 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHM-NAS: Efficient Neural Architecture Search via Hierarchical Masking
Sep 07, 2019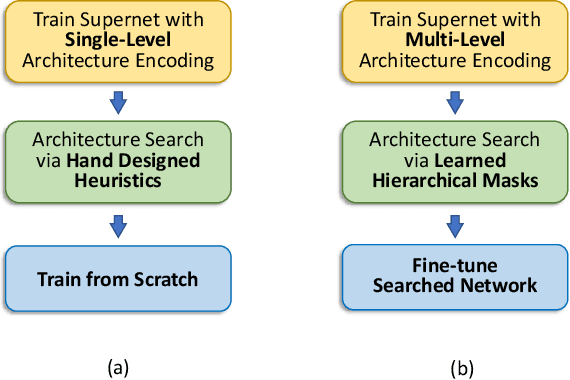
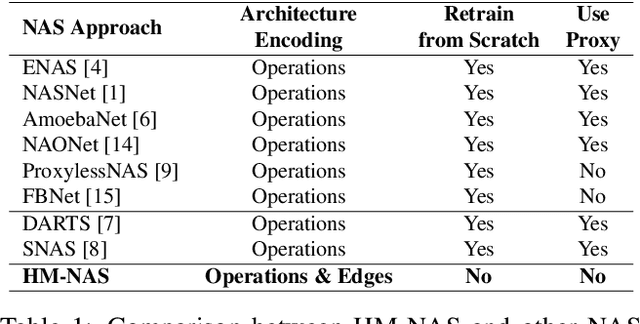
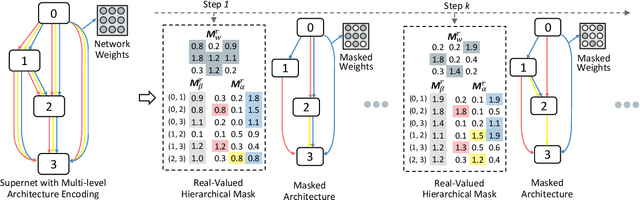
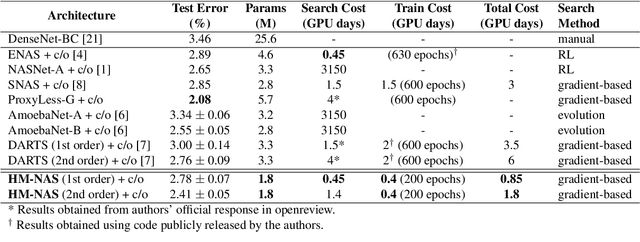
The use of automatic methods, often referred to as Neural Architecture Search (NAS), in designing neural network architectures has recently drawn considerable attention. In this work, we present an efficient NAS approach, named HM- NAS, that generalizes existing weight sharing based NAS approaches. Existing weight sharing based NAS approaches still adopt hand-designed heuristics to generate architecture candidates. As a consequence, the space of architecture candidates is constrained in a subset of all possible architectures, making the architecture search results sub-optimal. HM-NAS addresses this limitation via two innovations. First, HM-NAS incorporates a multi-level architecture encoding scheme to enable searching for more flexible network architectures. Second, it discards the hand-designed heuristics and incorporates a hierarchical masking scheme that automatically learns and determines the optimal architecture. Compared to state-of-the-art weight sharing based approaches, HM-NAS is able to achieve better architecture search performance and competitive model evaluation accuracy. Without the constraint imposed by the hand-designed heuristics, our searched networks contain more flexible and meaningful architectures that existing weight sharing based NAS approaches are not able to discover.
Accurate Face Detection for High Performance
May 24, 2019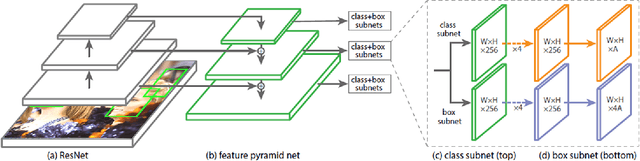

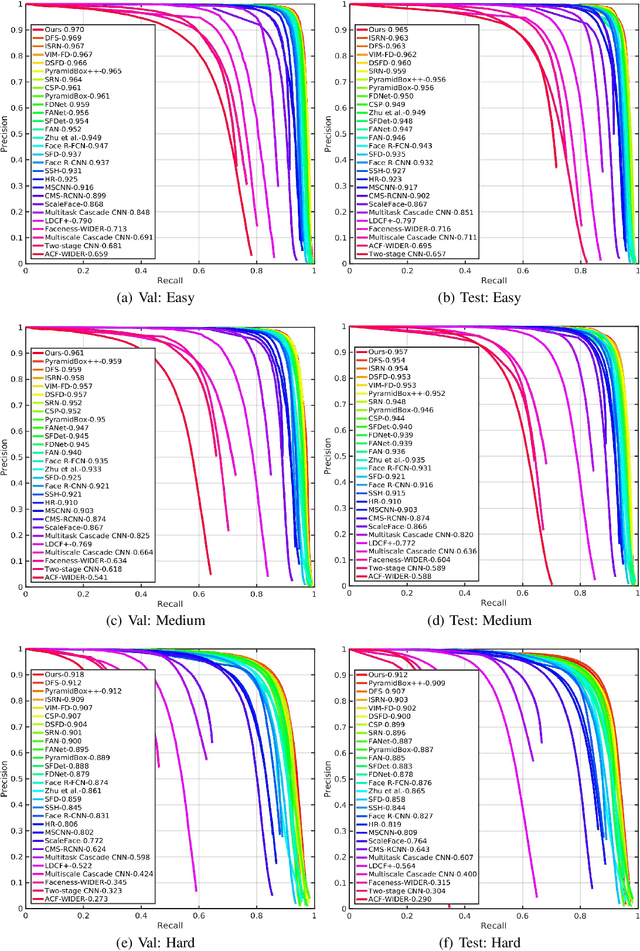
Face detection has witnessed significant progress due to the advances of deep convolutional neural networks (CNNs). Its central issue in recent years is how to improve the detection performance of tiny faces. To this end, many recent works propose some specific strategies, redesign the architecture and introduce new loss functions for tiny object detection. In this report, we start from the popular one-stage RetinaNet approach and apply some recent tricks to obtain a high performance face detector. Specifically, we apply the Intersection over Union (IoU) loss function for regression, employ the two-step classification and regression for detection, revisit the data augmentation based on data-anchor-sampling for training, utilize the max-out operation for classification and use the multi-scale testing strategy for inference. As a consequence, the proposed face detection method achieves state-of-the-art performance on the most popular and challenging face detection benchmark WIDER FACE dataset.