 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivacy enabled Financial Text Classification using Differential Privacy and Federated Learning
Oct 04, 2021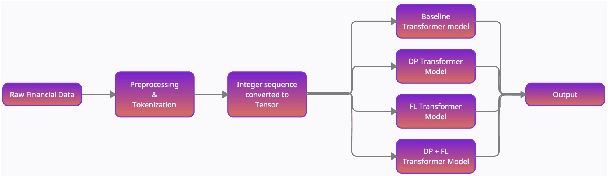
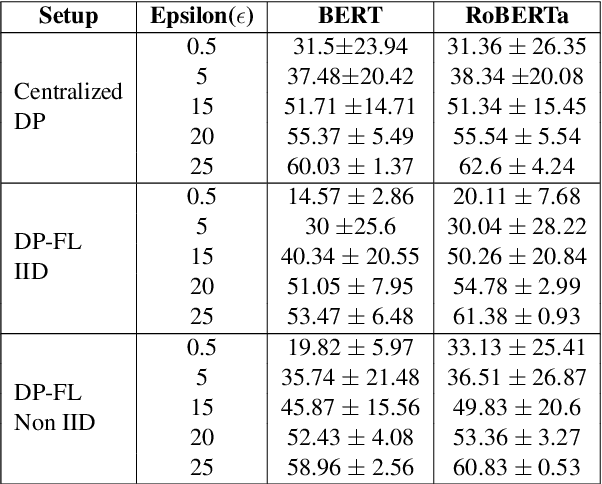
Privacy is important considering the financial Domain as such data is highly confidential and sensitive. Natural Language Processing (NLP) techniques can be applied for text classification and entity detection purposes in financial domains such as customer feedback sentiment analysis, invoice entity detection, categorisation of financial documents by type etc. Due to the sensitive nature of such data, privacy measures need to be taken for handling and training large models with such data. In this work, we propose a contextualized transformer (BERT and RoBERTa) based text classification model integrated with privacy features such as Differential Privacy (DP) and Federated Learning (FL). We present how to privately train NLP models and desirable privacy-utility tradeoffs and evaluate them on the Financial Phrase Bank dataset.
Benchmarking Differential Privacy and Federated Learning for BERT Models
Jun 26, 2021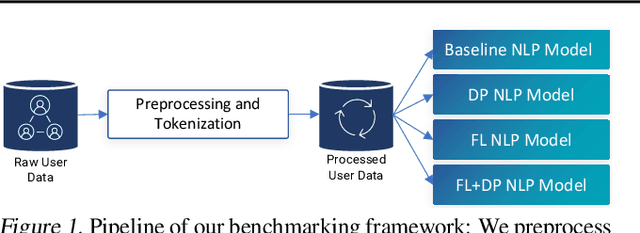
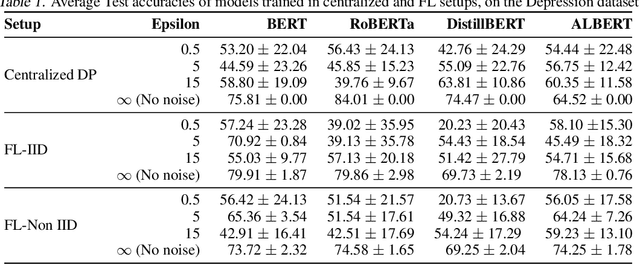
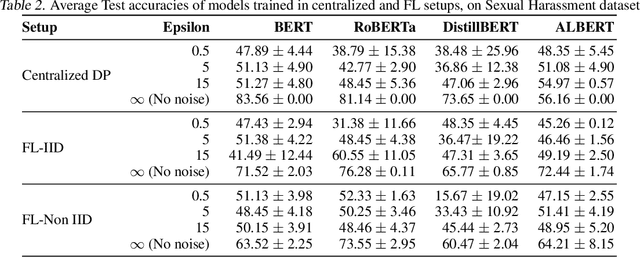
Natural Language Processing (NLP) techniques can be applied to help with the diagnosis of medical conditions such as depression, using a collection of a person's utterances. Depression is a serious medical illness that can have adverse effects on how one feels, thinks, and acts, which can lead to emotional and physical problems. Due to the sensitive nature of such data, privacy measures need to be taken for handling and training models with such data. In this work, we study the effects that the application of Differential Privacy (DP) has, in both a centralized and a Federated Learning (FL) setup, on training contextualized language models (BERT, ALBERT, RoBERTa and DistilBERT). We offer insights on how to privately train NLP models and what architectures and setups provide more desirable privacy utility trade-offs. We envisage this work to be used in future healthcare and mental health studies to keep medical history private. Therefore, we provide an open-source implementation of this work.