 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoregressive Search Engines: Generating Substrings as Document Identifiers
Apr 22, 2022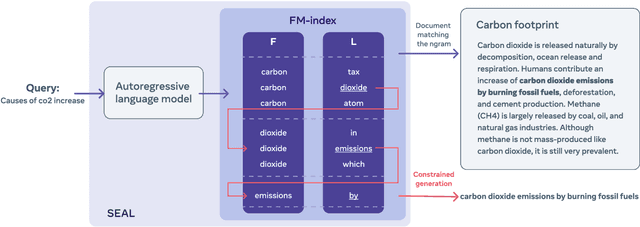
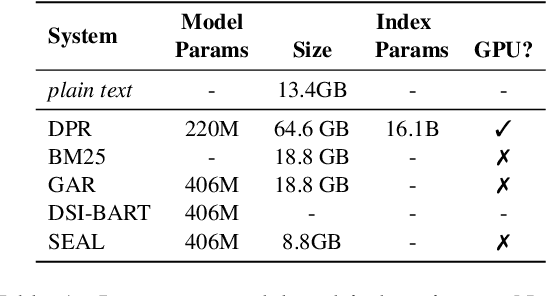
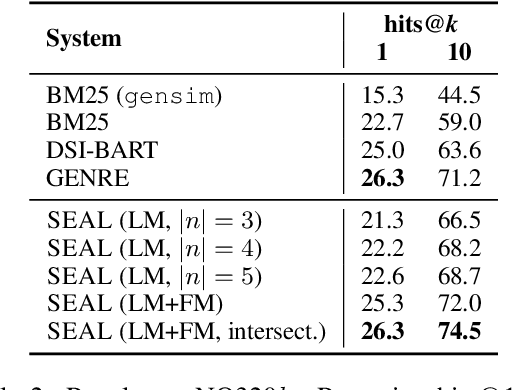
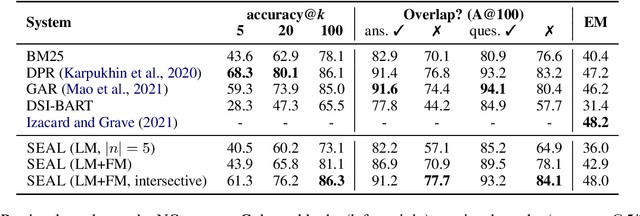
Knowledge-intensive language tasks require NLP systems to both provide the correct answer and retrieve supporting evidence for it in a given corpus. Autoregressive language models are emerging as the de-facto standard for generating answers, with newer and more powerful systems emerging at an astonishing pace. In this paper we argue that all this (and future) progress can be directly applied to the retrieval problem with minimal intervention to the models' architecture. Previous work has explored ways to partition the search space into hierarchical structures and retrieve documents by autoregressively generating their unique identifier. In this work we propose an alternative that doesn't force any structure in the search space: using all ngrams in a passage as its possible identifiers. This setup allows us to use an autoregressive model to generate and score distinctive ngrams, that are then mapped to full passages through an efficient data structure. Empirically, we show this not only outperforms prior autoregressive approaches but also leads to an average improvement of at least 10 points over more established retrieval solutions for passage-level retrieval on the KILT benchmark, establishing new state-of-the-art downstream performance on some datasets, while using a considerably lighter memory footprint than competing systems. Code and pre-trained models at https://github.com/facebookresearch/SEAL.
Learning To Recognize Procedural Activities with Distant Supervision
Jan 26, 2022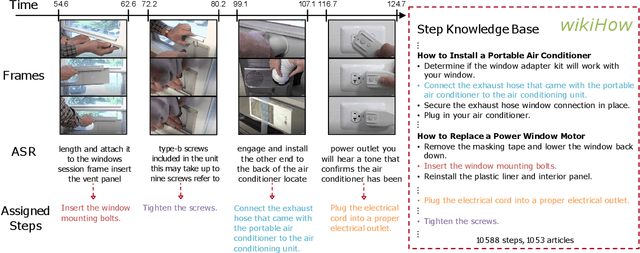

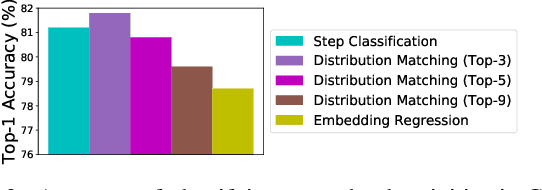

In this paper we consider the problem of classifying fine-grained, multi-step activities (e.g., cooking different recipes, making disparate home improvements, creating various forms of arts and crafts) from long videos spanning up to several minutes. Accurately categorizing these activities requires not only recognizing the individual steps that compose the task but also capturing their temporal dependencies. This problem is dramatically different from traditional action classification, where models are typically optimized on videos that span only a few seconds and that are manually trimmed to contain simple atomic actions. While step annotations could enable the training of models to recognize the individual steps of procedural activities, existing large-scale datasets in this area do not include such segment labels due to the prohibitive cost of manually annotating temporal boundaries in long videos. To address this issue, we propose to automatically identify steps in instructional videos by leveraging the distant supervision of a textual knowledge base (wikiHow) that includes detailed descriptions of the steps needed for the execution of a wide variety of complex activities. Our method uses a language model to match noisy, automatically-transcribed speech from the video to step descriptions in the knowledge base. We demonstrate that video models trained to recognize these automatically-labeled steps (without manual supervision) yield a representation that achieves superior generalization performance on four downstream tasks: recognition of procedural activities, step classification, step forecasting and egocentric video classification.
The Web Is Your Oyster -- Knowledge-Intensive NLP against a Very Large Web Corpus
Dec 18, 2021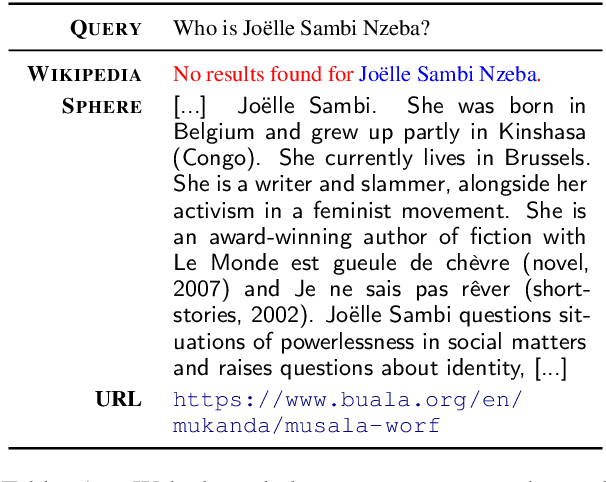
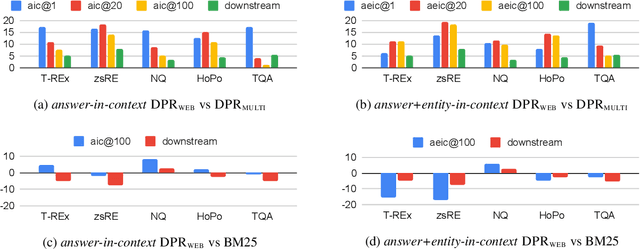
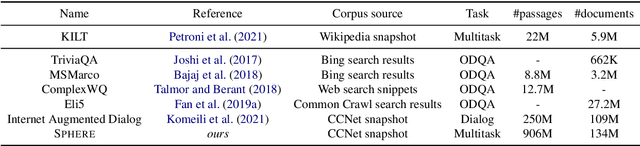
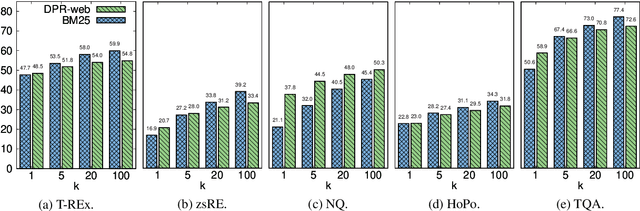
In order to address the increasing demands of real-world applications, the research for knowledge-intensive NLP (KI-NLP) should advance by capturing the challenges of a truly open-domain environment: web scale knowledge, lack of structure, inconsistent quality, and noise. To this end, we propose a new setup for evaluating existing KI-NLP tasks in which we generalize the background corpus to a universal web snapshot. We repurpose KILT, a standard KI-NLP benchmark initially developed for Wikipedia, and ask systems to use a subset of CCNet - the Sphere corpus - as a knowledge source. In contrast to Wikipedia, Sphere is orders of magnitude larger and better reflects the full diversity of knowledge on the Internet. We find that despite potential gaps of coverage, challenges of scale, lack of structure and lower quality, retrieval from Sphere enables a state-of-the-art retrieve-and-read system to match and even outperform Wikipedia-based models on several KILT tasks - even if we aggressively filter content that looks like Wikipedia. We also observe that while a single dense passage index over Wikipedia can outperform a sparse BM25 version, on Sphere this is not yet possible. To facilitate further research into this area, and minimise the community's reliance on proprietary black box search engines, we will share our indices, evaluation metrics and infrastructure.
Boosted Dense Retriever
Dec 14, 2021
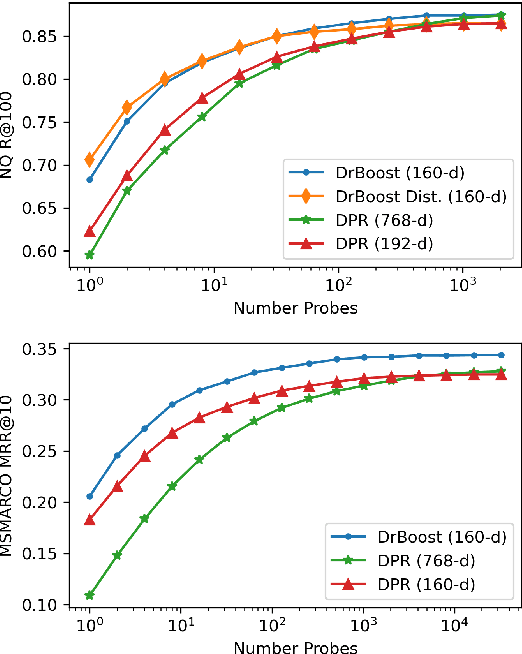

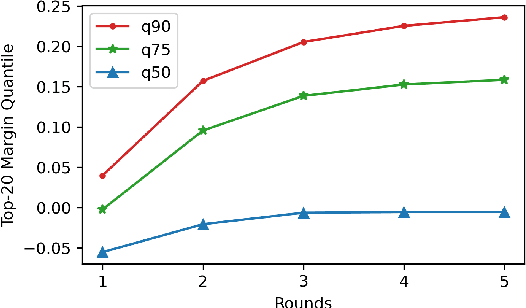
We propose DrBoost, a dense retrieval ensemble inspired by boosting. DrBoost is trained in stages: each component model is learned sequentially and specialized by focusing only on retrieval mistakes made by the current ensemble. The final representation is the concatenation of the output vectors of all the component models, making it a drop-in replacement for standard dense retrievers at test time. DrBoost enjoys several advantages compared to standard dense retrieval models. It produces representations which are 4x more compact, while delivering comparable retrieval results. It also performs surprisingly well under approximate search with coarse quantization, reducing latency and bandwidth needs by another 4x. In practice, this can make the difference between serving indices from disk versus from memory, paving the way for much cheaper deployments.
MiniHack the Planet: A Sandbox for Open-Ended Reinforcement Learning Research
Sep 27, 2021
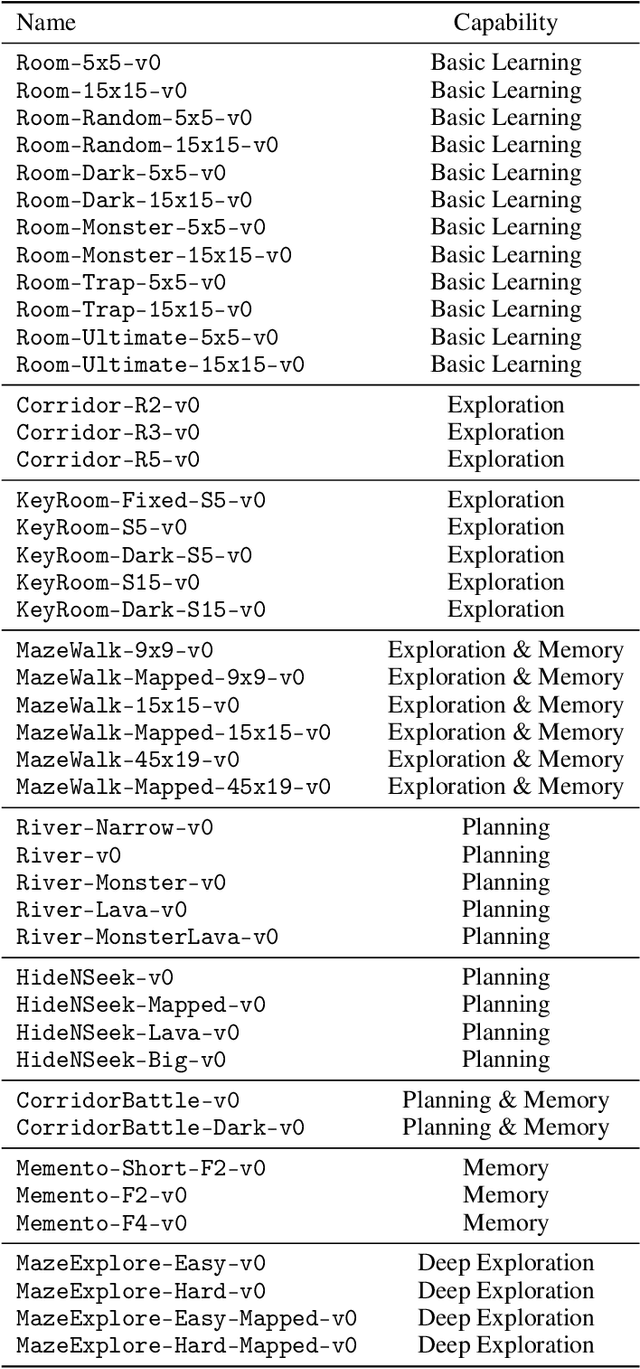

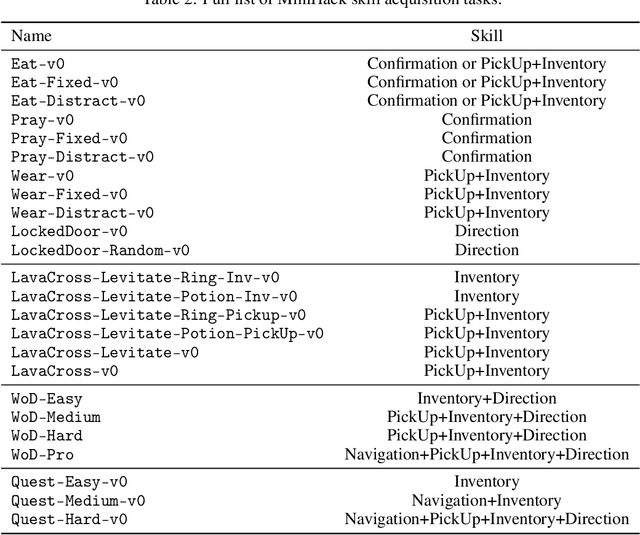
The progress in deep reinforcement learning (RL) is heavily driven by the availability of challenging benchmarks used for training agents. However, benchmarks that are widely adopted by the community are not explicitly designed for evaluating specific capabilities of RL methods. While there exist environments for assessing particular open problems in RL (such as exploration, transfer learning, unsupervised environment design, or even language-assisted RL), it is generally difficult to extend these to richer, more complex environments once research goes beyond proof-of-concept results. We present MiniHack, a powerful sandbox framework for easily designing novel RL environments. MiniHack is a one-stop shop for RL experiments with environments ranging from small rooms to complex, procedurally generated worlds. By leveraging the full set of entities and environment dynamics from NetHack, one of the richest grid-based video games, MiniHack allows designing custom RL testbeds that are fast and convenient to use. With this sandbox framework, novel environments can be designed easily, either using a human-readable description language or a simple Python interface. In addition to a variety of RL tasks and baselines, MiniHack can wrap existing RL benchmarks and provide ways to seamlessly add additional complexity.
Cutting Down on Prompts and Parameters: Simple Few-Shot Learning with Language Models
Jul 01, 2021
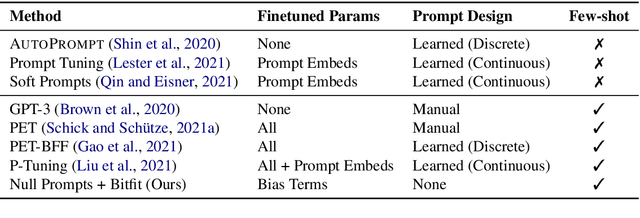
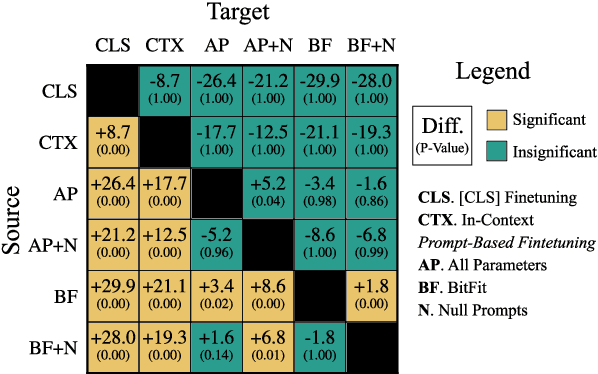
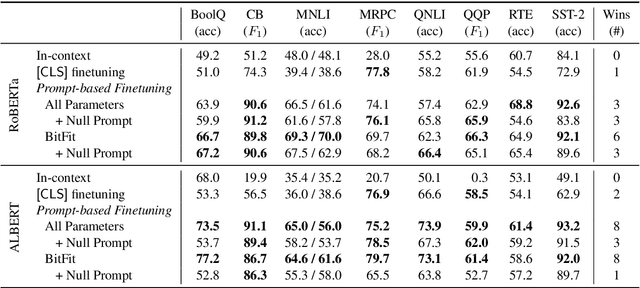
Prompting language models (LMs) with training examples and task descriptions has been seen as critical to recent successes in few-shot learning. In this work, we show that finetuning LMs in the few-shot setting can considerably reduce the need for prompt engineering. In fact, one can use null prompts, prompts that contain neither task-specific templates nor training examples, and achieve competitive accuracy to manually-tuned prompts across a wide range of tasks. While finetuning LMs does introduce new parameters for each downstream task, we show that this memory overhead can be substantially reduced: finetuning only the bias terms can achieve comparable or better accuracy than standard finetuning while only updating 0.1% of the parameters. All in all, we recommend finetuning LMs for few-shot learning as it is more accurate, robust to different prompts, and can be made nearly as efficient as using frozen LMs.
CycleDRUMS: Automatic Drum Arrangement For Bass Lines Using CycleGAN
Apr 09, 2021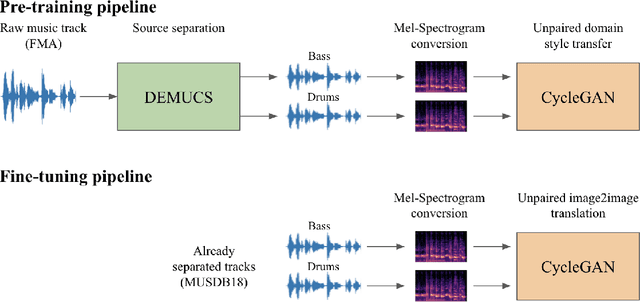
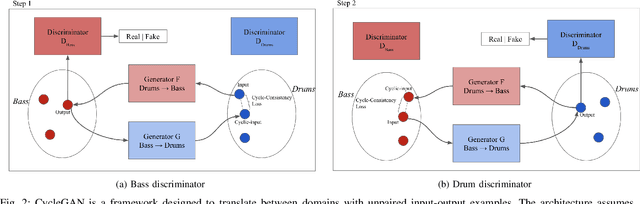
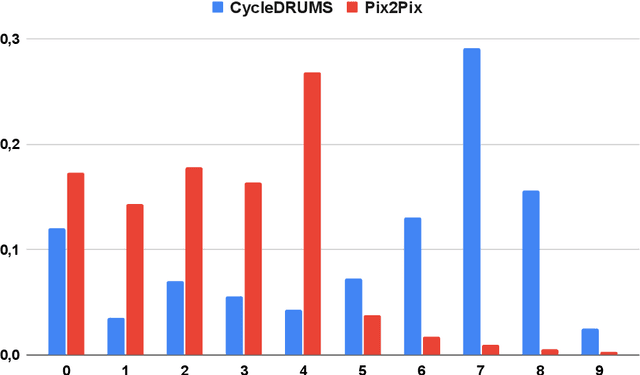
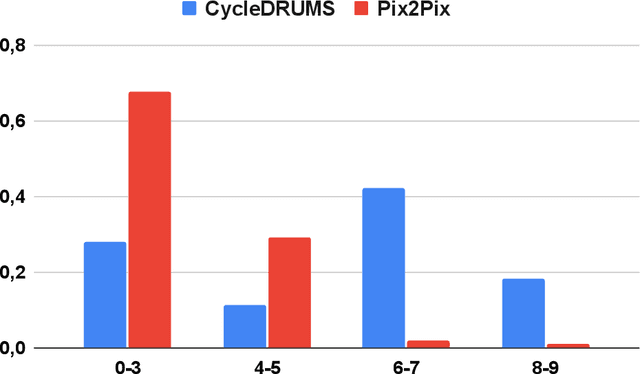
The two main research threads in computer-based music generation are: the construction of autonomous music-making systems, and the design of computer-based environments to assist musicians. In the symbolic domain, the key problem of automatically arranging a piece music was extensively studied, while relatively fewer systems tackled this challenge in the audio domain. In this contribution, we propose CycleDRUMS, a novel method for generating drums given a bass line. After converting the waveform of the bass into a mel-spectrogram, we are able to automatically generate original drums that follow the beat, sound credible and can be directly mixed with the input bass. We formulated this task as an unpaired image-to-image translation problem, and we addressed it with CycleGAN, a well-established unsupervised style transfer framework, originally designed for treating images. The choice to deploy raw audio and mel-spectrograms enabled us to better represent how humans perceive music, and to potentially draw sounds for new arrangements from the vast collection of music recordings accumulated in the last century. In absence of an objective way of evaluating the output of both generative adversarial networks and music generative systems, we further defined a possible metric for the proposed task, partially based on human (and expert) judgement. Finally, as a comparison, we replicated our results with Pix2Pix, a paired image-to-image translation network, and we showed that our approach outperforms it.
Multilingual Autoregressive Entity Linking
Mar 23, 2021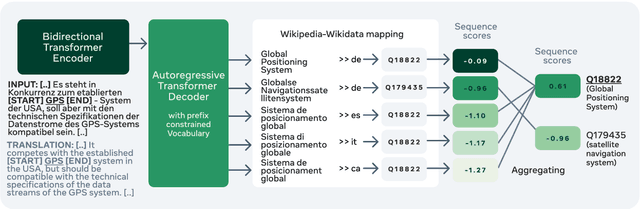
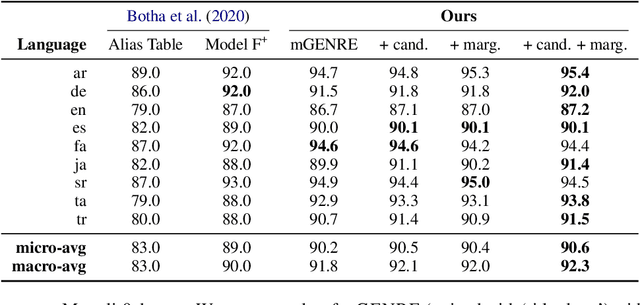
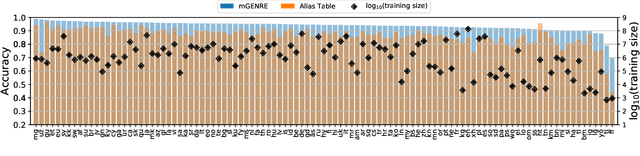
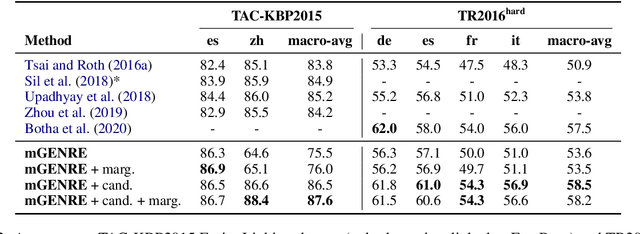
We present mGENRE, a sequence-to-sequence system for the Multilingual Entity Linking (MEL) problem -- the task of resolving language-specific mentions to a multilingual Knowledge Base (KB). For a mention in a given language, mGENRE predicts the name of the target entity left-to-right, token-by-token in an autoregressive fashion. The autoregressive formulation allows us to effectively cross-encode mention string and entity names to capture more interactions than the standard dot product between mention and entity vectors. It also enables fast search within a large KB even for mentions that do not appear in mention tables and with no need for large-scale vector indices. While prior MEL works use a single representation for each entity, we match against entity names of as many languages as possible, which allows exploiting language connections between source input and target name. Moreover, in a zero-shot setting on languages with no training data at all, mGENRE treats the target language as a latent variable that is marginalized at prediction time. This leads to over 50% improvements in average accuracy. We show the efficacy of our approach through extensive evaluation including experiments on three popular MEL benchmarks where mGENRE establishes new state-of-the-art results. Code and pre-trained models at https://github.com/facebookresearch/GENRE.
NeurIPS 2020 EfficientQA Competition: Systems, Analyses and Lessons Learned
Jan 01, 2021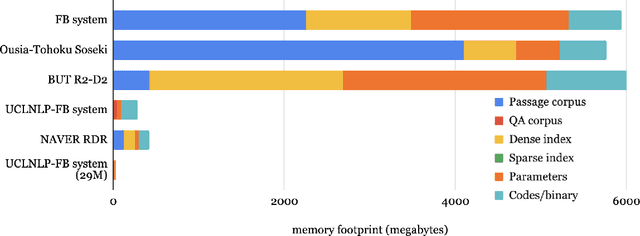
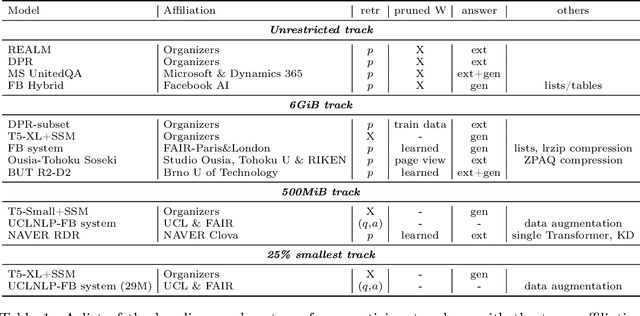
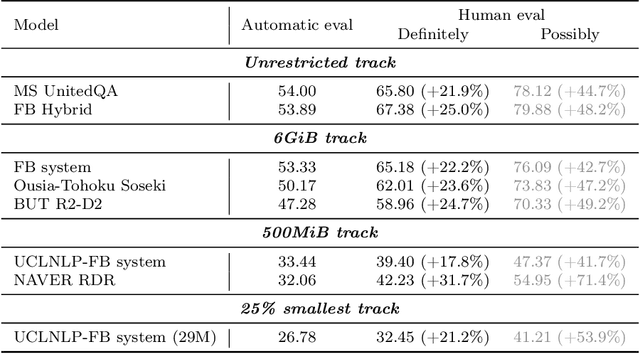
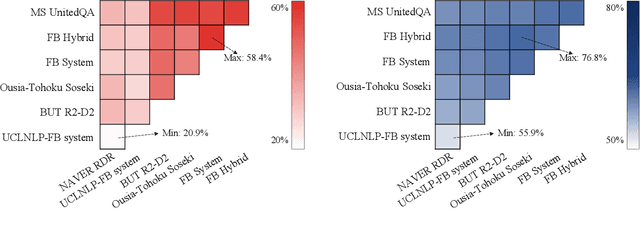
We review the EfficientQA competition from NeurIPS 2020. The competition focused on open-domain question answering (QA), where systems take natural language questions as input and return natural language answers. The aim of the competition was to build systems that can predict correct answers while also satisfying strict on-disk memory budgets. These memory budgets were designed to encourage contestants to explore the trade-off between storing large, redundant, retrieval corpora or the parameters of large learned models. In this report, we describe the motivation and organization of the competition, review the best submissions, and analyze system predictions to inform a discussion of evaluation for open-domain QA.
Multi-task Retrieval for Knowledge-Intensive Tasks
Jan 01, 2021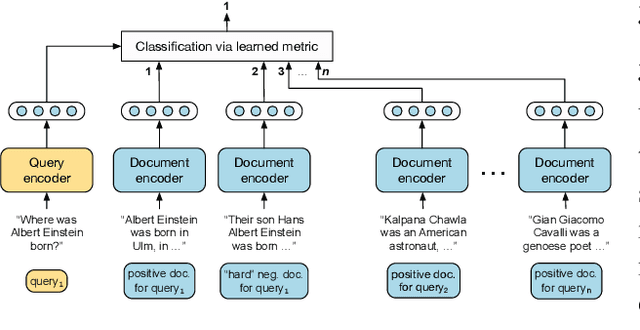

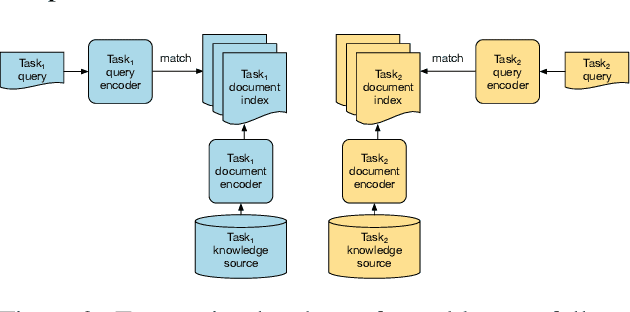
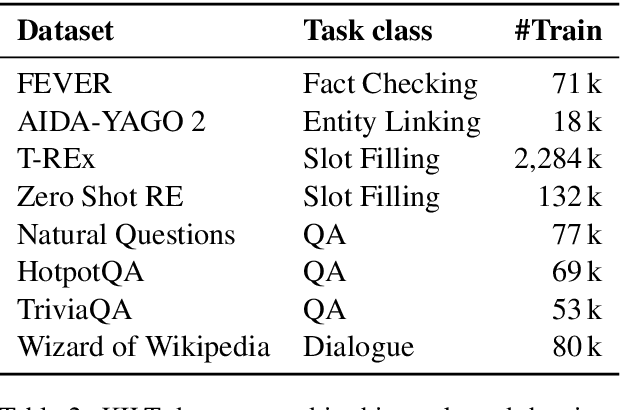
Retrieving relevant contexts from a large corpus is a crucial step for tasks such as open-domain question answering and fact checking. Although neural retrieval outperforms traditional methods like tf-idf and BM25, its performance degrades considerably when applied to out-of-domain data. Driven by the question of whether a neural retrieval model can be universal and perform robustly on a wide variety of problems, we propose a multi-task trained model. Our approach not only outperforms previous methods in the few-shot setting, but also rivals specialised neural retrievers, even when in-domain training data is abundant. With the help of our retriever, we improve existing models for downstream tasks and closely match or improve the state of the art on multiple benchmarks.