 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow BPE Affects Memorization in Transformers
Oct 06, 2021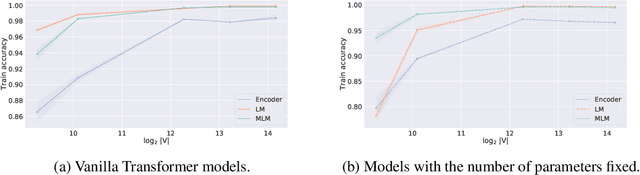

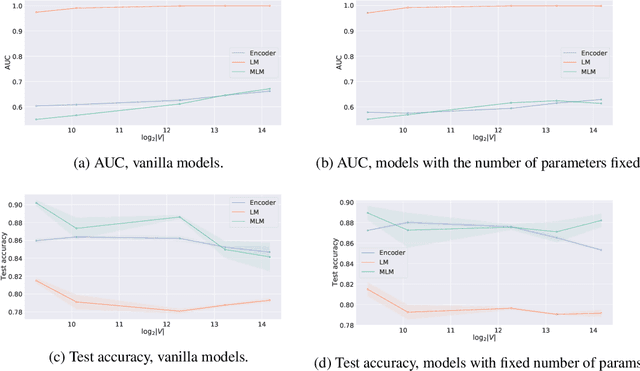
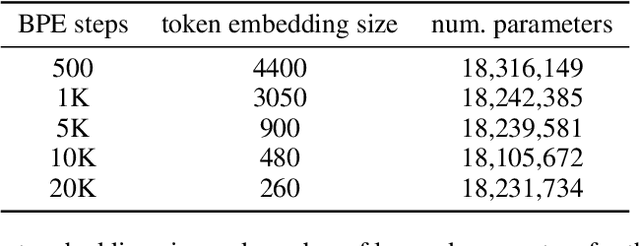
Training data memorization in NLP can both be beneficial (e.g., closed-book QA) and undesirable (personal data extraction). In any case, successful model training requires a non-trivial amount of memorization to store word spellings, various linguistic idiosyncrasies and common knowledge. However, little is known about what affects the memorization behavior of NLP models, as the field tends to focus on the equally important question of generalization. In this work, we demonstrate that the size of the subword vocabulary learned by Byte-Pair Encoding (BPE) greatly affects both ability and tendency of standard Transformer models to memorize training data, even when we control for the number of learned parameters. We find that with a large subword vocabulary size, Transformer models fit random mappings more easily and are more vulnerable to membership inference attacks. Similarly, given a prompt, Transformer-based language models with large subword vocabularies reproduce the training data more often. We conjecture this effect is caused by reduction in the sequences' length that happens as the BPE vocabulary grows. Our findings can allow a more informed choice of hyper-parameters, that is better tailored for a particular use-case.
Text-Free Prosody-Aware Generative Spoken Language Modeling
Sep 07, 2021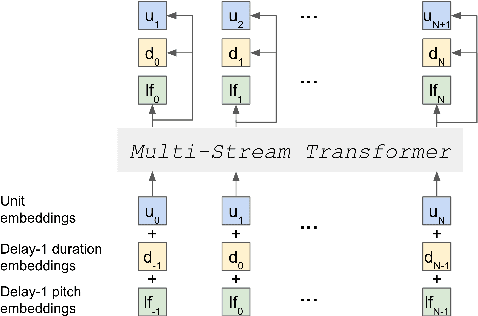
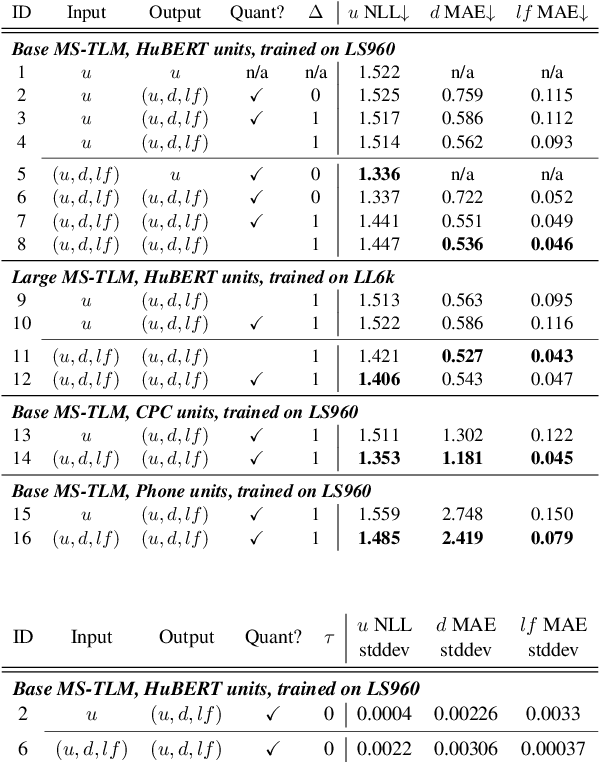
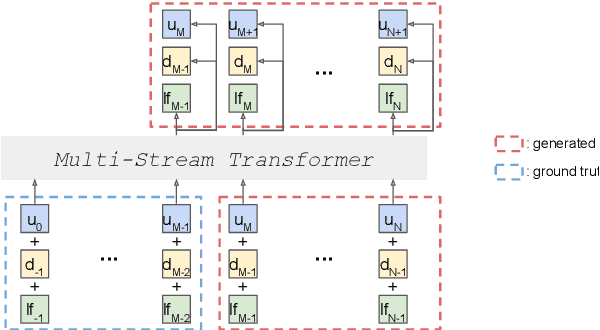
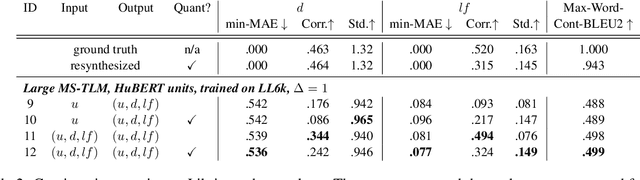
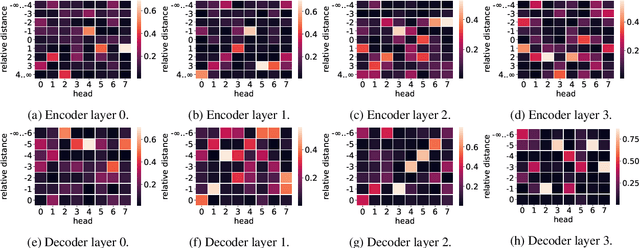
Speech pre-training has primarily demonstrated efficacy on classification tasks, while its capability of generating novel speech, similar to how GPT-2 can generate coherent paragraphs, has barely been explored. Generative Spoken Language Modeling (GSLM) (Lakhotia et al., 2021) is the only prior work addressing the generative aspects of speech pre-training, which replaces text with discovered phone-like units for language modeling and shows the ability to generate meaningful novel sentences. Unfortunately, despite eliminating the need of text, the units used in GSLM discard most of the prosodic information. Hence, GSLM fails to leverage prosody for better comprehension, and does not generate expressive speech. In this work, we present a prosody-aware generative spoken language model (pGSLM). It is composed of a multi-stream transformer language model (MS-TLM) of speech, represented as discovered unit and prosodic feature streams, and an adapted HiFi-GAN model converting MS-TLM outputs to waveforms. We devise a series of metrics for prosody modeling and generation, and re-use metrics from GSLM for content modeling. Experimental results show that the pGSLM can utilize prosody to improve both prosody and content modeling, and also generate natural, meaningful, and coherent speech given a spoken prompt. Audio samples can be found at https://speechbot.github.io/pgslm.
Can Transformers Jump Around Right in Natural Language? Assessing Performance Transfer from SCAN
Jul 03, 2021
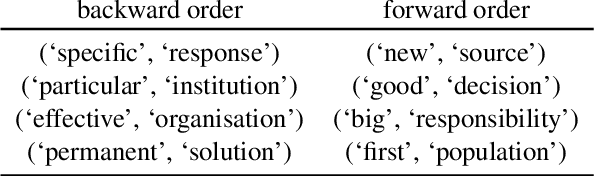
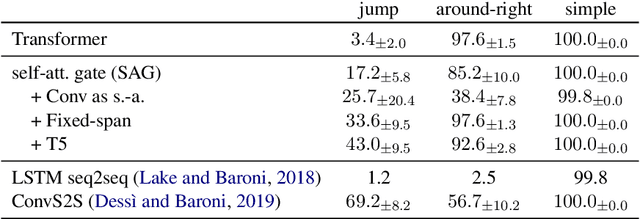
Despite their practical success, modern seq2seq architectures are unable to generalize systematically on several SCAN tasks. Hence, it is not clear if SCAN-style compositional generalization is useful in realistic NLP tasks. In this work, we study the benefit that such compositionality brings about to several machine translation tasks. We present several focused modifications of Transformer that greatly improve generalization capabilities on SCAN and select one that remains on par with a vanilla Transformer on a standard machine translation (MT) task. Next, we study its performance in low-resource settings and on a newly introduced distribution-shifted English-French translation task. Overall, we find that improvements of a SCAN-capable model do not directly transfer to the resource-rich MT setup. In contrast, in the low-resource setup, general modifications lead to an improvement of up to 13.1% BLEU score w.r.t. a vanilla Transformer. Similarly, an improvement of 14% in an accuracy-based metric is achieved in the introduced compositional English-French translation task. This provides experimental evidence that the compositional generalization assessed in SCAN is particularly useful in resource-starved and domain-shifted scenarios.
Interpretable agent communication from scratch(with a generic visual processor emerging on the side)
Jun 08, 2021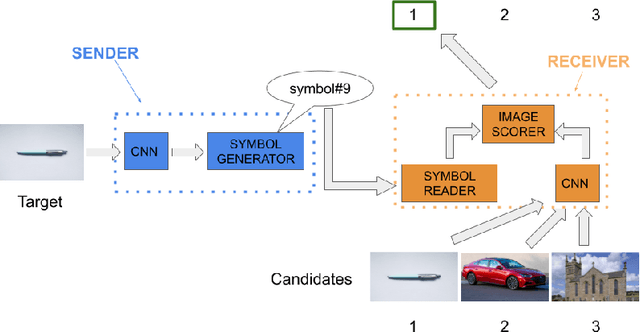
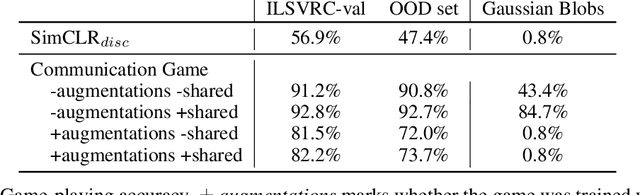
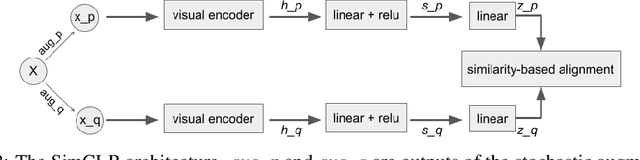
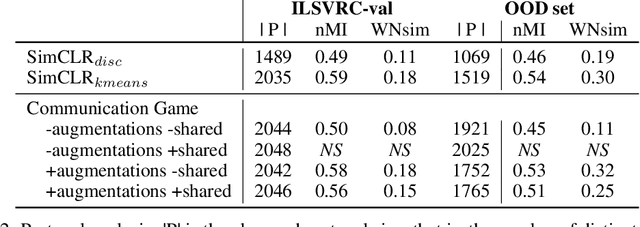
As deep networks begin to be deployed as autonomous agents, the issue of how they can communicate with each other becomes important. Here, we train two deep nets from scratch to perform realistic referent identification through unsupervised emergent communication. We show that the largely interpretable emergent protocol allows the nets to successfully communicate even about object types they did not see at training time. The visual representations induced as a by-product of our training regime, moreover, show comparable quality, when re-used as generic visual features, to a recent self-supervised learning model. Our results provide concrete evidence of the viability of (interpretable) emergent deep net communication in a more realistic scenario than previously considered, as well as establishing an intriguing link between this field and self-supervised visual learning.
The Interspeech Zero Resource Speech Challenge 2021: Spoken language modelling
Apr 29, 2021
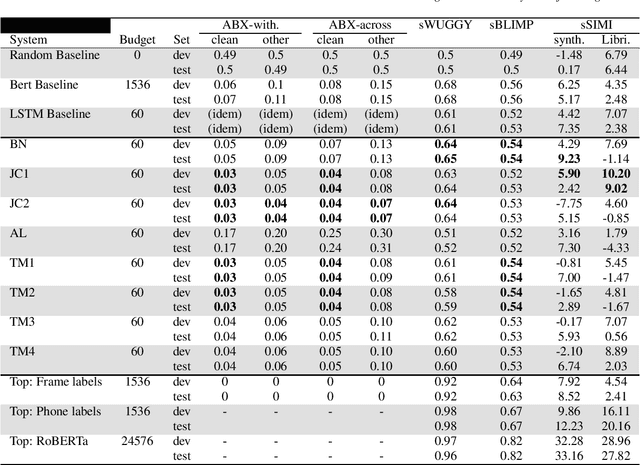
We present the Zero Resource Speech Challenge 2021, which asks participants to learn a language model directly from audio, without any text or labels. The challenge is based on the Libri-light dataset, which provides up to 60k hours of audio from English audio books without any associated text. We provide a pipeline baseline system consisting on an encoder based on contrastive predictive coding (CPC), a quantizer ($k$-means) and a standard language model (BERT or LSTM). The metrics evaluate the learned representations at the acoustic (ABX discrimination), lexical (spot-the-word), syntactic (acceptability judgment) and semantic levels (similarity judgment). We present an overview of the eight submitted systems from four groups and discuss the main results.
Speech Resynthesis from Discrete Disentangled Self-Supervised Representations
Apr 02, 2021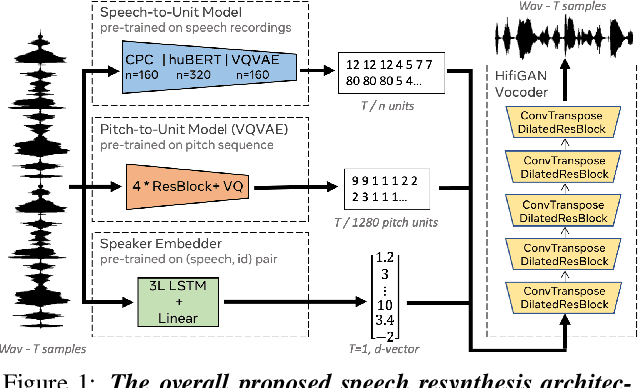
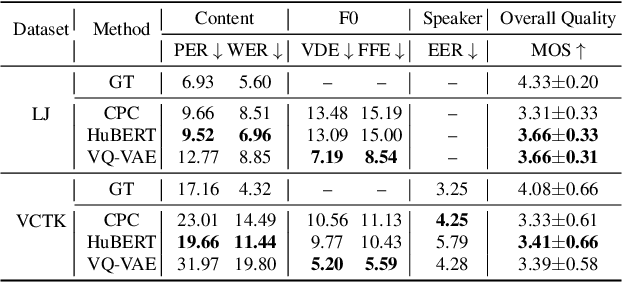
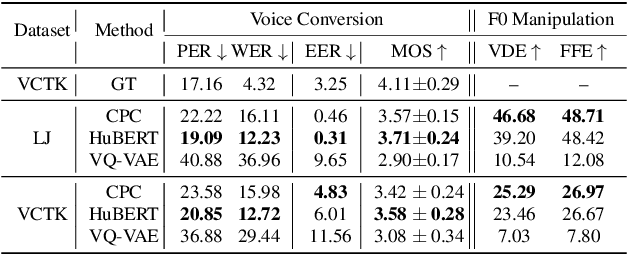
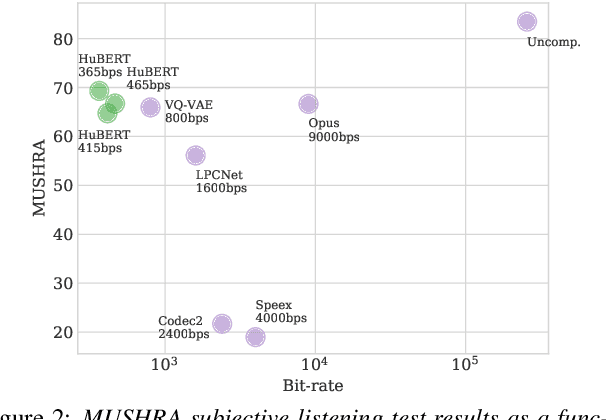
We propose using self-supervised discrete representations for the task of speech resynthesis. To generate disentangled representation, we separately extract low-bitrate representations for speech content, prosodic information, and speaker identity. This allows to synthesize speech in a controllable manner. We analyze various state-of-the-art, self-supervised representation learning methods and shed light on the advantages of each method while considering reconstruction quality and disentanglement properties. Specifically, we evaluate the F0 reconstruction, speaker identification performance (for both resynthesis and voice conversion), recordings' intelligibility, and overall quality using subjective human evaluation. Lastly, we demonstrate how these representations can be used for an ultra-lightweight speech codec. Using the obtained representations, we can get to a rate of 365 bits per second while providing better speech quality than the baseline methods. Audio samples can be found under https://resynthesis-ssl.github.io/.
Data Augmenting Contrastive Learning of Speech Representations in the Time Domain
Jul 02, 2020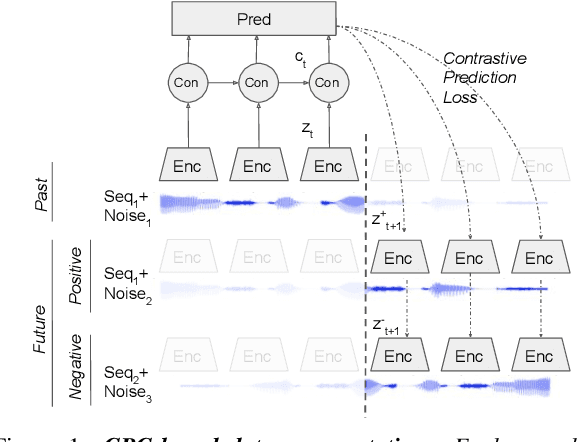
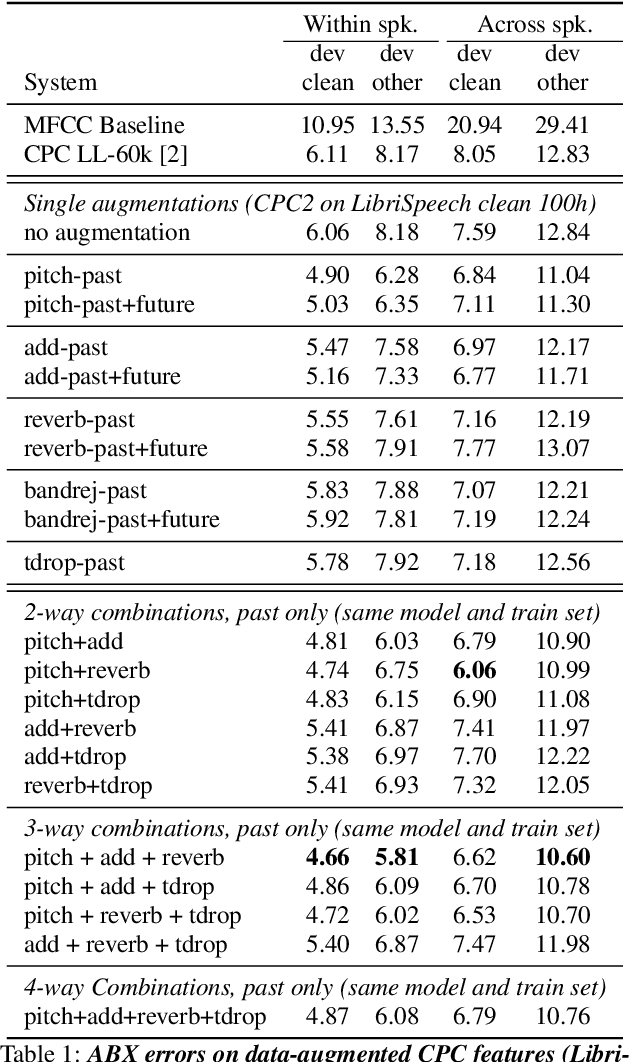
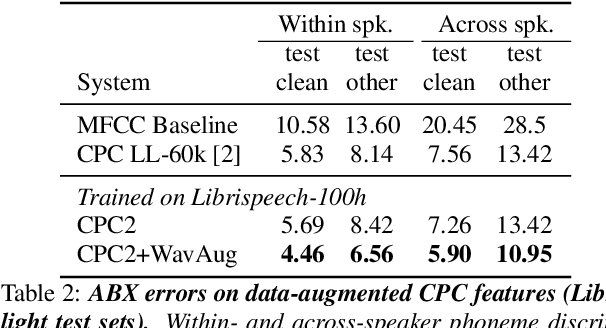
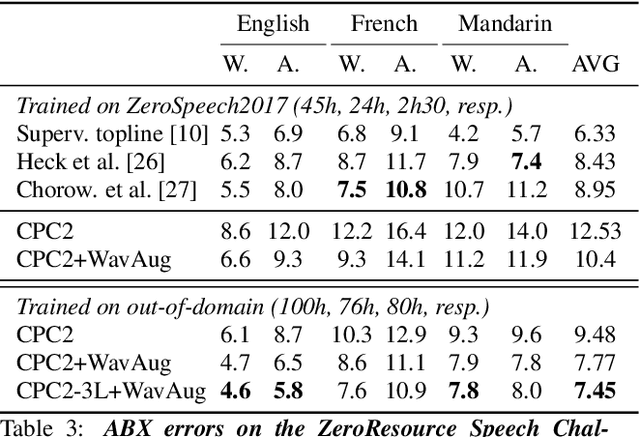
Contrastive Predictive Coding (CPC), based on predicting future segments of speech based on past segments is emerging as a powerful algorithm for representation learning of speech signal. However, it still under-performs other methods on unsupervised evaluation benchmarks. Here, we introduce WavAugment, a time-domain data augmentation library and find that applying augmentation in the past is generally more efficient and yields better performances than other methods. We find that a combination of pitch modification, additive noise and reverberation substantially increase the performance of CPC (relative improvement of 18-22%), beating the reference Libri-light results with 600 times less data. Using an out-of-domain dataset, time-domain data augmentation can push CPC to be on par with the state of the art on the Zero Speech Benchmark 2017. We also show that time-domain data augmentation consistently improves downstream limited-supervision phoneme classification tasks by a factor of 12-15% relative.
What they do when in doubt: a study of inductive biases in seq2seq learners
Jun 26, 2020
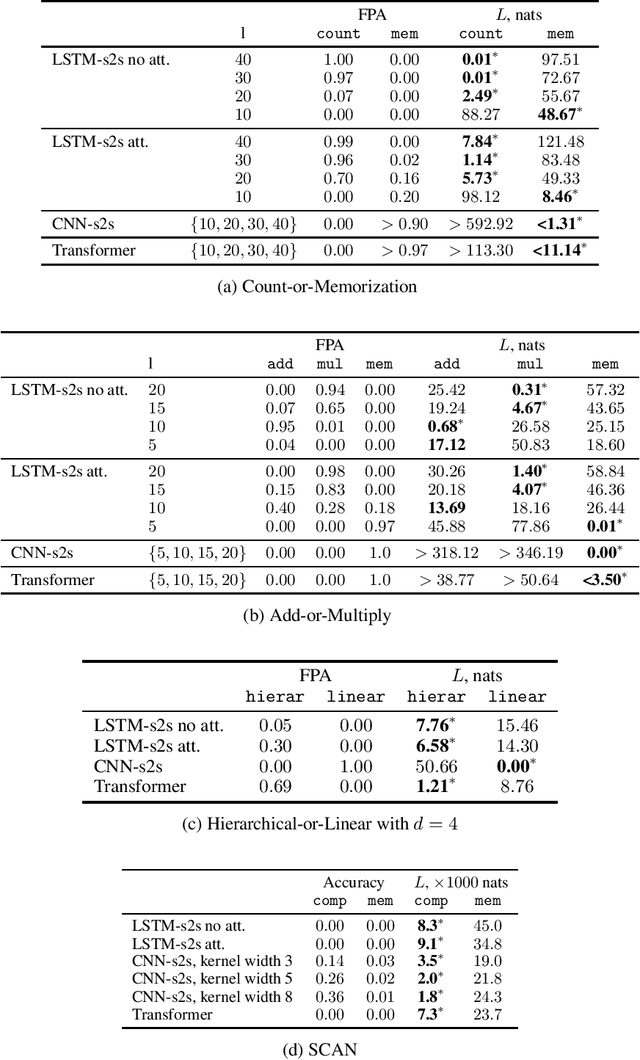
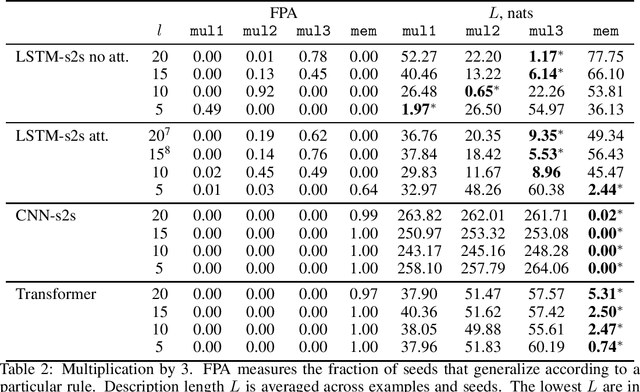
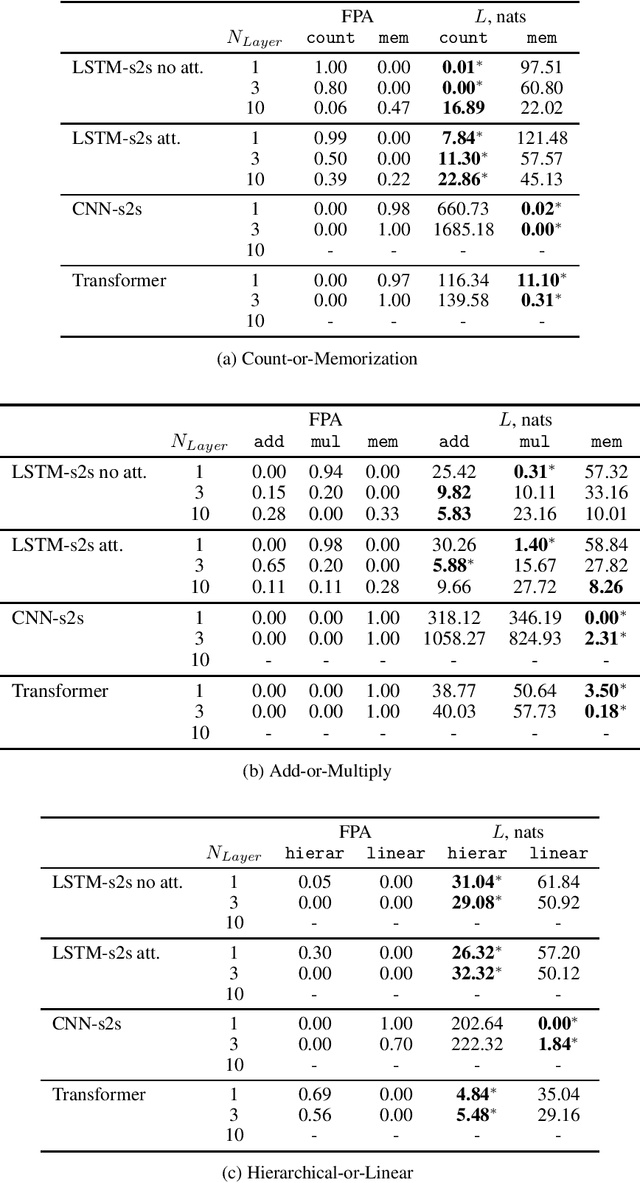
Sequence-to-sequence (seq2seq) learners are widely used, but we still have only limited knowledge about what inductive biases shape the way they generalize. We address that by investigating how popular seq2seq learners generalize in tasks that have high ambiguity in the training data. We use SCAN and three new tasks to study learners' preferences for memorization, arithmetic, hierarchical, and compositional reasoning. Further, we connect to Solomonoff's theory of induction and propose to use description length as a principled and sensitive measure of inductive biases. In our experimental study, we find that LSTM-based learners can learn to perform counting, addition, and multiplication by a constant from a single training example. Furthermore, Transformer and LSTM-based learners show a bias toward the hierarchical induction over the linear one, while CNN-based learners prefer the opposite. On the SCAN dataset, we find that CNN-based, and, to a lesser degree, Transformer- and LSTM-based learners have a preference for compositional generalization over memorization. Finally, across all our experiments, description length proved to be a sensitive measure of inductive biases.
Emergent Language Generalization and Acquisition Speed are not tied to Compositionality
Apr 25, 2020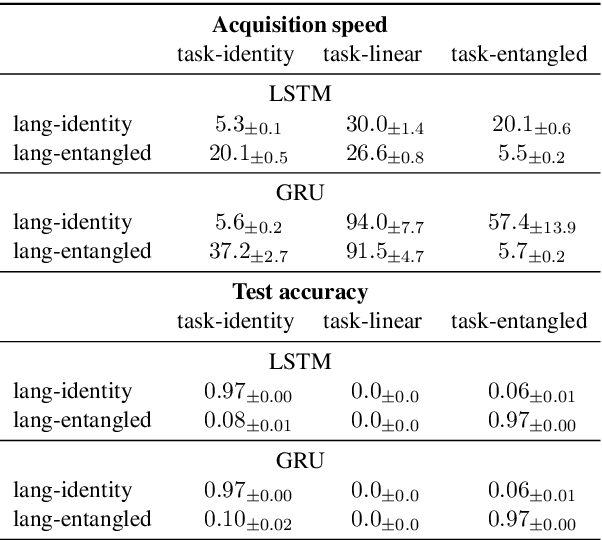
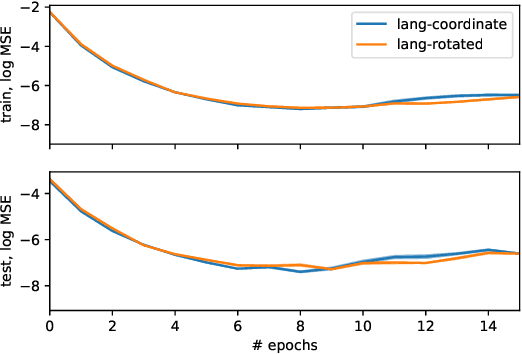
Studies of discrete languages emerging when neural agents communicate to solve a joint task often look for evidence of compositional structure. This stems for the expectation that such a structure would allow languages to be acquired faster by the agents and enable them to generalize better. We argue that these beneficial properties are only loosely connected to compositionality. In two experiments, we demonstrate that, depending on the task, non-compositional languages might show equal, or better, generalization performance and acquisition speed than compositional ones. Further research in the area should be clearer about what benefits are expected from compositionality, and how the latter would lead to them.
Compositionality and Generalization in Emergent Languages
Apr 20, 2020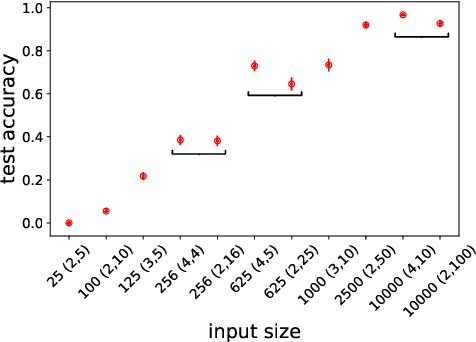
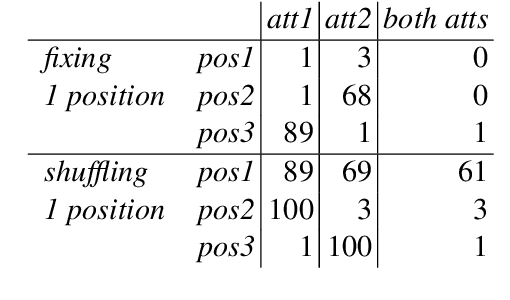
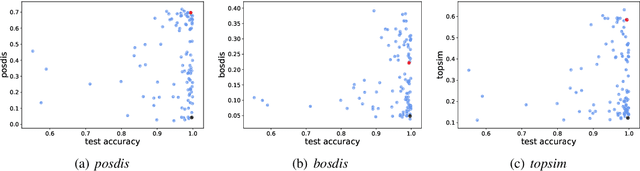

Natural language allows us to refer to novel composite concepts by combining expressions denoting their parts according to systematic rules, a property known as \emph{compositionality}. In this paper, we study whether the language emerging in deep multi-agent simulations possesses a similar ability to refer to novel primitive combinations, and whether it accomplishes this feat by strategies akin to human-language compositionality. Equipped with new ways to measure compositionality in emergent languages inspired by disentanglement in representation learning, we establish three main results. First, given sufficiently large input spaces, the emergent language will naturally develop the ability to refer to novel composite concepts. Second, there is no correlation between the degree of compositionality of an emergent language and its ability to generalize. Third, while compositionality is not necessary for generalization, it provides an advantage in terms of language transmission: The more compositional a language is, the more easily it will be picked up by new learners, even when the latter differ in architecture from the original agents. We conclude that compositionality does not arise from simple generalization pressure, but if an emergent language does chance upon it, it will be more likely to survive and thrive.