 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel-Parallel Inference for Big Topic Models
Paper and Code
Nov 10, 2014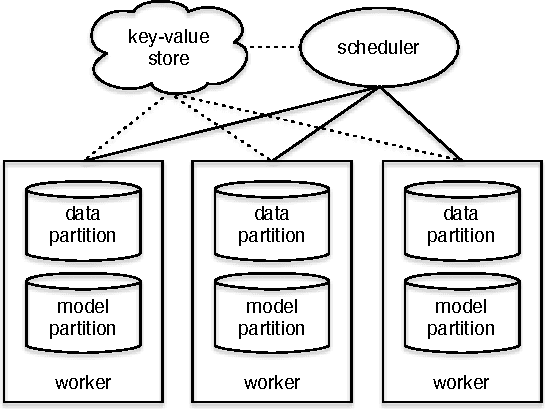

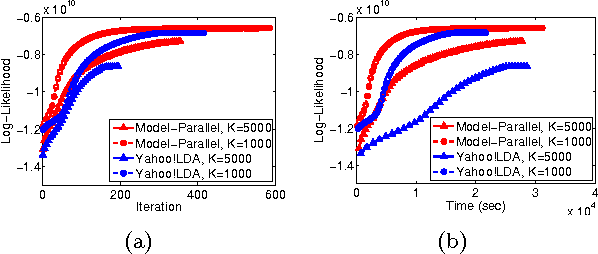
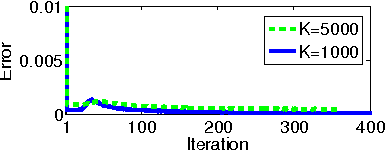
In real world industrial applications of topic modeling, the ability to capture gigantic conceptual space by learning an ultra-high dimensional topical representation, i.e., the so-called "big model", is becoming the next desideratum after enthusiasms on "big data", especially for fine-grained downstream tasks such as online advertising, where good performances are usually achieved by regression-based predictors built on millions if not billions of input features. The conventional data-parallel approach for training gigantic topic models turns out to be rather inefficient in utilizing the power of parallelism, due to the heavy dependency on a centralized image of "model". Big model size also poses another challenge on the storage, where available model size is bounded by the smallest RAM of nodes. To address these issues, we explore another type of parallelism, namely model-parallelism, which enables training of disjoint blocks of a big topic model in parallel. By integrating data-parallelism with model-parallelism, we show that dependencies between distributed elements can be handled seamlessly, achieving not only faster convergence but also an ability to tackle significantly bigger model size. We describe an architecture for model-parallel inference of LDA, and present a variant of collapsed Gibbs sampling algorithm tailored for it. Experimental results demonstrate the ability of this system to handle topic modeling with unprecedented amount of 200 billion model variables only on a low-end cluster with very limited computational resources and bandwidth.