 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBAID: A Benchmark for Bias Assessment of AI Detectors
Dec 12, 2025AI-generated text detectors have recently gained adoption in educational and professional contexts. Prior research has uncovered isolated cases of bias, particularly against English Language Learners (ELLs) however, there is a lack of systematic evaluation of such systems across broader sociolinguistic factors. In this work, we propose BAID, a comprehensive evaluation framework for AI detectors across various types of biases. As a part of the framework, we introduce over 200k samples spanning 7 major categories: demographics, age, educational grade level, dialect, formality, political leaning, and topic. We also generated synthetic versions of each sample with carefully crafted prompts to preserve the original content while reflecting subgroup-specific writing styles. Using this, we evaluate four open-source state-of-the-art AI text detectors and find consistent disparities in detection performance, particularly low recall rates for texts from underrepresented groups. Our contributions provide a scalable, transparent approach for auditing AI detectors and emphasize the need for bias-aware evaluation before these tools are deployed for public use.
RankAug: Augmented data ranking for text classification
Nov 08, 2023Research on data generation and augmentation has been focused majorly on enhancing generation models, leaving a notable gap in the exploration and refinement of methods for evaluating synthetic data. There are several text similarity metrics within the context of generated data filtering which can impact the performance of specific Natural Language Understanding (NLU) tasks, specifically focusing on intent and sentiment classification. In this study, we propose RankAug, a text-ranking approach that detects and filters out the top augmented texts in terms of being most similar in meaning with lexical and syntactical diversity. Through experiments conducted on multiple datasets, we demonstrate that the judicious selection of filtering techniques can yield a substantial improvement of up to 35% in classification accuracy for under-represented classes.
Interpretability of Fine-grained Classification of Sadness and Depression
Mar 20, 2022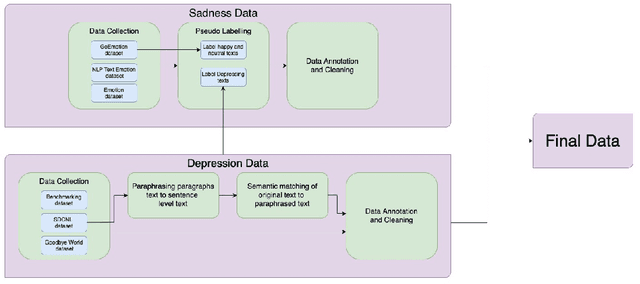

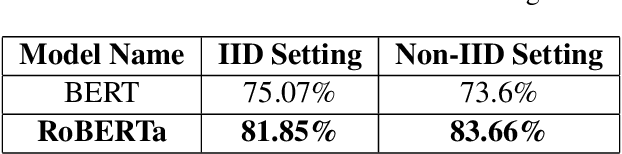

While sadness is a human emotion that people experience at certain times throughout their lives, inflicting them with emotional disappointment and pain, depression is a longer term mental illness which impairs social, occupational, and other vital regions of functioning making it a much more serious issue and needs to be catered to at the earliest. NLP techniques can be utilized for the detection and subsequent diagnosis of these emotions. Most of the open sourced data on the web deal with sadness as a part of depression, as an emotion even though the difference in severity of both is huge. Thus, we create our own novel dataset illustrating the difference between the two. In this paper, we aim to highlight the difference between the two and highlight how interpretable our models are to distinctly label sadness and depression. Due to the sensitive nature of such information, privacy measures need to be taken for handling and training of such data. Hence, we also explore the effect of Federated Learning (FL) on contextualised language models.
Privacy enabled Financial Text Classification using Differential Privacy and Federated Learning
Oct 04, 2021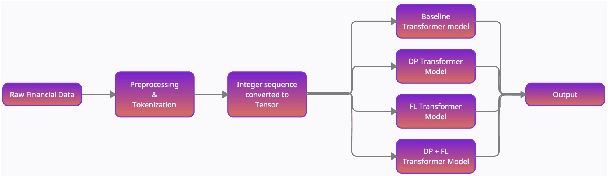
Privacy is important considering the financial Domain as such data is highly confidential and sensitive. Natural Language Processing (NLP) techniques can be applied for text classification and entity detection purposes in financial domains such as customer feedback sentiment analysis, invoice entity detection, categorisation of financial documents by type etc. Due to the sensitive nature of such data, privacy measures need to be taken for handling and training large models with such data. In this work, we propose a contextualized transformer (BERT and RoBERTa) based text classification model integrated with privacy features such as Differential Privacy (DP) and Federated Learning (FL). We present how to privately train NLP models and desirable privacy-utility tradeoffs and evaluate them on the Financial Phrase Bank dataset.
Benchmarking Differential Privacy and Federated Learning for BERT Models
Jun 26, 2021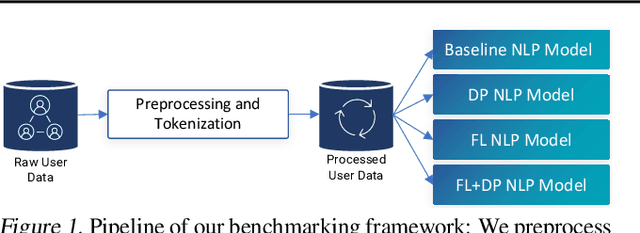
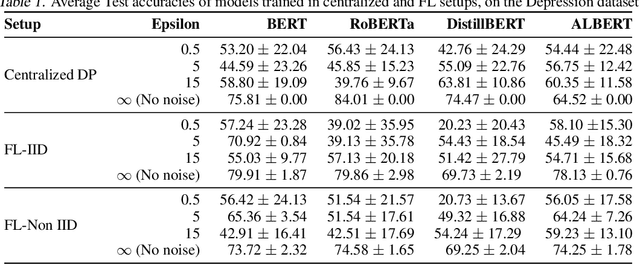
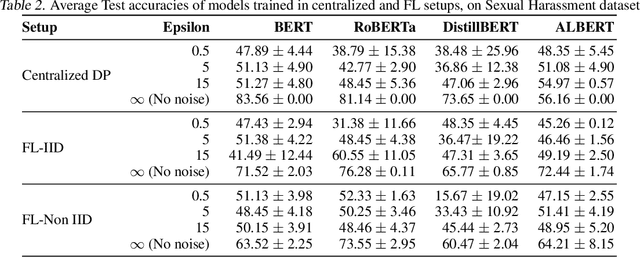
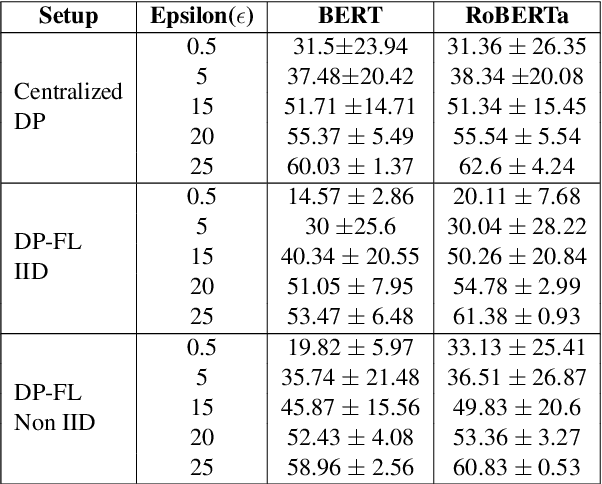
Natural Language Processing (NLP) techniques can be applied to help with the diagnosis of medical conditions such as depression, using a collection of a person's utterances. Depression is a serious medical illness that can have adverse effects on how one feels, thinks, and acts, which can lead to emotional and physical problems. Due to the sensitive nature of such data, privacy measures need to be taken for handling and training models with such data. In this work, we study the effects that the application of Differential Privacy (DP) has, in both a centralized and a Federated Learning (FL) setup, on training contextualized language models (BERT, ALBERT, RoBERTa and DistilBERT). We offer insights on how to privately train NLP models and what architectures and setups provide more desirable privacy utility trade-offs. We envisage this work to be used in future healthcare and mental health studies to keep medical history private. Therefore, we provide an open-source implementation of this work.