 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteracting Contour Stochastic Gradient Langevin Dynamics
Feb 20, 2022
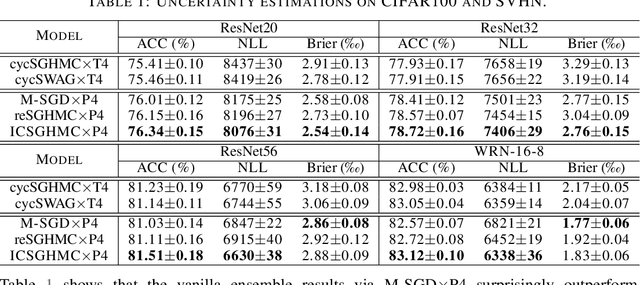
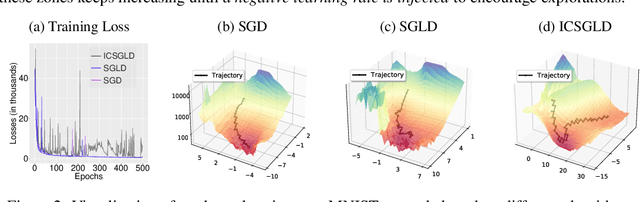

We propose an interacting contour stochastic gradient Langevin dynamics (ICSGLD) sampler, an embarrassingly parallel multiple-chain contour stochastic gradient Langevin dynamics (CSGLD) sampler with efficient interactions. We show that ICSGLD can be theoretically more efficient than a single-chain CSGLD with an equivalent computational budget. We also present a novel random-field function, which facilitates the estimation of self-adapting parameters in big data and obtains free mode explorations. Empirically, we compare the proposed algorithm with popular benchmark methods for posterior sampling. The numerical results show a great potential of ICSGLD for large-scale uncertainty estimation tasks.
A Kernel-Expanded Stochastic Neural Network
Jan 14, 2022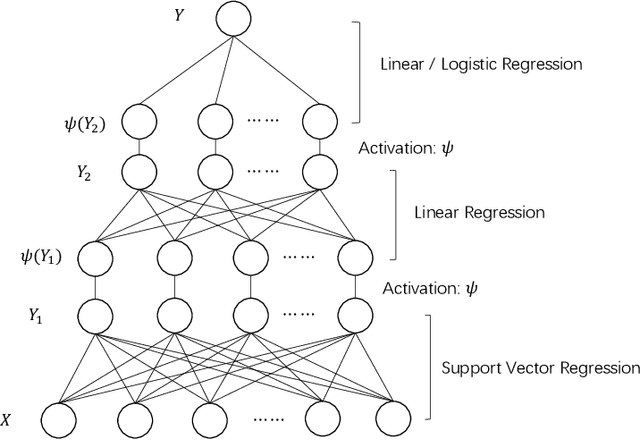
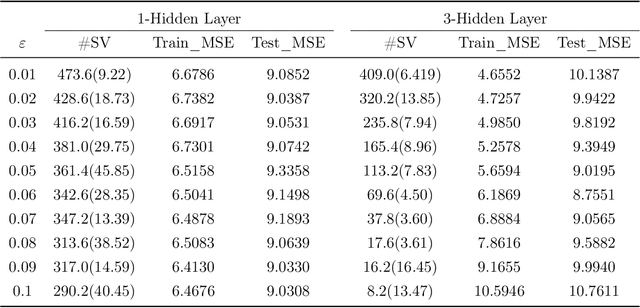
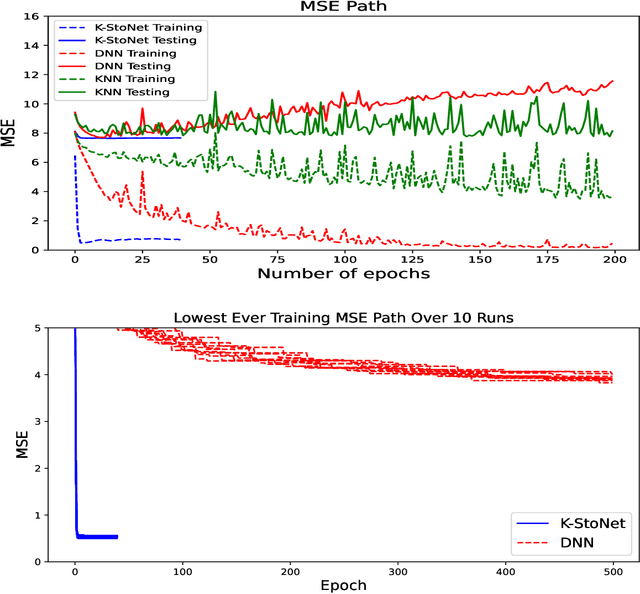
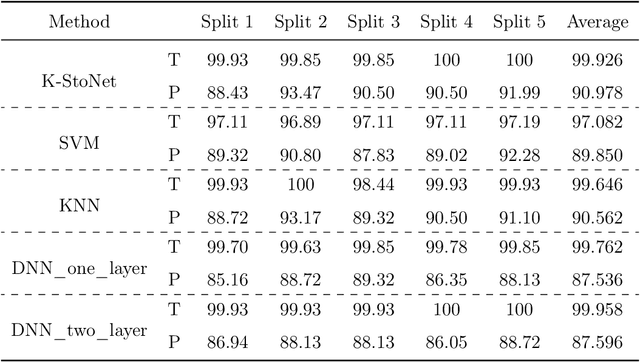
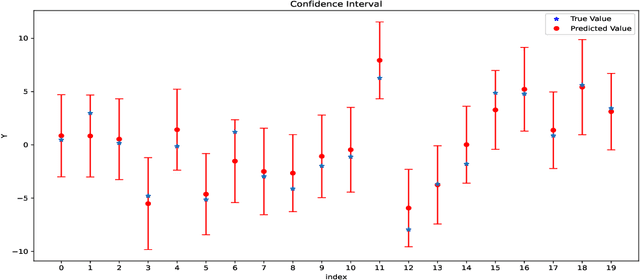
The deep neural network suffers from many fundamental issues in machine learning. For example, it often gets trapped into a local minimum in training, and its prediction uncertainty is hard to be assessed. To address these issues, we propose the so-called kernel-expanded stochastic neural network (K-StoNet) model, which incorporates support vector regression (SVR) as the first hidden layer and reformulates the neural network as a latent variable model. The former maps the input vector into an infinite dimensional feature space via a radial basis function (RBF) kernel, ensuring absence of local minima on its training loss surface. The latter breaks the high-dimensional nonconvex neural network training problem into a series of low-dimensional convex optimization problems, and enables its prediction uncertainty easily assessed. The K-StoNet can be easily trained using the imputation-regularized optimization (IRO) algorithm. Compared to traditional deep neural networks, K-StoNet possesses a theoretical guarantee to asymptotically converge to the global optimum and enables the prediction uncertainty easily assessed. The performances of the new model in training, prediction and uncertainty quantification are illustrated by simulated and real data examples.
Sparse Deep Learning: A New Framework Immune to Local Traps and Miscalibration
Oct 01, 2021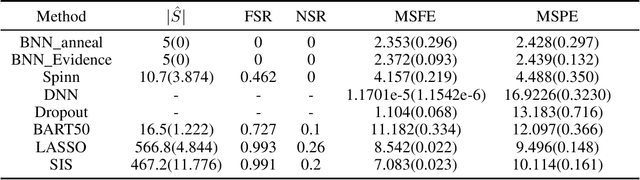
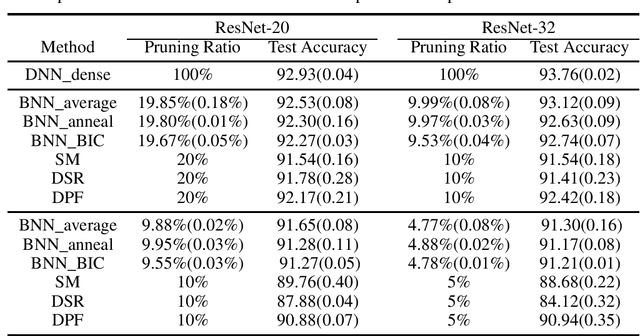
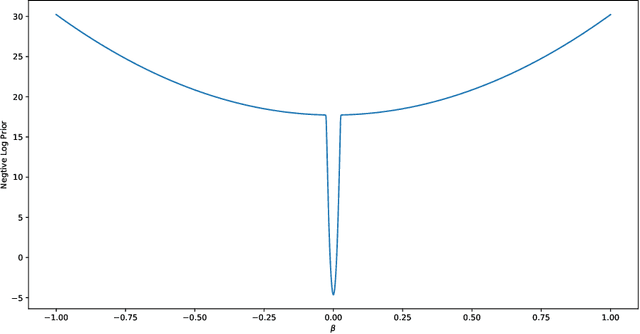
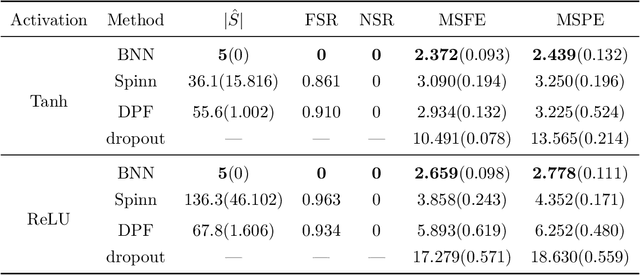
Deep learning has powered recent successes of artificial intelligence (AI). However, the deep neural network, as the basic model of deep learning, has suffered from issues such as local traps and miscalibration. In this paper, we provide a new framework for sparse deep learning, which has the above issues addressed in a coherent way. In particular, we lay down a theoretical foundation for sparse deep learning and propose prior annealing algorithms for learning sparse neural networks. The former has successfully tamed the sparse deep neural network into the framework of statistical modeling, enabling prediction uncertainty correctly quantified. The latter can be asymptotically guaranteed to converge to the global optimum, enabling the validity of the down-stream statistical inference. Numerical result indicates the superiority of the proposed method compared to the existing ones.
Consistent Sparse Deep Learning: Theory and Computation
Mar 08, 2021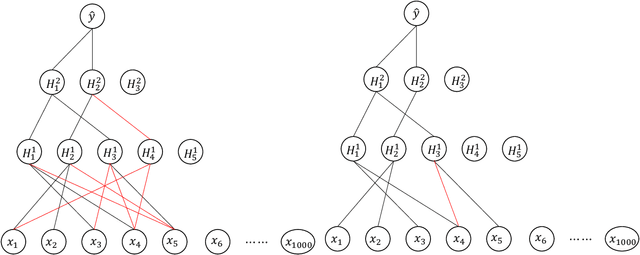
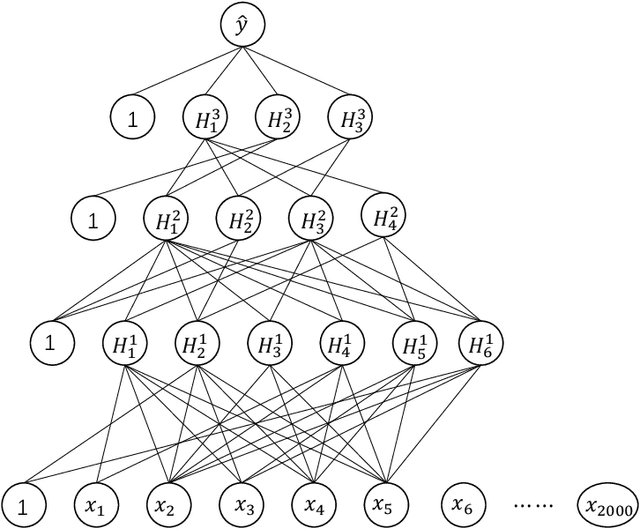
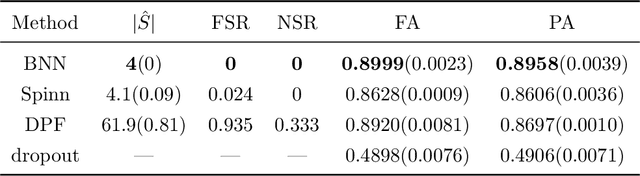
Deep learning has been the engine powering many successes of data science. However, the deep neural network (DNN), as the basic model of deep learning, is often excessively over-parameterized, causing many difficulties in training, prediction and interpretation. We propose a frequentist-like method for learning sparse DNNs and justify its consistency under the Bayesian framework: the proposed method could learn a sparse DNN with at most $O(n/\log(n))$ connections and nice theoretical guarantees such as posterior consistency, variable selection consistency and asymptotically optimal generalization bounds. In particular, we establish posterior consistency for the sparse DNN with a mixture Gaussian prior, show that the structure of the sparse DNN can be consistently determined using a Laplace approximation-based marginal posterior inclusion probability approach, and use Bayesian evidence to elicit sparse DNNs learned by an optimization method such as stochastic gradient descent in multiple runs with different initializations. The proposed method is computationally more efficient than standard Bayesian methods for large-scale sparse DNNs. The numerical results indicate that the proposed method can perform very well for large-scale network compression and high-dimensional nonlinear variable selection, both advancing interpretable machine learning.
A Contour Stochastic Gradient Langevin Dynamics Algorithm for Simulations of Multi-modal Distributions
Oct 19, 2020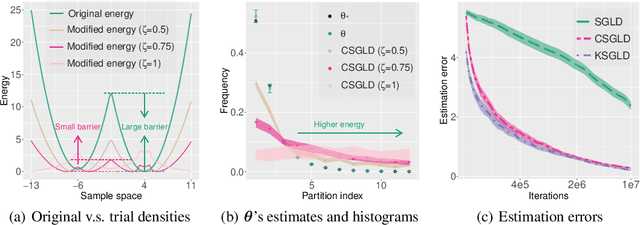
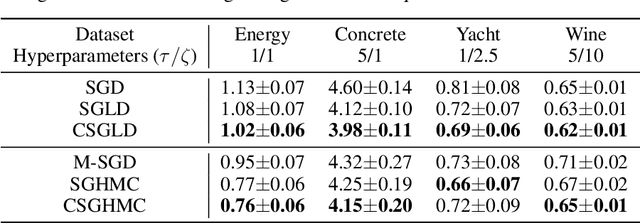

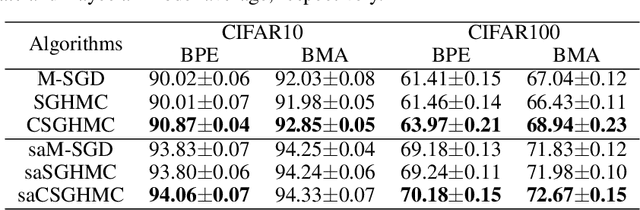
We propose an adaptively weighted stochastic gradient Langevin dynamics algorithm (SGLD), so-called contour stochastic gradient Langevin dynamics (CSGLD), for Bayesian learning in big data statistics. The proposed algorithm is essentially a \emph{scalable dynamic importance sampler}, which automatically \emph{flattens} the target distribution such that the simulation for a multi-modal distribution can be greatly facilitated. Theoretically, we prove a stability condition and establish the asymptotic convergence of the self-adapting parameter to a {\it unique fixed-point}, regardless of the non-convexity of the original energy function; we also present an error analysis for the weighted averaging estimators. Empirically, the CSGLD algorithm is tested on multiple benchmark datasets including CIFAR10 and CIFAR100. The numerical results indicate its superiority over the existing state-of-the-art algorithms in training deep neural networks.
Accelerating Convergence of Replica Exchange Stochastic Gradient MCMC via Variance Reduction
Oct 02, 2020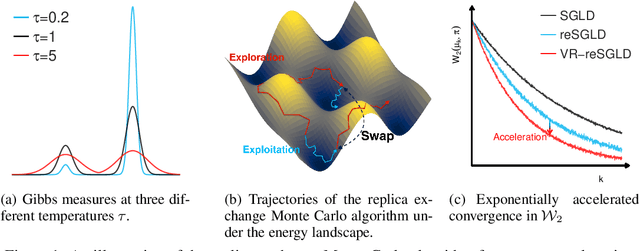
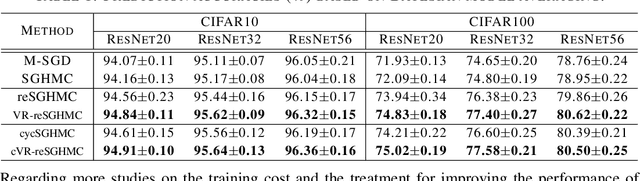
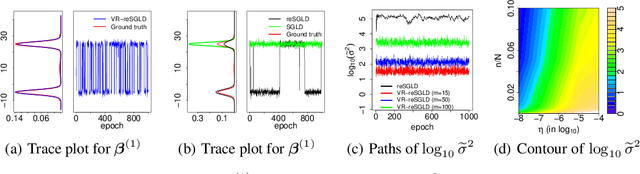
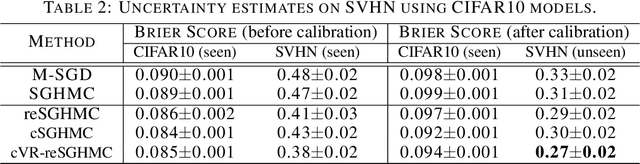
Replica exchange stochastic gradient Langevin dynamics (reSGLD) has shown promise in accelerating the convergence in non-convex learning; however, an excessively large correction for avoiding biases from noisy energy estimators has limited the potential of the acceleration. To address this issue, we study the variance reduction for noisy energy estimators, which promotes much more effective swaps. Theoretically, we provide a non-asymptotic analysis on the exponential acceleration for the underlying continuous-time Markov jump process; moreover, we consider a generalized Girsanov theorem which includes the change of Poisson measure to overcome the crude discretization based on the Gr\"{o}wall's inequality and yields a much tighter error in the 2-Wasserstein ($\mathcal{W}_2$) distance. Numerically, we conduct extensive experiments and obtain the state-of-the-art results in optimization and uncertainty estimates for synthetic experiments and image data.
Stochastic Gradient Langevin Dynamics Algorithms with Adaptive Drifts
Sep 20, 2020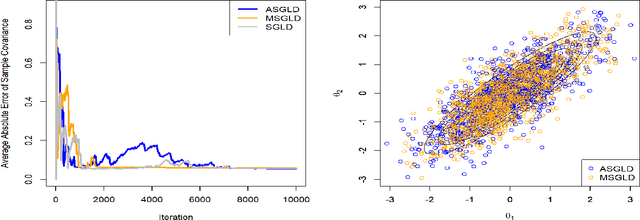
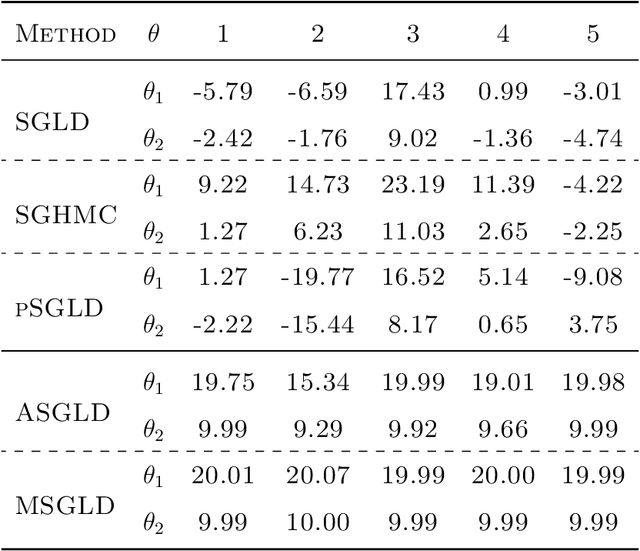
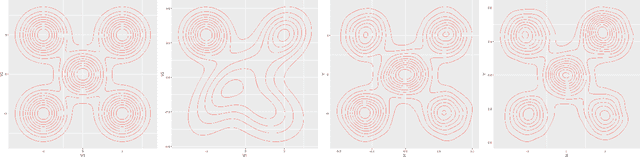
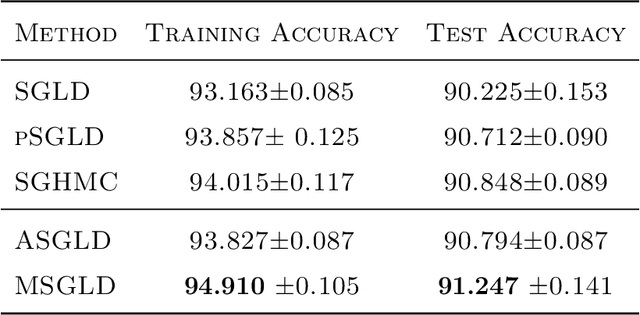
Bayesian deep learning offers a principled way to address many issues concerning safety of artificial intelligence (AI), such as model uncertainty,model interpretability, and prediction bias. However, due to the lack of efficient Monte Carlo algorithms for sampling from the posterior of deep neural networks (DNNs), Bayesian deep learning has not yet powered our AI system. We propose a class of adaptive stochastic gradient Markov chain Monte Carlo (SGMCMC) algorithms, where the drift function is biased to enhance escape from saddle points and the bias is adaptively adjusted according to the gradient of past samples. We establish the convergence of the proposed algorithms under mild conditions, and demonstrate via numerical examples that the proposed algorithms can significantly outperform the existing SGMCMC algorithms, such as stochastic gradient Langevin dynamics (SGLD), stochastic gradient Hamiltonian Monte Carlo (SGHMC) and preconditioned SGLD, in both simulation and optimization tasks.
Non-convex Learning via Replica Exchange Stochastic Gradient MCMC
Sep 10, 2020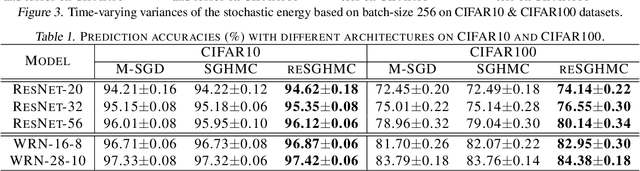
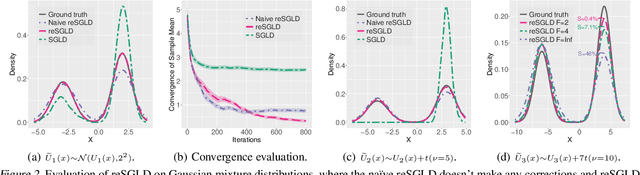
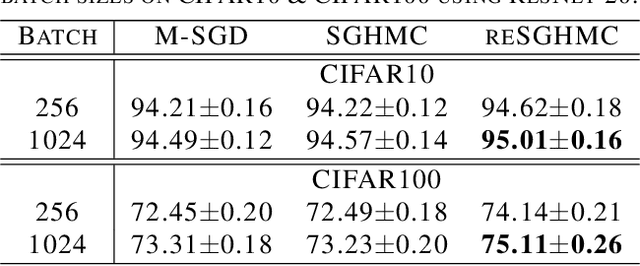
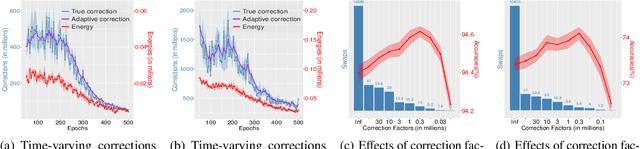
Replica exchange Monte Carlo (reMC), also known as parallel tempering, is an important technique for accelerating the convergence of the conventional Markov Chain Monte Carlo (MCMC) algorithms. However, such a method requires the evaluation of the energy function based on the full dataset and is not scalable to big data. The na\"ive implementation of reMC in mini-batch settings introduces large biases, which cannot be directly extended to the stochastic gradient MCMC (SGMCMC), the standard sampling method for simulating from deep neural networks (DNNs). In this paper, we propose an adaptive replica exchange SGMCMC (reSGMCMC) to automatically correct the bias and study the corresponding properties. The analysis implies an acceleration-accuracy trade-off in the numerical discretization of a Markov jump process in a stochastic environment. Empirically, we test the algorithm through extensive experiments on various setups and obtain the state-of-the-art results on CIFAR10, CIFAR100, and SVHN in both supervised learning and semi-supervised learning tasks.
Extended Stochastic Gradient MCMC for Large-Scale Bayesian Variable Selection
Feb 07, 2020
Stochastic gradient Markov chain Monte Carlo (MCMC) algorithms have received much attention in Bayesian computing for big data problems, but they are only applicable to a small class of problems for which the parameter space has a fixed dimension and the log-posterior density is differentiable with respect to the parameters. This paper proposes an extended stochastic gradient MCMC lgoriathm which, by introducing appropriate latent variables, can be applied to more general large-scale Bayesian computing problems, such as those involving dimension jumping and missing data. Numerical studies show that the proposed algorithm is highly scalable and much more efficient than traditional MCMC algorithms. The proposed algorithms have much alleviated the pain of Bayesian methods in big data computing.
An Adaptive Empirical Bayesian Method for Sparse Deep Learning
Oct 23, 2019
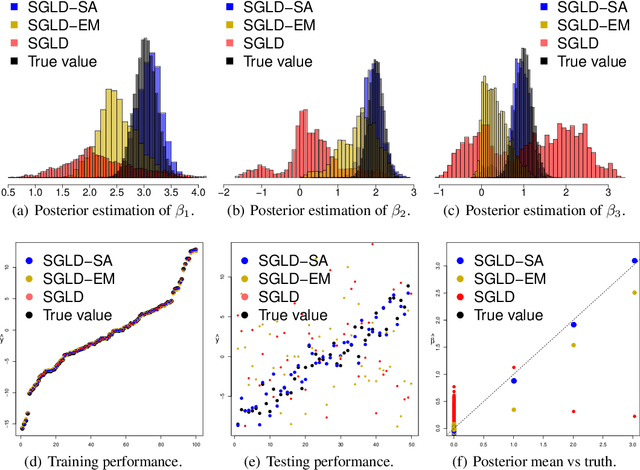
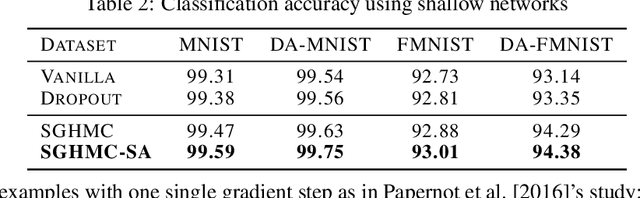
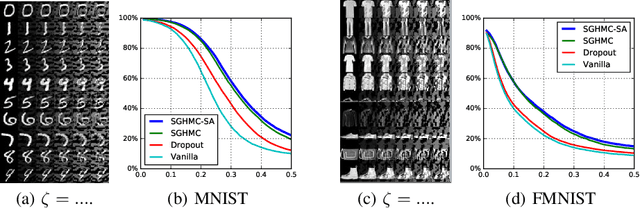
We propose a novel adaptive empirical Bayesian (AEB) method for sparse deep learning, where the sparsity is ensured via a class of self-adaptive spike-and-slab priors. The proposed method works by alternatively sampling from an adaptive hierarchical posterior distribution using stochastic gradient Markov Chain Monte Carlo (MCMC) and smoothly optimizing the hyperparameters using stochastic approximation (SA). We further prove the convergence of the proposed method to the asymptotically correct distribution under mild conditions. Empirical applications of the proposed method lead to the state-of-the-art performance on MNIST and Fashion MNIST with shallow convolutional neural networks (CNN) and the state-of-the-art compression performance on CIFAR10 with Residual Networks. The proposed method also improves resistance to adversarial attacks.