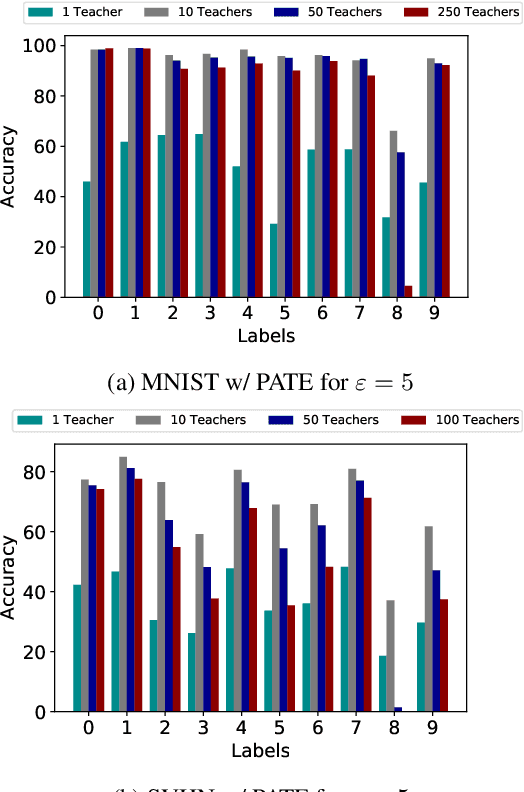
Privacy Regularization: Joint Privacy-Utility Optimization in Language Models
Mar 12, 2021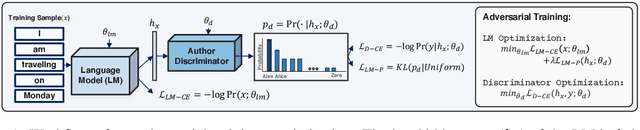
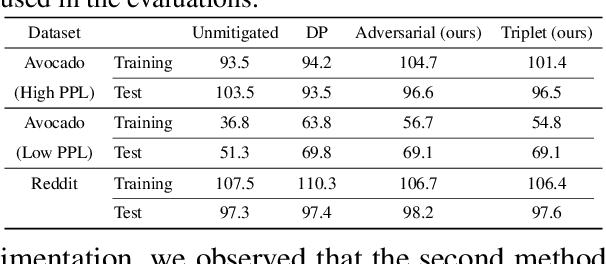
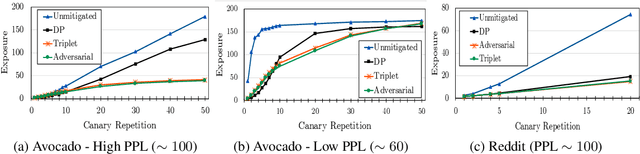

Neural language models are known to have a high capacity for memorization of training samples. This may have serious privacy implications when training models on user content such as email correspondence. Differential privacy (DP), a popular choice to train models with privacy guarantees, comes with significant costs in terms of utility degradation and disparate impact on subgroups of users. In this work, we introduce two privacy-preserving regularization methods for training language models that enable joint optimization of utility and privacy through (1) the use of a discriminator and (2) the inclusion of a triplet-loss term. We compare our methods with DP through extensive evaluation. We show the advantages of our regularizers with favorable utility-privacy trade-off, faster training with the ability to tap into existing optimization approaches, and ensuring uniform treatment of under-represented subgroups.
U-Noise: Learnable Noise Masks for Interpretable Image Segmentation
Jan 20, 2021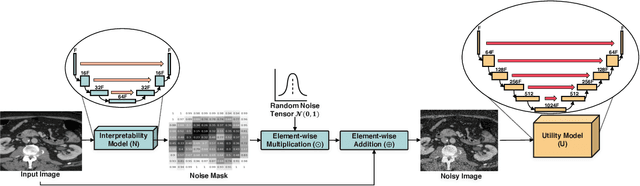
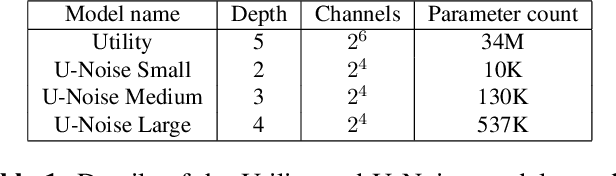
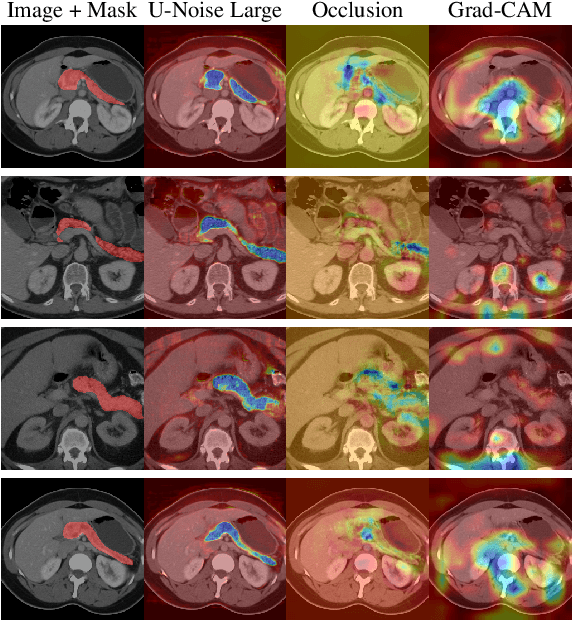

Deep Neural Networks (DNNs) are widely used for decision making in a myriad of critical applications, ranging from medical to societal and even judicial. Given the importance of these decisions, it is crucial for us to be able to interpret these models. We introduce a new method for interpreting image segmentation models by learning regions of images in which noise can be applied without hindering downstream model performance. We apply this method to segmentation of the pancreas in CT scans, and qualitatively compare the quality of the method to existing explainability techniques, such as Grad-CAM and occlusion sensitivity. Additionally we show that, unlike other methods, our interpretability model can be quantitatively evaluated based on the downstream performance over obscured images.