 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBaidu Apollo EM Motion Planner
Jul 20, 2018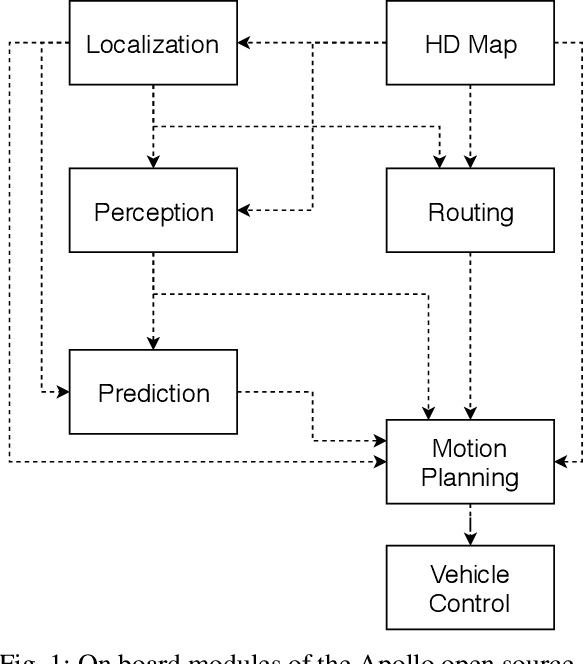
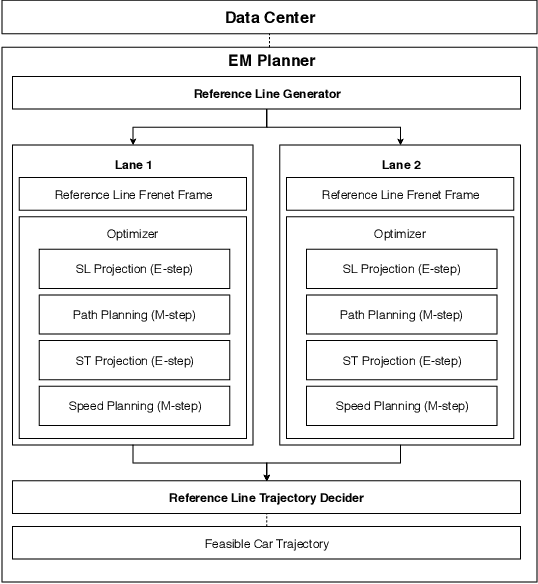
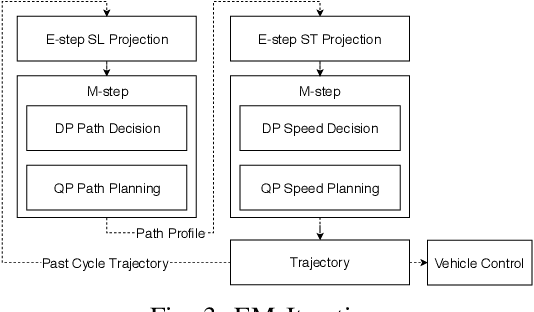

In this manuscript, we introduce a real-time motion planning system based on the Baidu Apollo (open source) autonomous driving platform. The developed system aims to address the industrial level-4 motion planning problem while considering safety, comfort and scalability. The system covers multilane and single-lane autonomous driving in a hierarchical manner: (1) The top layer of the system is a multilane strategy that handles lane-change scenarios by comparing lane-level trajectories computed in parallel. (2) Inside the lane-level trajectory generator, it iteratively solves path and speed optimization based on a Frenet frame. (3) For path and speed optimization, a combination of dynamic programming and spline-based quadratic programming is proposed to construct a scalable and easy-to-tune framework to handle traffic rules, obstacle decisions and smoothness simultaneously. The planner is scalable to both highway and lower-speed city driving scenarios. We also demonstrate the algorithm through scenario illustrations and on-road test results. The system described in this manuscript has been deployed to dozens of Baidu Apollo autonomous driving vehicles since Apollo v1.5 was announced in September 2017. As of May 16th, 2018, the system has been tested under 3,380 hours and approximately 68,000 kilometers (42,253 miles) of closed-loop autonomous driving under various urban scenarios. The algorithm described in this manuscript is available at https://github.com/ApolloAuto/apollo/tree/master/modules/planning.
CG-DIQA: No-reference Document Image Quality Assessment Based on Character Gradient
Jul 11, 2018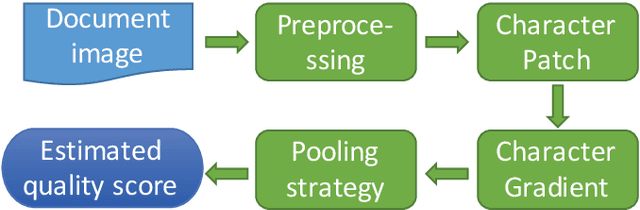


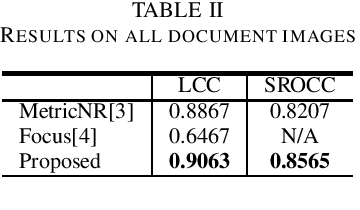
Document image quality assessment (DIQA) is an important and challenging problem in real applications. In order to predict the quality scores of document images, this paper proposes a novel no-reference DIQA method based on character gradient, where the OCR accuracy is used as a ground-truth quality metric. Character gradient is computed on character patches detected with the maximally stable extremal regions (MSER) based method. Character patches are essentially significant to character recognition and therefore suitable for use in estimating document image quality. Experiments on a benchmark dataset show that the proposed method outperforms the state-of-the-art methods in estimating the quality score of document images.