 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Structure Learning with Recommendation System
Oct 19, 2022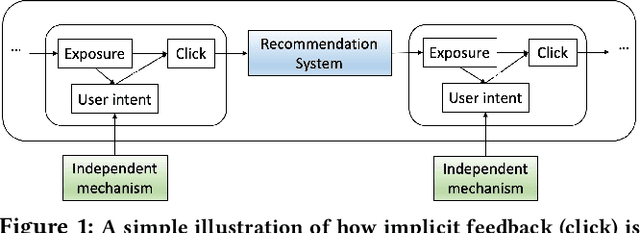
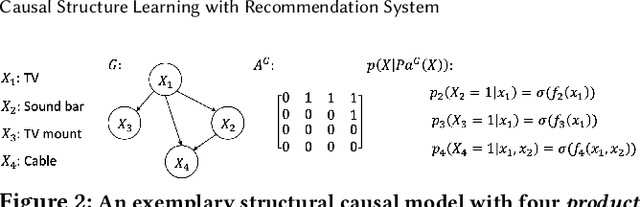
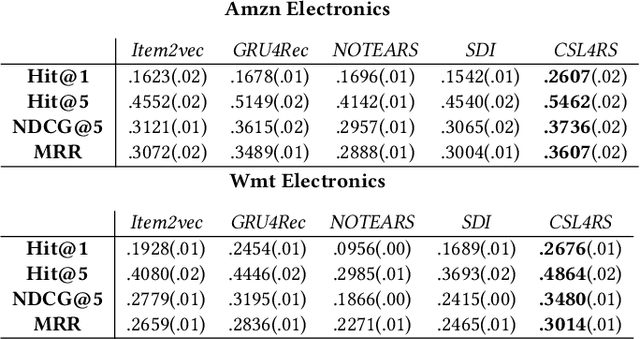
A fundamental challenge of recommendation systems (RS) is understanding the causal dynamics underlying users' decision making. Most existing literature addresses this problem by using causal structures inferred from domain knowledge. However, there are numerous phenomenons where domain knowledge is insufficient, and the causal mechanisms must be learnt from the feedback data. Discovering the causal mechanism from RS feedback data is both novel and challenging, since RS itself is a source of intervention that can influence both the users' exposure and their willingness to interact. Also for this reason, most existing solutions become inappropriate since they require data collected free from any RS. In this paper, we first formulate the underlying causal mechanism as a causal structural model and describe a general causal structure learning framework grounded in the real-world working mechanism of RS. The essence of our approach is to acknowledge the unknown nature of RS intervention. We then derive the learning objective from our framework and propose an augmented Lagrangian solver for efficient optimization. We conduct both simulation and real-world experiments to demonstrate how our approach compares favorably to existing solutions, together with the empirical analysis from sensitivity and ablation studies.
NEAT: A Label Noise-resistant Complementary Item Recommender System with Trustworthy Evaluation
Feb 11, 2022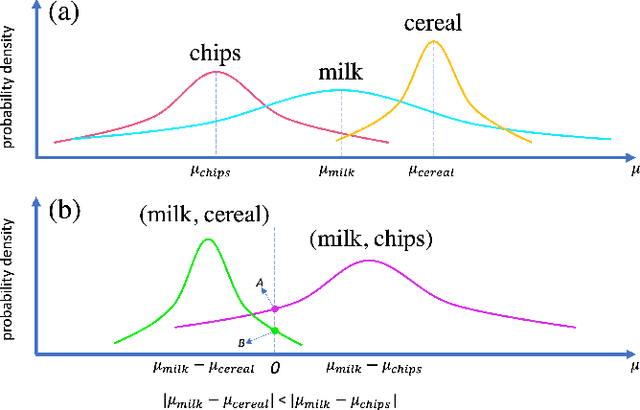
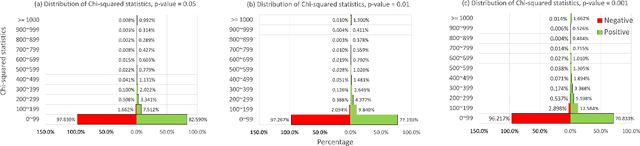
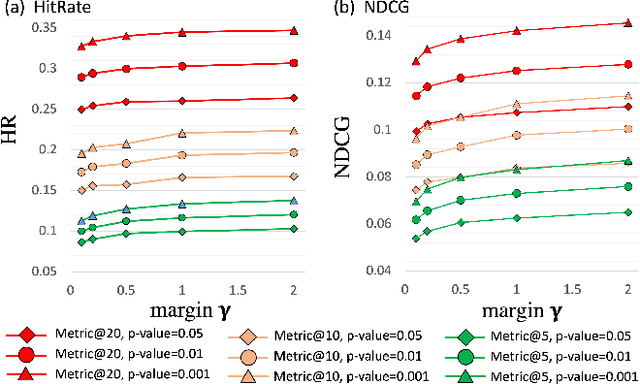
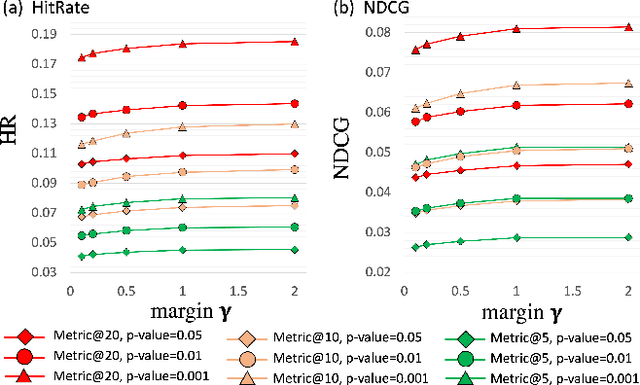
The complementary item recommender system (CIRS) recommends the complementary items for a given query item. Existing CIRS models consider the item co-purchase signal as a proxy of the complementary relationship due to the lack of human-curated labels from the huge transaction records. These methods represent items in a complementary embedding space and model the complementary relationship as a point estimation of the similarity between items vectors. However, co-purchased items are not necessarily complementary to each other. For example, customers may frequently purchase bananas and bottled water within the same transaction, but these two items are not complementary. Hence, using co-purchase signals directly as labels will aggravate the model performance. On the other hand, the model evaluation will not be trustworthy if the labels for evaluation are not reflecting the true complementary relatedness. To address the above challenges from noisy labeling of the copurchase data, we model the co-purchases of two items as a Gaussian distribution, where the mean denotes the co-purchases from the complementary relatedness, and covariance denotes the co-purchases from the noise. To do so, we represent each item as a Gaussian embedding and parameterize the Gaussian distribution of co-purchases by the means and covariances from item Gaussian embedding. To reduce the impact of the noisy labels during evaluation, we propose an independence test-based method to generate a trustworthy label set with certain confidence. Our extensive experiments on both the publicly available dataset and the large-scale real-world dataset justify the effectiveness of our proposed model in complementary item recommendations compared with the state-of-the-art models.
Rethinking Neural vs. Matrix-Factorization Collaborative Filtering: the Theoretical Perspectives
Oct 23, 2021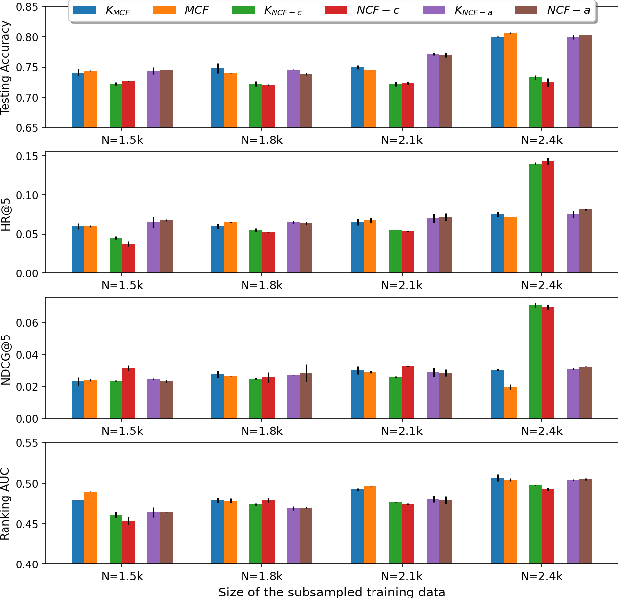
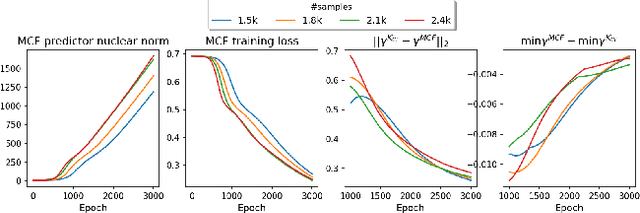
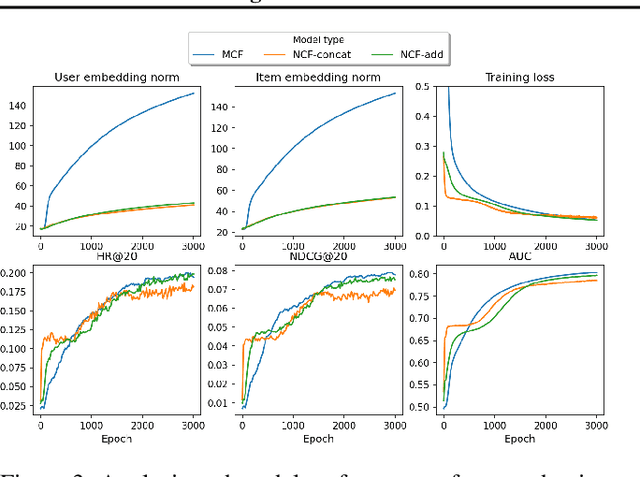
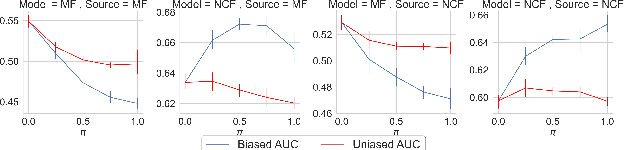
The recent work by Rendle et al. (2020), based on empirical observations, argues that matrix-factorization collaborative filtering (MCF) compares favorably to neural collaborative filtering (NCF), and conjectures the dot product's superiority over the feed-forward neural network as similarity function. In this paper, we address the comparison rigorously by answering the following questions: 1. what is the limiting expressivity of each model; 2. under the practical gradient descent, to which solution does each optimization path converge; 3. how would the models generalize under the inductive and transductive learning setting. Our results highlight the similar expressivity for the overparameterized NCF and MCF as kernelized predictors, and reveal the relation between their optimization paths. We further show their different generalization behaviors, where MCF and NCF experience specific tradeoff and comparison in the transductive and inductive collaborative filtering setting. Lastly, by showing a novel generalization result, we reveal the critical role of correcting exposure bias for model evaluation in the inductive setting. Our results explain some of the previously observed conflicts, and we provide synthetic and real-data experiments to shed further insights to this topic.
Towards the D-Optimal Online Experiment Design for Recommender Selection
Oct 23, 2021
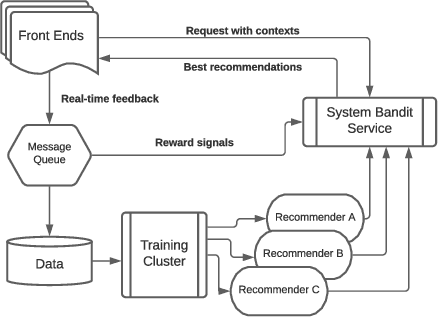
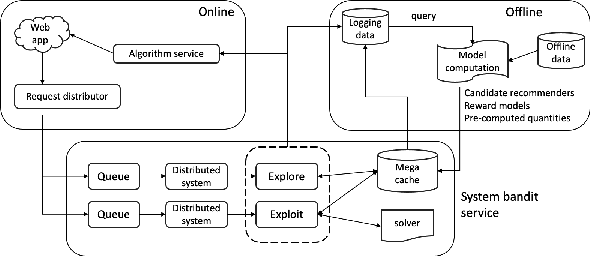
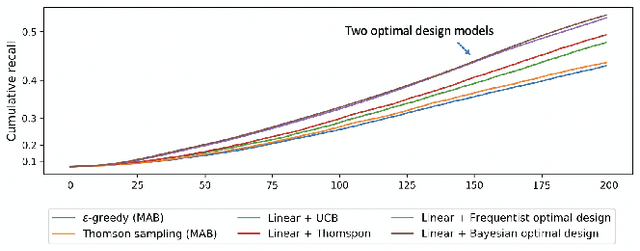
Selecting the optimal recommender via online exploration-exploitation is catching increasing attention where the traditional A/B testing can be slow and costly, and offline evaluations are prone to the bias of history data. Finding the optimal online experiment is nontrivial since both the users and displayed recommendations carry contextual features that are informative to the reward. While the problem can be formalized via the lens of multi-armed bandits, the existing solutions are found less satisfactorily because the general methodologies do not account for the case-specific structures, particularly for the e-commerce recommendation we study. To fill in the gap, we leverage the \emph{D-optimal design} from the classical statistics literature to achieve the maximum information gain during exploration, and reveal how it fits seamlessly with the modern infrastructure of online inference. To demonstrate the effectiveness of the optimal designs, we provide semi-synthetic simulation studies with published code and data for reproducibility purposes. We then use our deployment example on Walmart.com to fully illustrate the practical insights and effectiveness of the proposed methods.
A Temporal Kernel Approach for Deep Learning with Continuous-time Information
Mar 28, 2021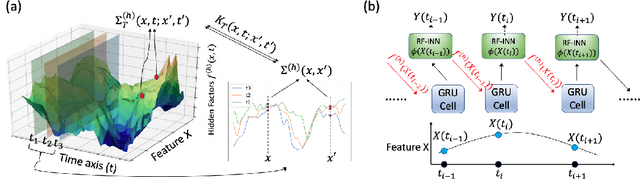
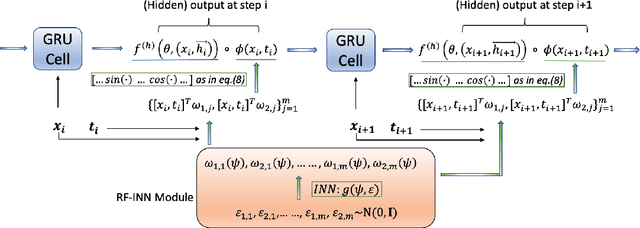
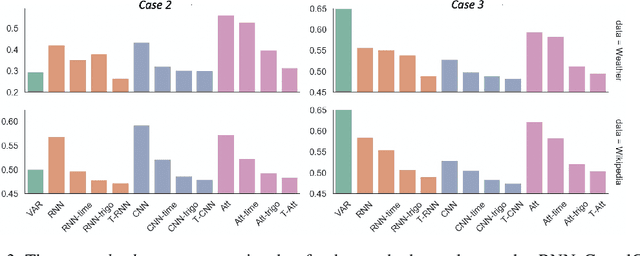
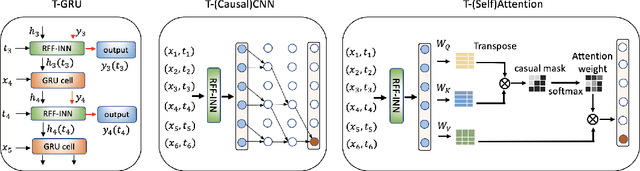
Sequential deep learning models such as RNN, causal CNN and attention mechanism do not readily consume continuous-time information. Discretizing the temporal data, as we show, causes inconsistency even for simple continuous-time processes. Current approaches often handle time in a heuristic manner to be consistent with the existing deep learning architectures and implementations. In this paper, we provide a principled way to characterize continuous-time systems using deep learning tools. Notably, the proposed approach applies to all the major deep learning architectures and requires little modifications to the implementation. The critical insight is to represent the continuous-time system by composing neural networks with a temporal kernel, where we gain our intuition from the recent advancements in understanding deep learning with Gaussian process and neural tangent kernel. To represent the temporal kernel, we introduce the random feature approach and convert the kernel learning problem to spectral density estimation under reparameterization. We further prove the convergence and consistency results even when the temporal kernel is non-stationary, and the spectral density is misspecified. The simulations and real-data experiments demonstrate the empirical effectiveness of our temporal kernel approach in a broad range of settings.
Theoretical Understandings of Product Embedding for E-commerce Machine Learning
Feb 24, 2021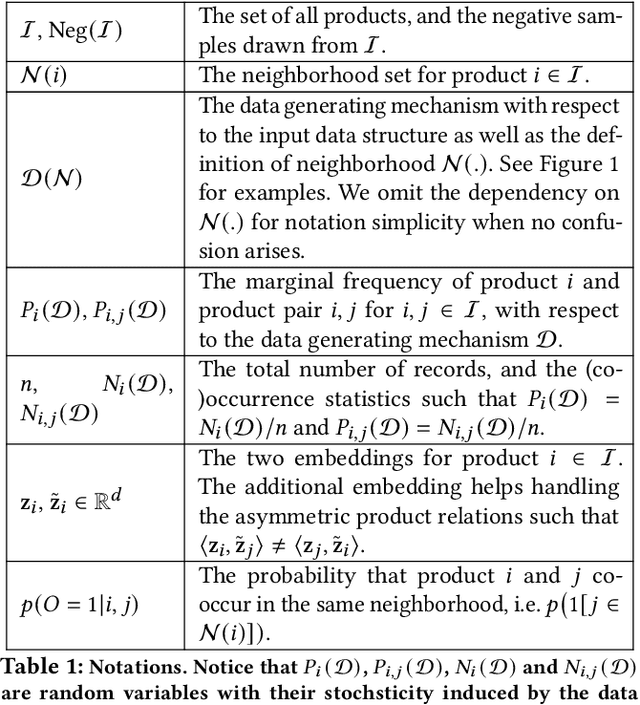
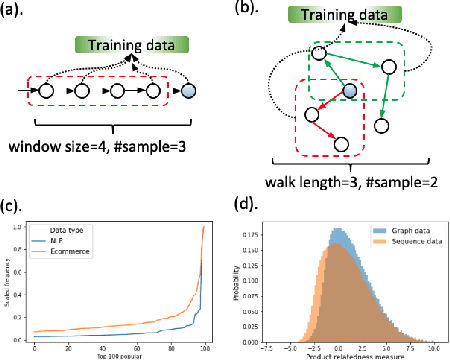
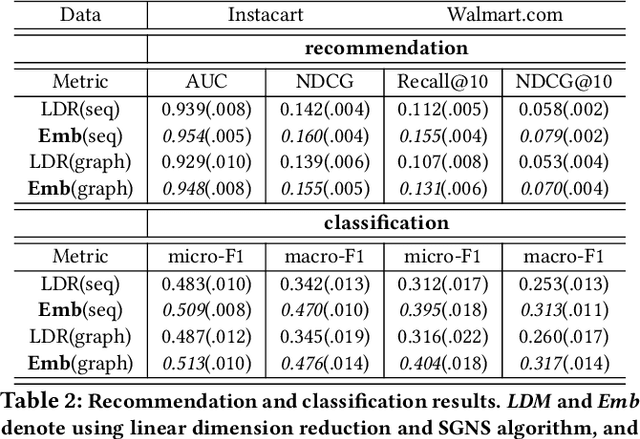
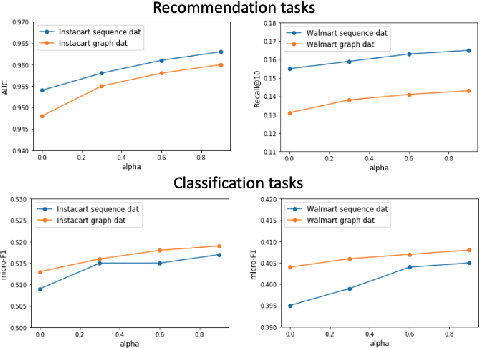
Product embeddings have been heavily investigated in the past few years, serving as the cornerstone for a broad range of machine learning applications in e-commerce. Despite the empirical success of product embeddings, little is known on how and why they work from the theoretical standpoint. Analogous results from the natural language processing (NLP) often rely on domain-specific properties that are not transferable to the e-commerce setting, and the downstream tasks often focus on different aspects of the embeddings. We take an e-commerce-oriented view of the product embeddings and reveal a complete theoretical view from both the representation learning and the learning theory perspective. We prove that product embeddings trained by the widely-adopted skip-gram negative sampling algorithm and its variants are sufficient dimension reduction regarding a critical product relatedness measure. The generalization performance in the downstream machine learning task is controlled by the alignment between the embeddings and the product relatedness measure. Following the theoretical discoveries, we conduct exploratory experiments that supports our theoretical insights for the product embeddings.
GAN-based Recommendation with Positive-Unlabeled Sampling
Dec 12, 2020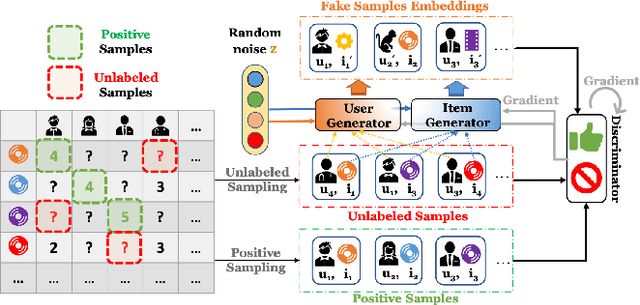
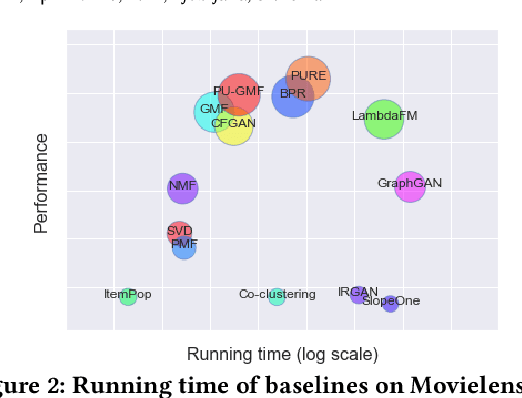
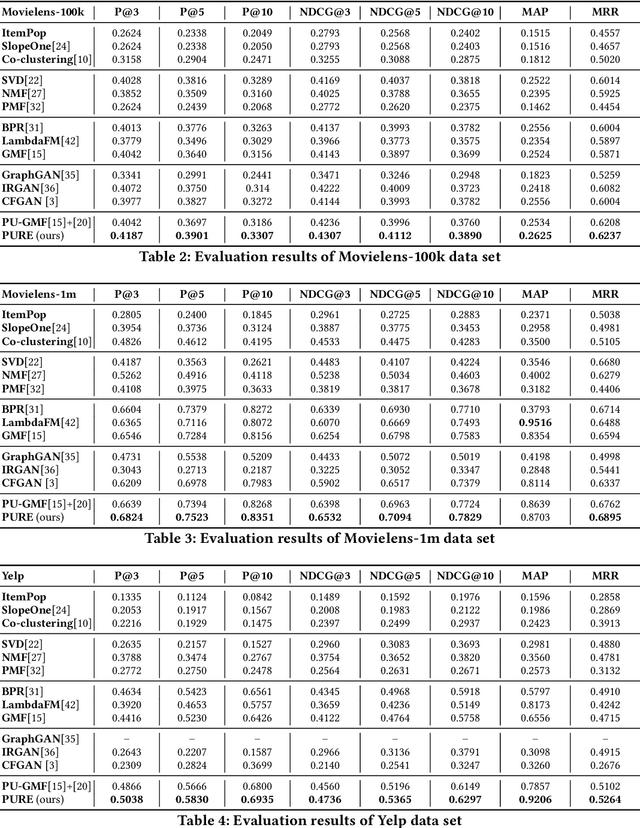
Recommender systems are popular tools for information retrieval tasks on a large variety of web applications and personalized products. In this work, we propose a Generative Adversarial Network based recommendation framework using a positive-unlabeled sampling strategy. Specifically, we utilize the generator to learn the continuous distribution of user-item tuples and design the discriminator to be a binary classifier that outputs the relevance score between each user and each item. Meanwhile, positive-unlabeled sampling is applied in the learning procedure of the discriminator. Theoretical bounds regarding positive-unlabeled sampling and optimalities of convergence for the discriminators and the generators are provided. We show the effectiveness and efficiency of our framework on three publicly accessible data sets with eight ranking-based evaluation metrics in comparison with thirteen popular baselines.
Inductive Representation Learning on Temporal Graphs
Feb 19, 2020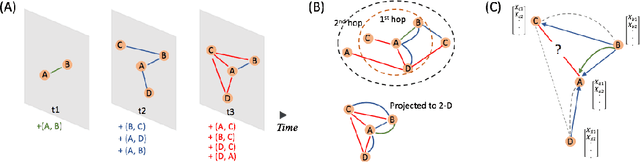
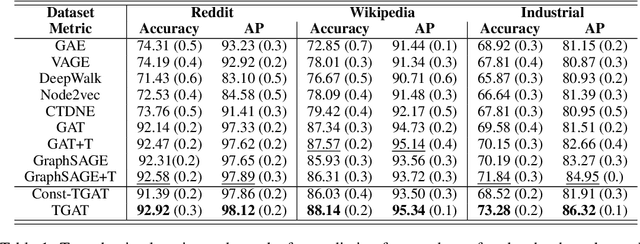
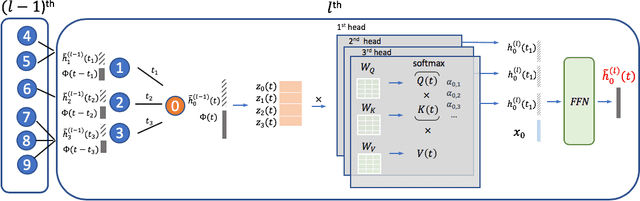
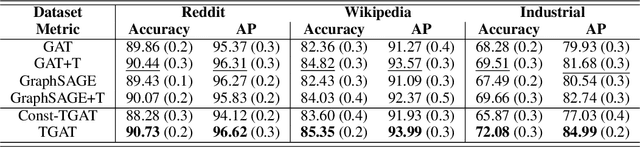
Inductive representation learning on temporal graphs is an important step toward salable machine learning on real-world dynamic networks. The evolving nature of temporal dynamic graphs requires handling new nodes as well as capturing temporal patterns. The node embeddings, which are now functions of time, should represent both the static node features and the evolving topological structures. Moreover, node and topological features can be temporal as well, whose patterns the node embeddings should also capture. We propose the temporal graph attention (TGAT) layer to efficiently aggregate temporal-topological neighborhood features as well as to learn the time-feature interactions. For TGAT, we use the self-attention mechanism as building block and develop a novel functional time encoding technique based on the classical Bochner's theorem from harmonic analysis. By stacking TGAT layers, the network recognizes the node embeddings as functions of time and is able to inductively infer embeddings for both new and observed nodes as the graph evolves. The proposed approach handles both node classification and link prediction task, and can be naturally extended to include the temporal edge features. We evaluate our method with transductive and inductive tasks under temporal settings with two benchmark and one industrial dataset. Our TGAT model compares favorably to state-of-the-art baselines as well as the previous temporal graph embedding approaches.
Self-attention with Functional Time Representation Learning
Nov 28, 2019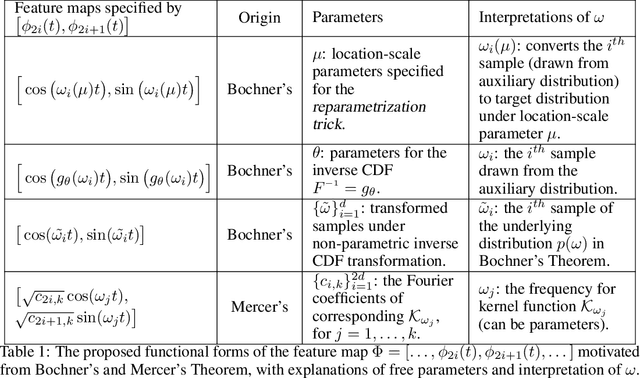
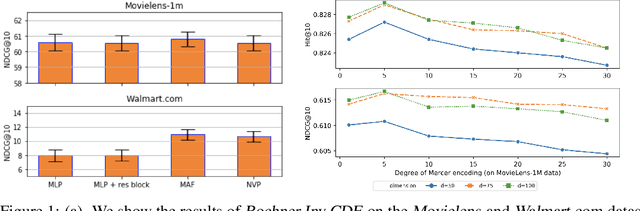
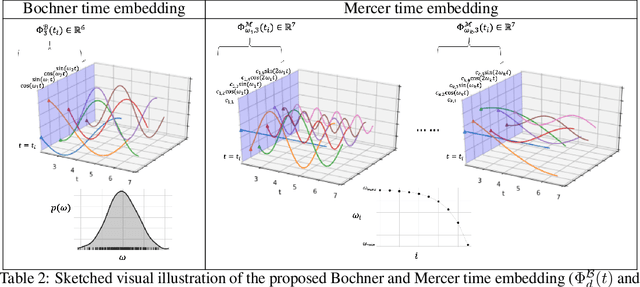
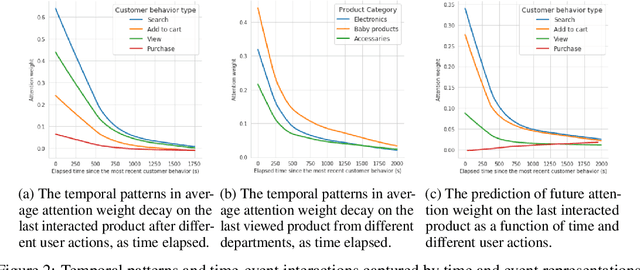
Sequential modelling with self-attention has achieved cutting edge performances in natural language processing. With advantages in model flexibility, computation complexity and interpretability, self-attention is gradually becoming a key component in event sequence models. However, like most other sequence models, self-attention does not account for the time span between events and thus captures sequential signals rather than temporal patterns. Without relying on recurrent network structures, self-attention recognizes event orderings via positional encoding. To bridge the gap between modelling time-independent and time-dependent event sequence, we introduce a functional feature map that embeds time span into high-dimensional spaces. By constructing the associated translation-invariant time kernel function, we reveal the functional forms of the feature map under classic functional function analysis results, namely Bochner's Theorem and Mercer's Theorem. We propose several models to learn the functional time representation and the interactions with event representation. These methods are evaluated on real-world datasets under various continuous-time event sequence prediction tasks. The experiments reveal that the proposed methods compare favorably to baseline models while also capturing useful time-event interactions.
Product Knowledge Graph Embedding for E-commerce
Nov 28, 2019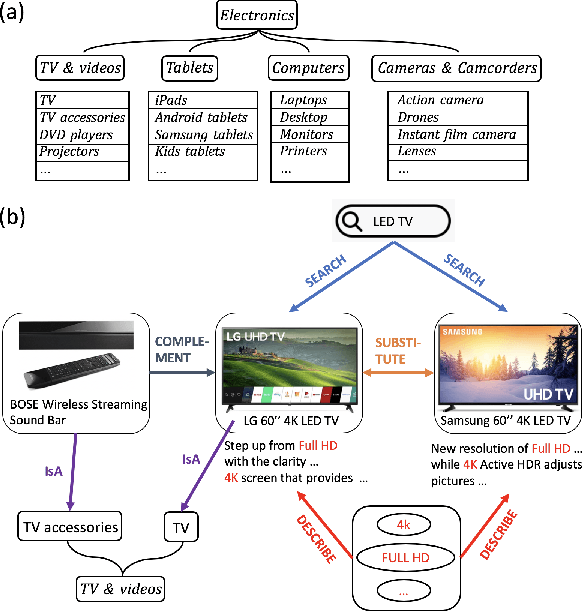
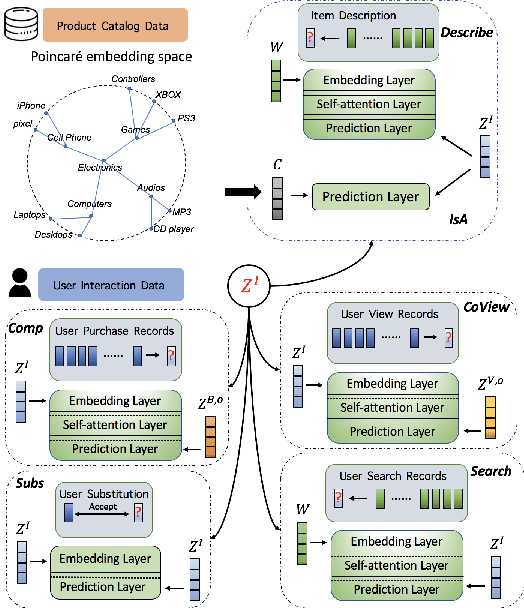

In this paper, we propose a new product knowledge graph (PKG) embedding approach for learning the intrinsic product relations as product knowledge for e-commerce. We define the key entities and summarize the pivotal product relations that are critical for general e-commerce applications including marketing, advertisement, search ranking and recommendation. We first provide a comprehensive comparison between PKG and ordinary knowledge graph (KG) and then illustrate why KG embedding methods are not suitable for PKG learning. We construct a self-attention-enhanced distributed representation learning model for learning PKG embeddings from raw customer activity data in an end-to-end fashion. We design an effective multi-task learning schema to fully leverage the multi-modal e-commerce data. The Poincare embedding is also employed to handle complex entity structures. We use a real-world dataset from grocery.walmart.com to evaluate the performances on knowledge completion, search ranking and recommendation. The proposed approach compares favourably to baselines in knowledge completion and downstream tasks.