 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Web Is Your Oyster -- Knowledge-Intensive NLP against a Very Large Web Corpus
Paper and Code
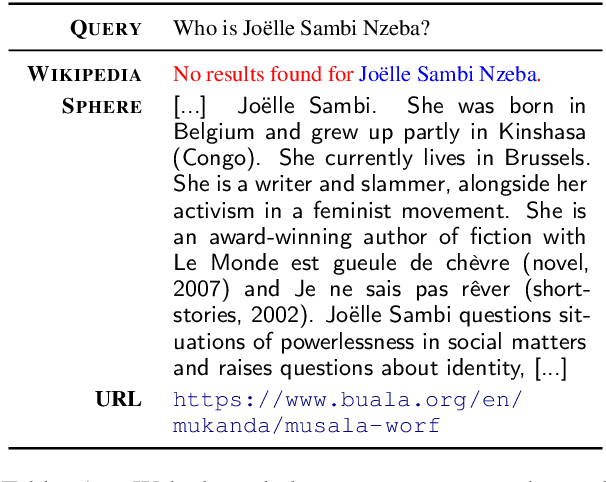
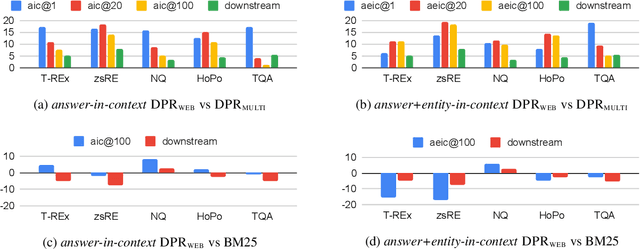
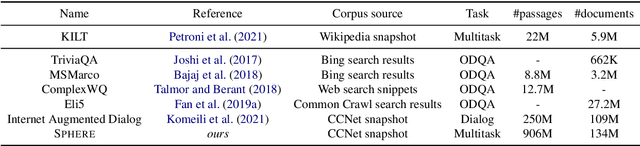
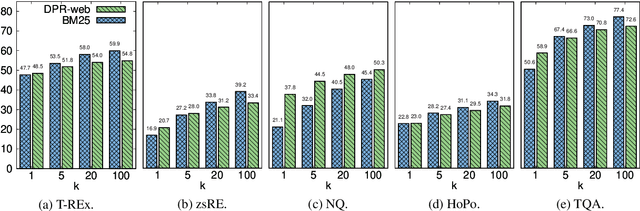
In order to address the increasing demands of real-world applications, the research for knowledge-intensive NLP (KI-NLP) should advance by capturing the challenges of a truly open-domain environment: web scale knowledge, lack of structure, inconsistent quality, and noise. To this end, we propose a new setup for evaluating existing KI-NLP tasks in which we generalize the background corpus to a universal web snapshot. We repurpose KILT, a standard KI-NLP benchmark initially developed for Wikipedia, and ask systems to use a subset of CCNet - the Sphere corpus - as a knowledge source. In contrast to Wikipedia, Sphere is orders of magnitude larger and better reflects the full diversity of knowledge on the Internet. We find that despite potential gaps of coverage, challenges of scale, lack of structure and lower quality, retrieval from Sphere enables a state-of-the-art retrieve-and-read system to match and even outperform Wikipedia-based models on several KILT tasks - even if we aggressively filter content that looks like Wikipedia. We also observe that while a single dense passage index over Wikipedia can outperform a sparse BM25 version, on Sphere this is not yet possible. To facilitate further research into this area, and minimise the community's reliance on proprietary black box search engines, we will share our indices, evaluation metrics and infrastructure.