 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructured Generative Adversarial Networks
Nov 02, 2017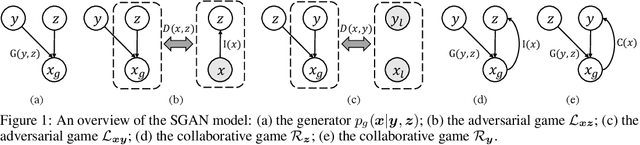
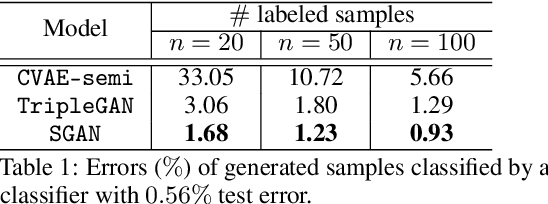
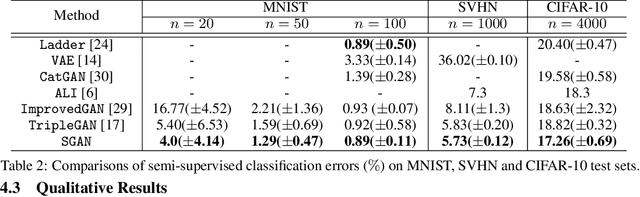

We study the problem of conditional generative modeling based on designated semantics or structures. Existing models that build conditional generators either require massive labeled instances as supervision or are unable to accurately control the semantics of generated samples. We propose structured generative adversarial networks (SGANs) for semi-supervised conditional generative modeling. SGAN assumes the data x is generated conditioned on two independent latent variables: y that encodes the designated semantics, and z that contains other factors of variation. To ensure disentangled semantics in y and z, SGAN builds two collaborative games in the hidden space to minimize the reconstruction error of y and z, respectively. Training SGAN also involves solving two adversarial games that have their equilibrium concentrating at the true joint data distributions p(x, z) and p(x, y), avoiding distributing the probability mass diffusely over data space that MLE-based methods may suffer. We assess SGAN by evaluating its trained networks, and its performance on downstream tasks. We show that SGAN delivers a highly controllable generator, and disentangled representations; it also establishes start-of-the-art results across multiple datasets when applied for semi-supervised image classification (1.27%, 5.73%, 17.26% error rates on MNIST, SVHN and CIFAR-10 using 50, 1000 and 4000 labels, respectively). Benefiting from the separate modeling of y and z, SGAN can generate images with high visual quality and strictly following the designated semantic, and can be extended to a wide spectrum of applications, such as style transfer.
Learning Scalable Deep Kernels with Recurrent Structure
Oct 05, 2017
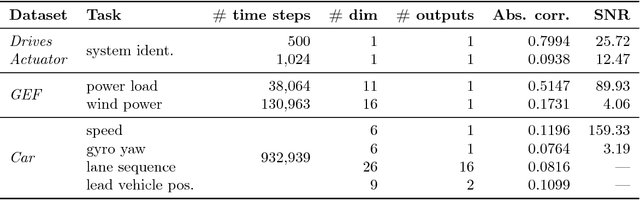
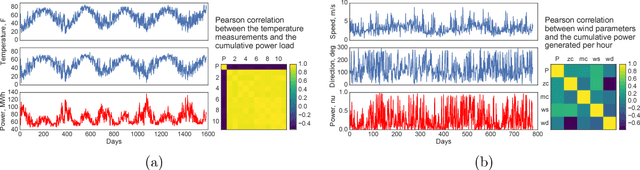
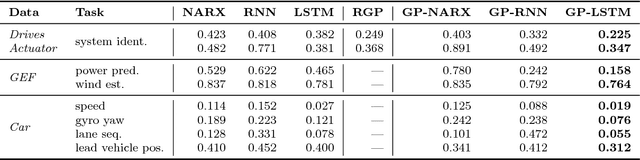
Many applications in speech, robotics, finance, and biology deal with sequential data, where ordering matters and recurrent structures are common. However, this structure cannot be easily captured by standard kernel functions. To model such structure, we propose expressive closed-form kernel functions for Gaussian processes. The resulting model, GP-LSTM, fully encapsulates the inductive biases of long short-term memory (LSTM) recurrent networks, while retaining the non-parametric probabilistic advantages of Gaussian processes. We learn the properties of the proposed kernels by optimizing the Gaussian process marginal likelihood using a new provably convergent semi-stochastic gradient procedure and exploit the structure of these kernels for scalable training and prediction. This approach provides a practical representation for Bayesian LSTMs. We demonstrate state-of-the-art performance on several benchmarks, and thoroughly investigate a consequential autonomous driving application, where the predictive uncertainties provided by GP-LSTM are uniquely valuable.
* 37 pages, 7 figures, 5 tables. Updated to the final version that appears in JMLR, 18(82):1-37, 2017
Towards Visual Explanations for Convolutional Neural Networks via Input Resampling
Aug 16, 2017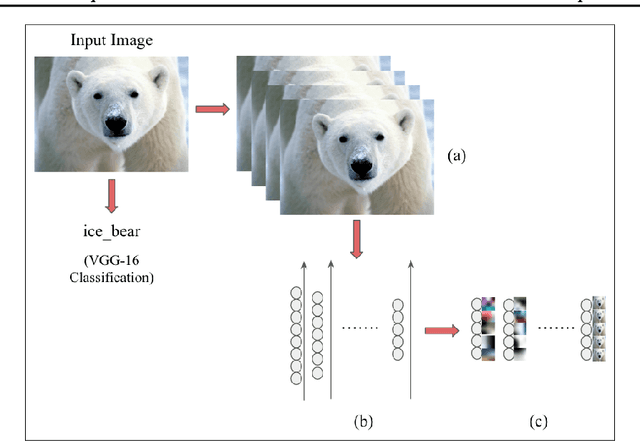
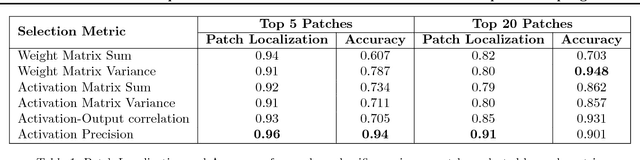
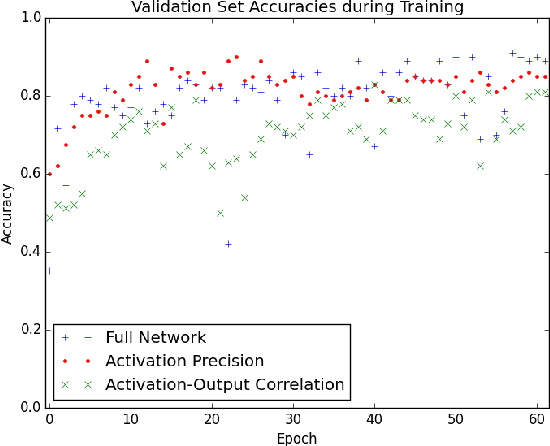
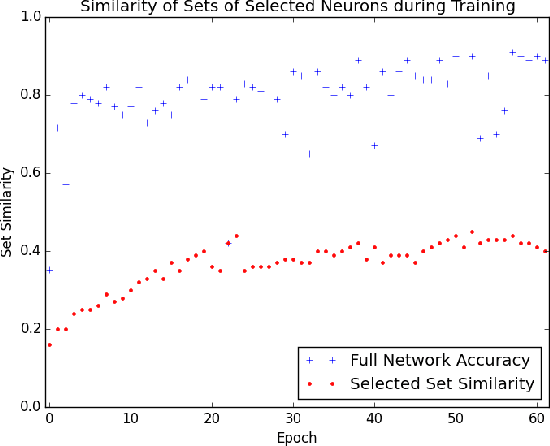
The predictive power of neural networks often costs model interpretability. Several techniques have been developed for explaining model outputs in terms of input features; however, it is difficult to translate such interpretations into actionable insight. Here, we propose a framework to analyze predictions in terms of the model's internal features by inspecting information flow through the network. Given a trained network and a test image, we select neurons by two metrics, both measured over a set of images created by perturbations to the input image: (1) magnitude of the correlation between the neuron activation and the network output and (2) precision of the neuron activation. We show that the former metric selects neurons that exert large influence over the network output while the latter metric selects neurons that activate on generalizable features. By comparing the sets of neurons selected by these two metrics, our framework suggests a way to investigate the internal attention mechanisms of convolutional neural networks.
Dual Motion GAN for Future-Flow Embedded Video Prediction
Aug 03, 2017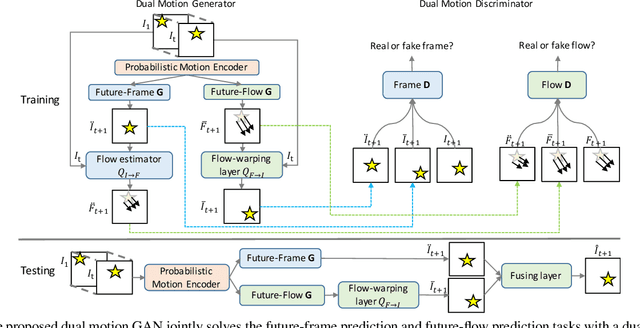
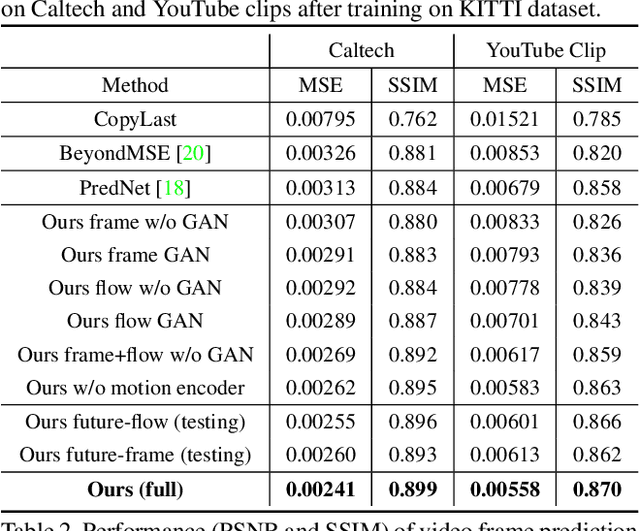
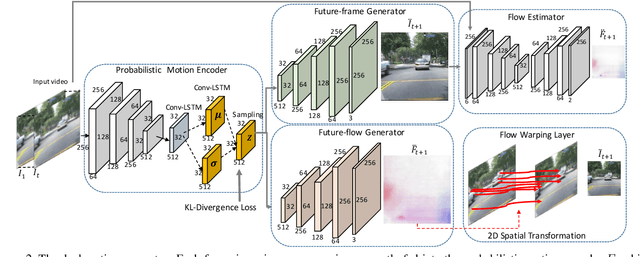
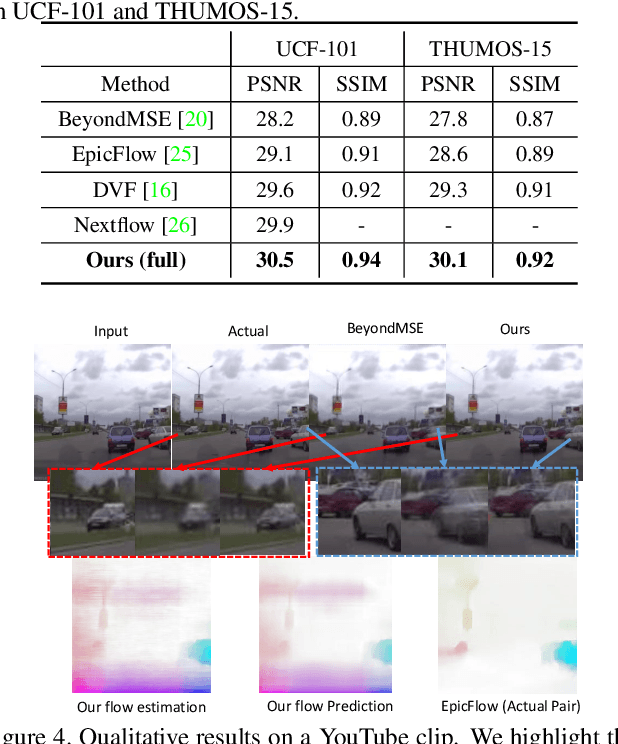
Future frame prediction in videos is a promising avenue for unsupervised video representation learning. Video frames are naturally generated by the inherent pixel flows from preceding frames based on the appearance and motion dynamics in the video. However, existing methods focus on directly hallucinating pixel values, resulting in blurry predictions. In this paper, we develop a dual motion Generative Adversarial Net (GAN) architecture, which learns to explicitly enforce future-frame predictions to be consistent with the pixel-wise flows in the video through a dual-learning mechanism. The primal future-frame prediction and dual future-flow prediction form a closed loop, generating informative feedback signals to each other for better video prediction. To make both synthesized future frames and flows indistinguishable from reality, a dual adversarial training method is proposed to ensure that the future-flow prediction is able to help infer realistic future-frames, while the future-frame prediction in turn leads to realistic optical flows. Our dual motion GAN also handles natural motion uncertainty in different pixel locations with a new probabilistic motion encoder, which is based on variational autoencoders. Extensive experiments demonstrate that the proposed dual motion GAN significantly outperforms state-of-the-art approaches on synthesizing new video frames and predicting future flows. Our model generalizes well across diverse visual scenes and shows superiority in unsupervised video representation learning.
Generative Semantic Manipulation with Contrasting GAN
Aug 01, 2017



Generative Adversarial Networks (GANs) have recently achieved significant improvement on paired/unpaired image-to-image translation, such as photo$\rightarrow$ sketch and artist painting style transfer. However, existing models can only be capable of transferring the low-level information (e.g. color or texture changes), but fail to edit high-level semantic meanings (e.g., geometric structure or content) of objects. On the other hand, while some researches can synthesize compelling real-world images given a class label or caption, they cannot condition on arbitrary shapes or structures, which largely limits their application scenarios and interpretive capability of model results. In this work, we focus on a more challenging semantic manipulation task, which aims to modify the semantic meaning of an object while preserving its own characteristics (e.g. viewpoints and shapes), such as cow$\rightarrow$sheep, motor$\rightarrow$ bicycle, cat$\rightarrow$dog. To tackle such large semantic changes, we introduce a contrasting GAN (contrast-GAN) with a novel adversarial contrasting objective. Instead of directly making the synthesized samples close to target data as previous GANs did, our adversarial contrasting objective optimizes over the distance comparisons between samples, that is, enforcing the manipulated data be semantically closer to the real data with target category than the input data. Equipped with the new contrasting objective, a novel mask-conditional contrast-GAN architecture is proposed to enable disentangle image background with object semantic changes. Experiments on several semantic manipulation tasks on ImageNet and MSCOCO dataset show considerable performance gain by our contrast-GAN over other conditional GANs. Quantitative results further demonstrate the superiority of our model on generating manipulated results with high visual fidelity and reasonable object semantics.
Efficient Correlated Topic Modeling with Topic Embedding
Jul 01, 2017

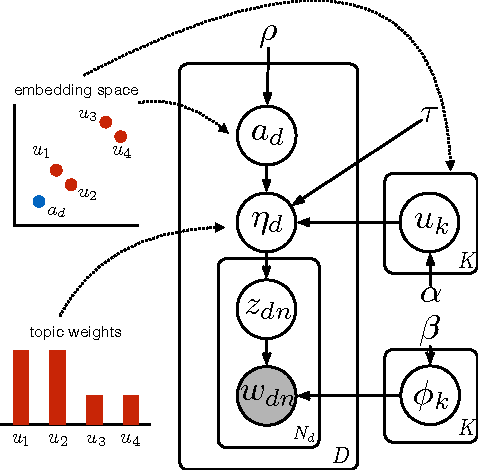

Correlated topic modeling has been limited to small model and problem sizes due to their high computational cost and poor scaling. In this paper, we propose a new model which learns compact topic embeddings and captures topic correlations through the closeness between the topic vectors. Our method enables efficient inference in the low-dimensional embedding space, reducing previous cubic or quadratic time complexity to linear w.r.t the topic size. We further speedup variational inference with a fast sampler to exploit sparsity of topic occurrence. Extensive experiments show that our approach is capable of handling model and data scales which are several orders of magnitude larger than existing correlation results, without sacrificing modeling quality by providing competitive or superior performance in document classification and retrieval.
Poseidon: An Efficient Communication Architecture for Distributed Deep Learning on GPU Clusters
Jun 11, 2017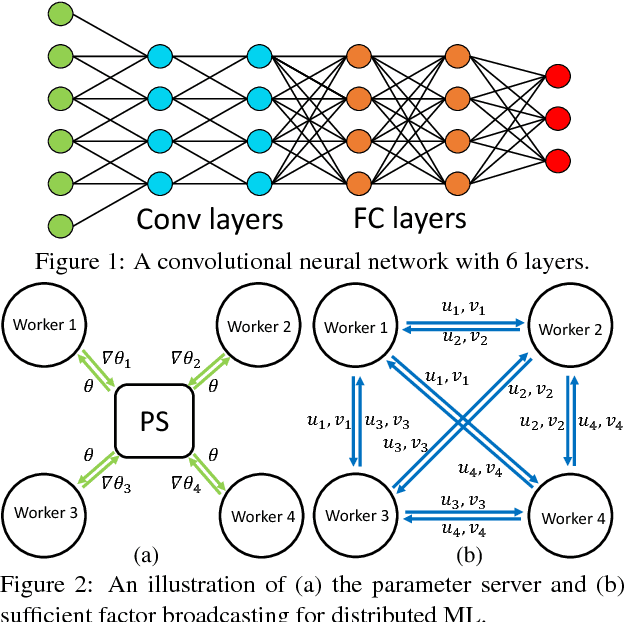
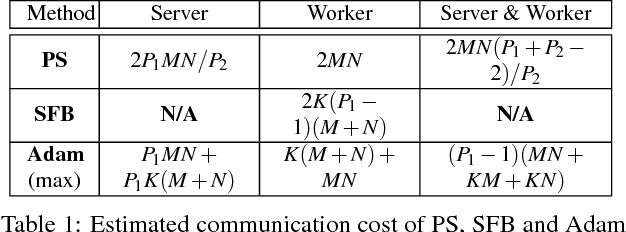
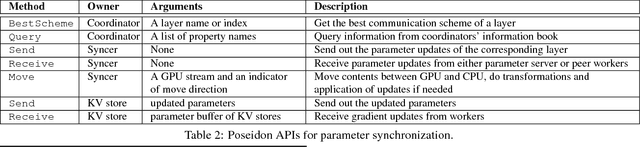
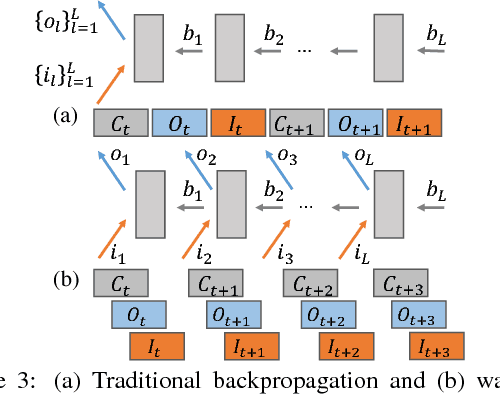
Deep learning models can take weeks to train on a single GPU-equipped machine, necessitating scaling out DL training to a GPU-cluster. However, current distributed DL implementations can scale poorly due to substantial parameter synchronization over the network, because the high throughput of GPUs allows more data batches to be processed per unit time than CPUs, leading to more frequent network synchronization. We present Poseidon, an efficient communication architecture for distributed DL on GPUs. Poseidon exploits the layered model structures in DL programs to overlap communication and computation, reducing bursty network communication. Moreover, Poseidon uses a hybrid communication scheme that optimizes the number of bytes required to synchronize each layer, according to layer properties and the number of machines. We show that Poseidon is applicable to different DL frameworks by plugging Poseidon into Caffe and TensorFlow. We show that Poseidon enables Caffe and TensorFlow to achieve 15.5x speed-up on 16 single-GPU machines, even with limited bandwidth (10GbE) and the challenging VGG19-22K network for image classification. Moreover, Poseidon-enabled TensorFlow achieves 31.5x speed-up with 32 single-GPU machines on Inception-V3, a 50% improvement over the open-source TensorFlow (20x speed-up).
Select-Additive Learning: Improving Generalization in Multimodal Sentiment Analysis
Apr 12, 2017
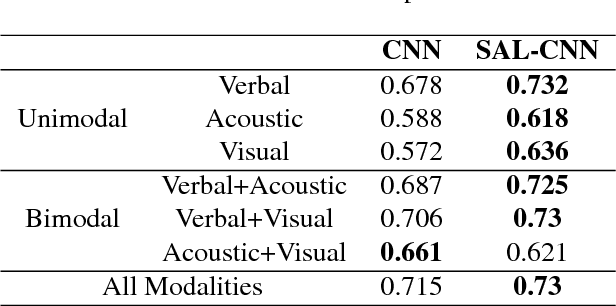
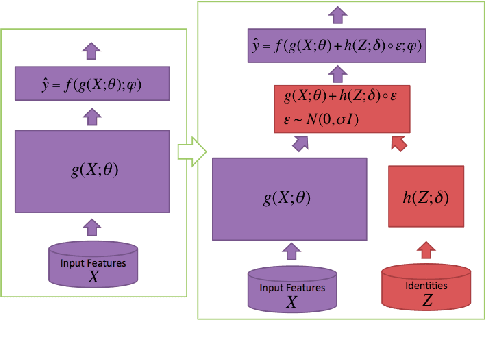
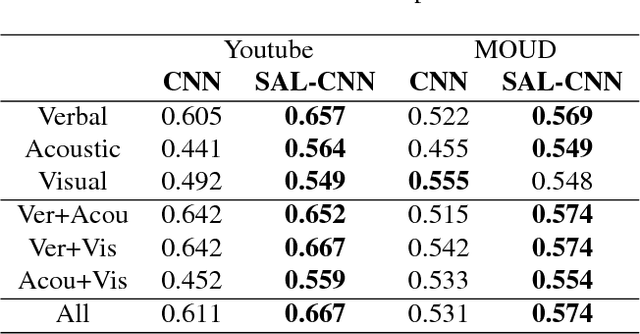
Multimodal sentiment analysis is drawing an increasing amount of attention these days. It enables mining of opinions in video reviews which are now available aplenty on online platforms. However, multimodal sentiment analysis has only a few high-quality data sets annotated for training machine learning algorithms. These limited resources restrict the generalizability of models, where, for example, the unique characteristics of a few speakers (e.g., wearing glasses) may become a confounding factor for the sentiment classification task. In this paper, we propose a Select-Additive Learning (SAL) procedure that improves the generalizability of trained neural networks for multimodal sentiment analysis. In our experiments, we show that our SAL approach improves prediction accuracy significantly in all three modalities (verbal, acoustic, visual), as well as in their fusion. Our results show that SAL, even when trained on one dataset, achieves good generalization across two new test datasets.
SCAN: Structure Correcting Adversarial Network for Organ Segmentation in Chest X-rays
Apr 10, 2017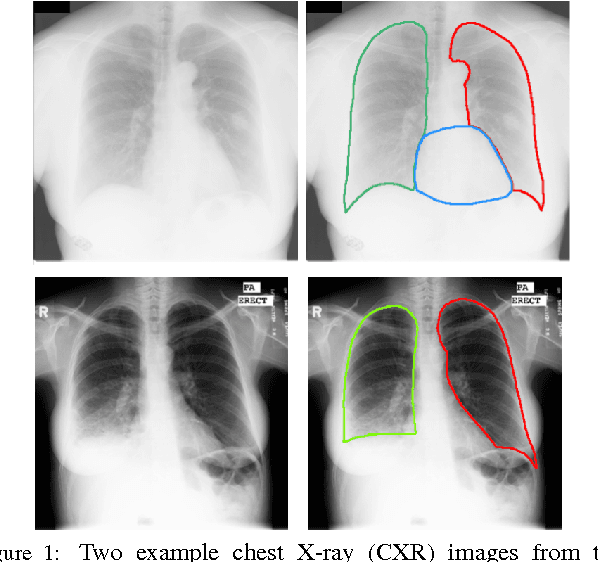
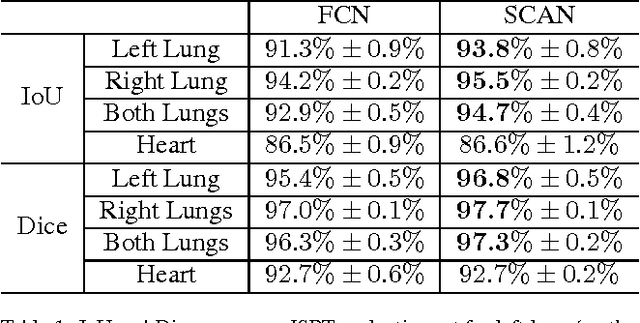
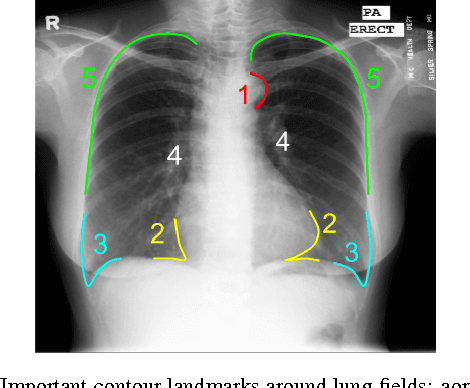
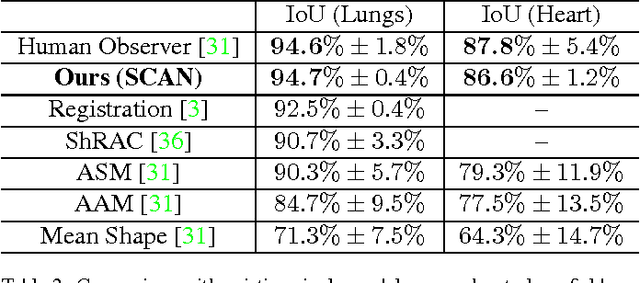
Chest X-ray (CXR) is one of the most commonly prescribed medical imaging procedures, often with over 2-10x more scans than other imaging modalities such as MRI, CT scan, and PET scans. These voluminous CXR scans place significant workloads on radiologists and medical practitioners. Organ segmentation is a crucial step to obtain effective computer-aided detection on CXR. In this work, we propose Structure Correcting Adversarial Network (SCAN) to segment lung fields and the heart in CXR images. SCAN incorporates a critic network to impose on the convolutional segmentation network the structural regularities emerging from human physiology. During training, the critic network learns to discriminate between the ground truth organ annotations from the masks synthesized by the segmentation network. Through this adversarial process the critic network learns the higher order structures and guides the segmentation model to achieve realistic segmentation outcomes. Extensive experiments show that our method produces highly accurate and natural segmentation. Using only very limited training data available, our model reaches human-level performance without relying on any existing trained model or dataset. Our method also generalizes well to CXR images from a different patient population and disease profiles, surpassing the current state-of-the-art.
Adversarial Connective-exploiting Networks for Implicit Discourse Relation Classification
Apr 01, 2017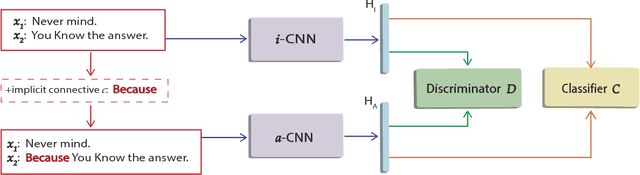
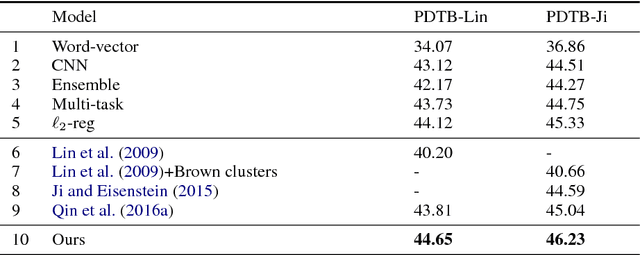
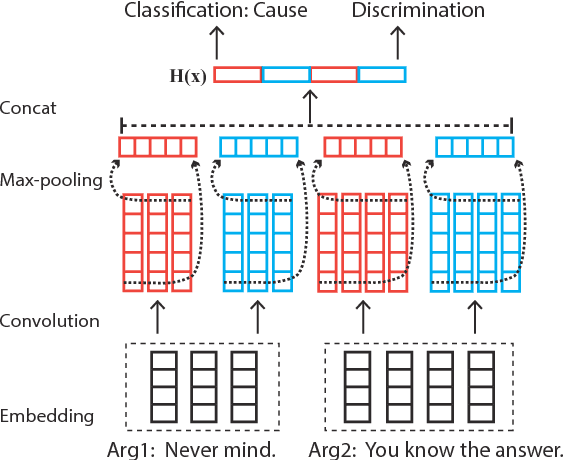
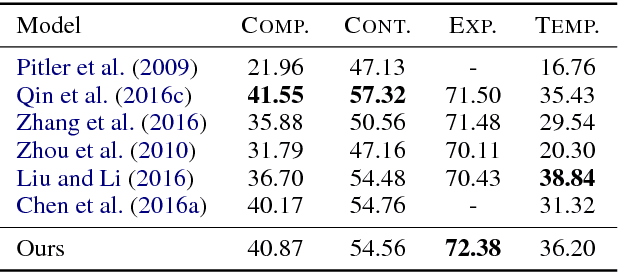
Implicit discourse relation classification is of great challenge due to the lack of connectives as strong linguistic cues, which motivates the use of annotated implicit connectives to improve the recognition. We propose a feature imitation framework in which an implicit relation network is driven to learn from another neural network with access to connectives, and thus encouraged to extract similarly salient features for accurate classification. We develop an adversarial model to enable an adaptive imitation scheme through competition between the implicit network and a rival feature discriminator. Our method effectively transfers discriminability of connectives to the implicit features, and achieves state-of-the-art performance on the PDTB benchmark.