 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLexically-constrained Text Generation through Commonsense Knowledge Extraction and Injection
Dec 19, 2020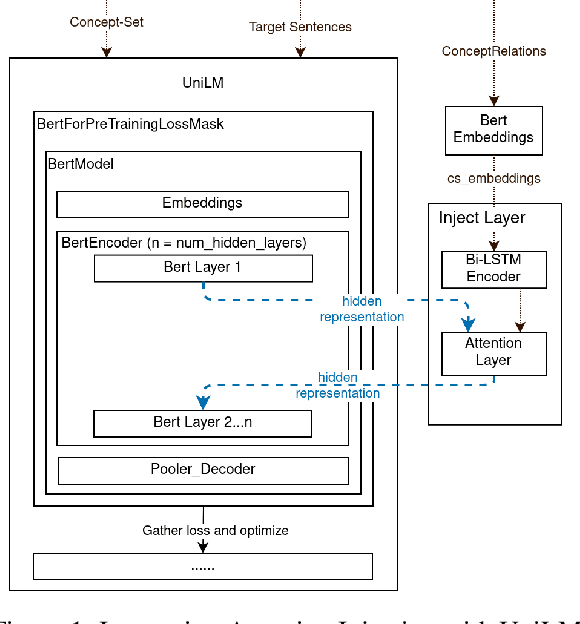


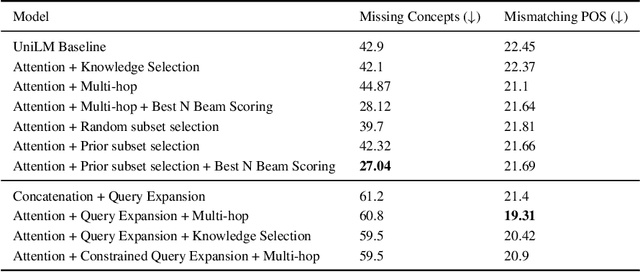
Conditional text generation has been a challenging task that is yet to see human-level performance from state-of-the-art models. In this work, we specifically focus on the Commongen benchmark, wherein the aim is to generate a plausible sentence for a given set of input concepts. Despite advances in other tasks, large pre-trained language models that are fine-tuned on this dataset often produce sentences that are syntactically correct but qualitatively deviate from a human understanding of common sense. Furthermore, generated sequences are unable to fulfill such lexical requirements as matching part-of-speech and full concept coverage. In this paper, we explore how commonsense knowledge graphs can enhance model performance, with respect to commonsense reasoning and lexically-constrained decoding. We propose strategies for enhancing the semantic correctness of the generated text, which we accomplish through: extracting commonsense relations from Conceptnet, injecting these relations into the Unified Language Model (UniLM) through attention mechanisms, and enforcing the aforementioned lexical requirements through output constraints. By performing several ablations, we find that commonsense injection enables the generation of sentences that are more aligned with human understanding, while remaining compliant with lexical requirements.
Knowledge-driven Self-supervision for Zero-shot Commonsense Question Answering
Nov 07, 2020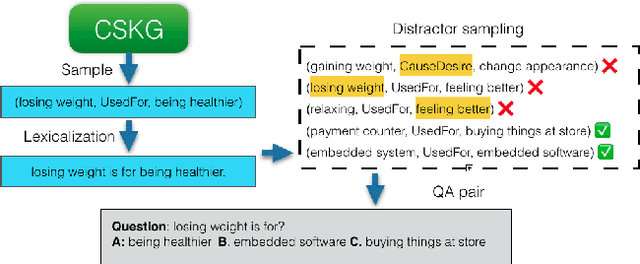

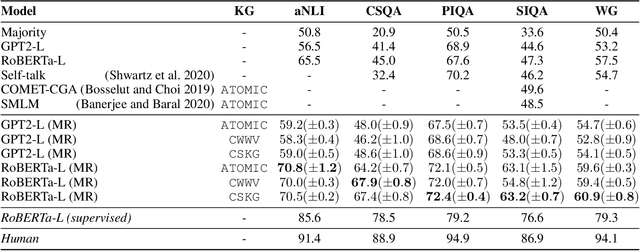
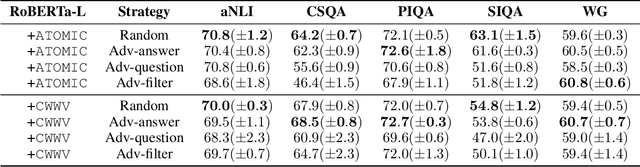
Recent developments in pre-trained neural language modeling have led to leaps in accuracy on commonsense question-answering benchmarks. However, there is increasing concern that models overfit to specific tasks, without learning to utilize external knowledge or perform general semantic reasoning. In contrast, zero-shot evaluations have shown promise as a more robust measure of a model's general reasoning abilities. In this paper, we propose a novel neuro-symbolic framework for zero-shot question answering across commonsense tasks. Guided by a set of hypotheses, the framework studies how to transform various pre-existing knowledge resources into a form that is most effective for pre-training models. We vary the set of language models, training regimes, knowledge sources, and data generation strategies, and measure their impact across tasks. Extending on prior work, we devise and compare four constrained distractor-sampling strategies. We provide empirical results across five commonsense question-answering tasks with data generated from five external knowledge resources. We show that, while an individual knowledge graph is better suited for specific tasks, a global knowledge graph brings consistent gains across different tasks. In addition, both preserving the structure of the task as well as generating fair and informative questions help language models learn more effectively.
Towards Generalizable Neuro-Symbolic Systems for Commonsense Question Answering
Oct 30, 2019
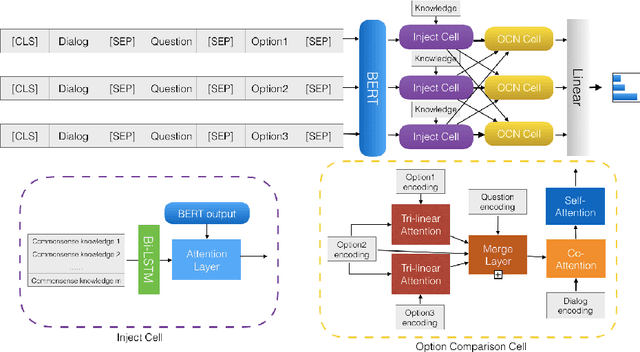


Non-extractive commonsense QA remains a challenging AI task, as it requires systems to reason about, synthesize, and gather disparate pieces of information, in order to generate responses to queries. Recent approaches on such tasks show increased performance, only when models are either pre-trained with additional information or when domain-specific heuristics are used, without any special consideration regarding the knowledge resource type. In this paper, we perform a survey of recent commonsense QA methods and we provide a systematic analysis of popular knowledge resources and knowledge-integration methods, across benchmarks from multiple commonsense datasets. Our results and analysis show that attention-based injection seems to be a preferable choice for knowledge integration and that the degree of domain overlap, between knowledge bases and datasets, plays a crucial role in determining model success.
Pruning Algorithms for Low-Dimensional Non-metric k-NN Search: A Case Study
Oct 08, 2019

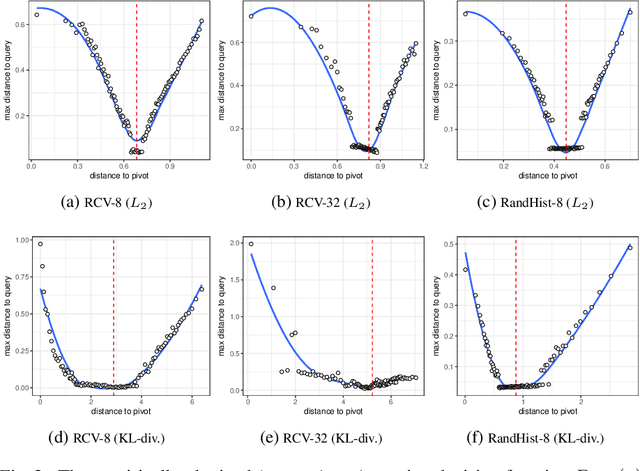
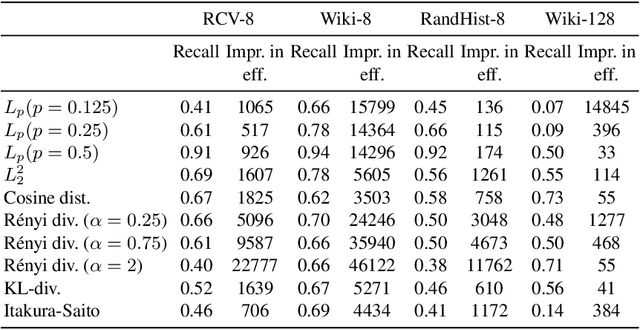
We focus on low-dimensional non-metric search, where tree-based approaches permit efficient and accurate retrieval while having short indexing time. These methods rely on space partitioning and require a pruning rule to avoid visiting unpromising parts. We consider two known data-driven approaches to extend these rules to non-metric spaces: TriGen and a piece-wise linear approximation of the pruning rule. We propose and evaluate two adaptations of TriGen to non-symmetric similarities (TriGen does not support non-symmetric distances). We also evaluate a hybrid of TriGen and the piece-wise linear approximation pruning. We find that this hybrid approach is often more effective than either of the pruning rules. We make our software publicly available.
Accurate and Fast Retrieval for Complex Non-metric Data via Neighborhood Graphs
Oct 08, 2019
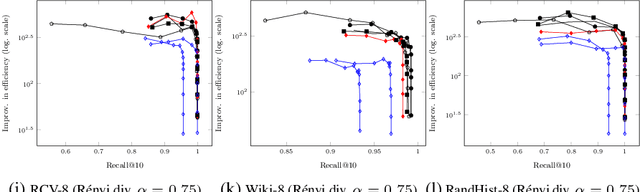

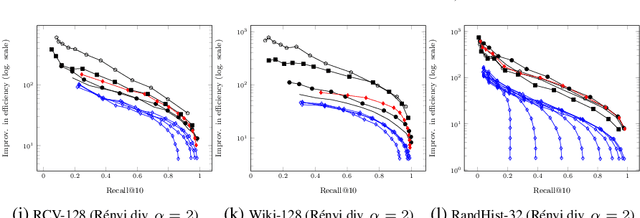
We demonstrate that a graph-based search algorithm-relying on the construction of an approximate neighborhood graph-can directly work with challenging non-metric and/or non-symmetric distances without resorting to metric-space mapping and/or distance symmetrization, which, in turn, lead to substantial performance degradation. Although the straightforward metrization and symmetrization is usually ineffective, we find that constructing an index using a modified, e.g., symmetrized, distance can improve performance. This observation paves a way to a new line of research of designing index-specific graph-construction distance functions.
Dr.Quad at MEDIQA 2019: Towards Textual Inference and Question Entailment using contextualized representations
Jul 23, 2019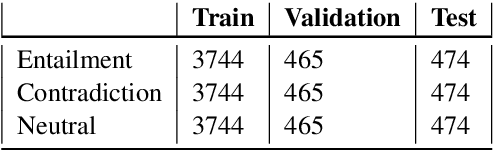
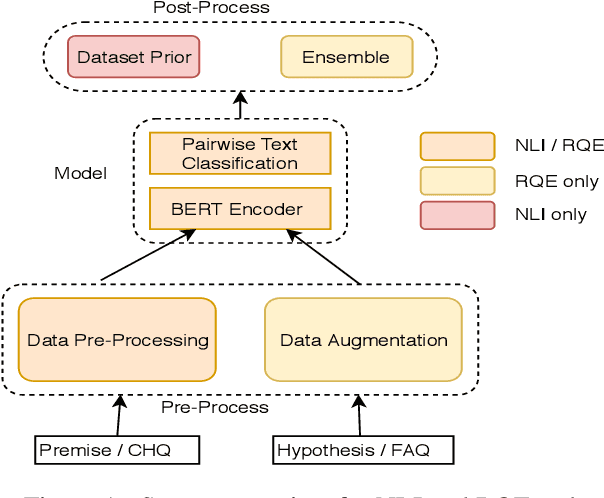

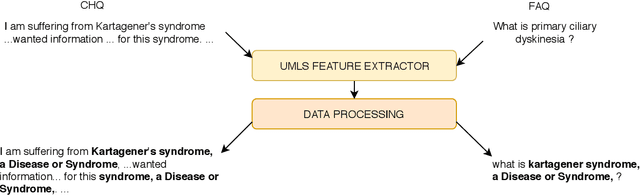
This paper presents the submissions by Team Dr.Quad to the ACL-BioNLP 2019 shared task on Textual Inference and Question Entailment in the Medical Domain. Our system is based on the prior work Liu et al. (2019) which uses a multi-task objective function for textual entailment. In this work, we explore different strategies for generalizing state-of-the-art language understanding models to the specialized medical domain. Our results on the shared task demonstrate that incorporating domain knowledge through data augmentation is a powerful strategy for addressing challenges posed by specialized domains such as medicine.
Pentagon at MEDIQA 2019: Multi-task Learning for Filtering and Re-ranking Answers using Language Inference and Question Entailment
Jul 01, 2019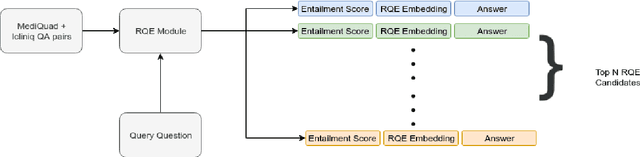
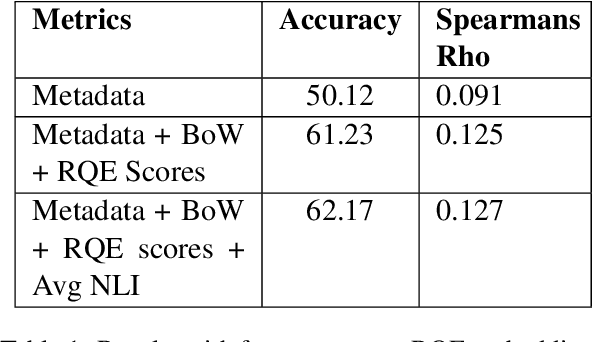
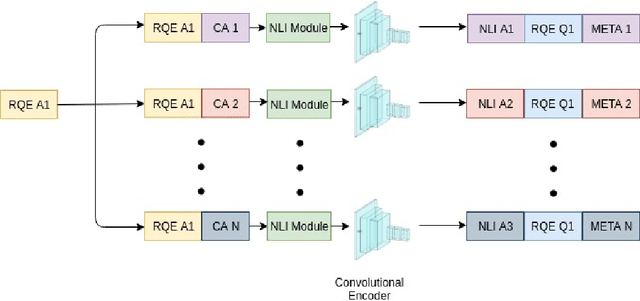
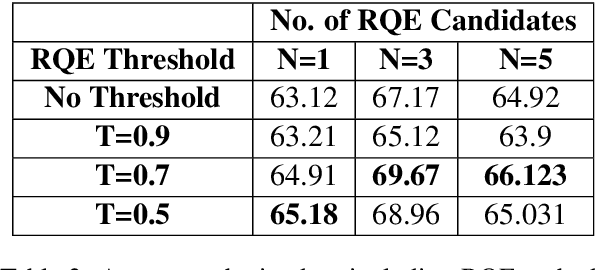
Parallel deep learning architectures like fine-tuned BERT and MT-DNN, have quickly become the state of the art, bypassing previous deep and shallow learning methods by a large margin. More recently, pre-trained models from large related datasets have been able to perform well on many downstream tasks by just fine-tuning on domain-specific datasets . However, using powerful models on non-trivial tasks, such as ranking and large document classification, still remains a challenge due to input size limitations of parallel architecture and extremely small datasets (insufficient for fine-tuning). In this work, we introduce an end-to-end system, trained in a multi-task setting, to filter and re-rank answers in the medical domain. We use task-specific pre-trained models as deep feature extractors. Our model achieves the highest Spearman's Rho and Mean Reciprocal Rank of 0.338 and 0.9622 respectively, on the ACL-BioNLP workshop MediQA Question Answering shared-task.
Comparative Analysis of Neural QA models on SQuAD
Jun 18, 2018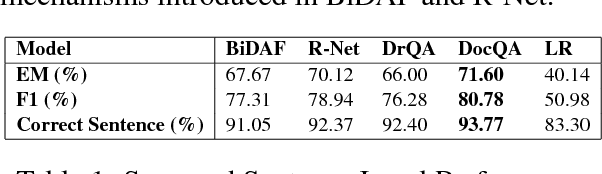
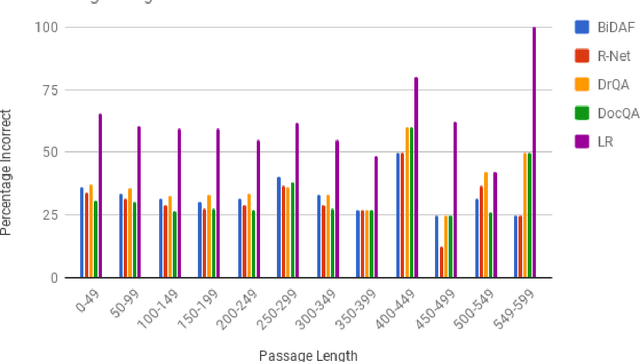
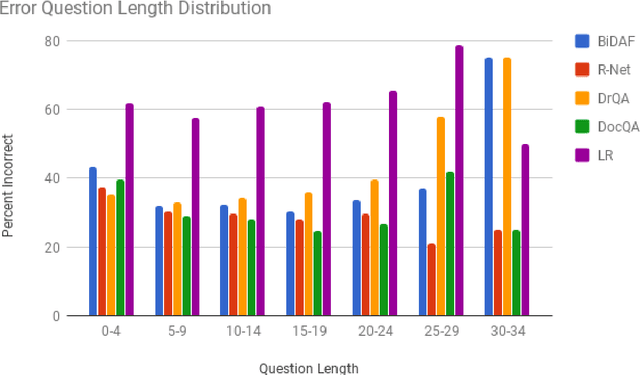
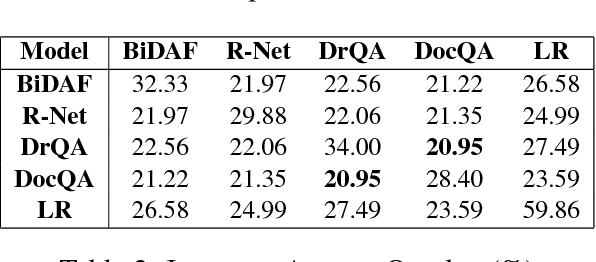
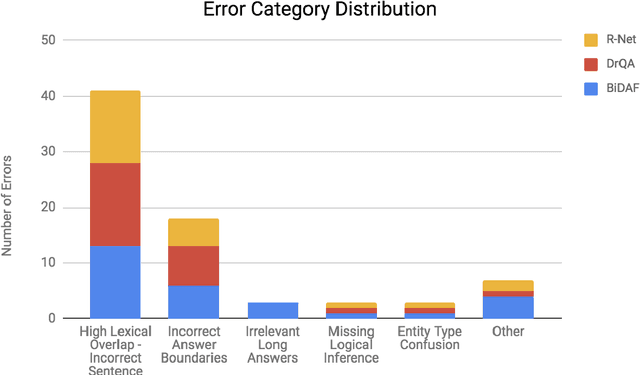
The task of Question Answering has gained prominence in the past few decades for testing the ability of machines to understand natural language. Large datasets for Machine Reading have led to the development of neural models that cater to deeper language understanding compared to information retrieval tasks. Different components in these neural architectures are intended to tackle different challenges. As a first step towards achieving generalization across multiple domains, we attempt to understand and compare the peculiarities of existing end-to-end neural models on the Stanford Question Answering Dataset (SQuAD) by performing quantitative as well as qualitative analysis of the results attained by each of them. We observed that prediction errors reflect certain model-specific biases, which we further discuss in this paper.
Towards Inference-Oriented Reading Comprehension: ParallelQA
May 10, 2018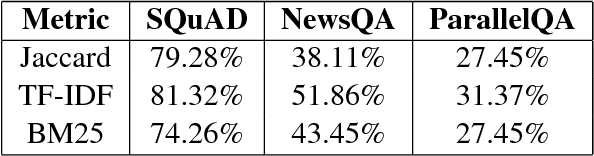
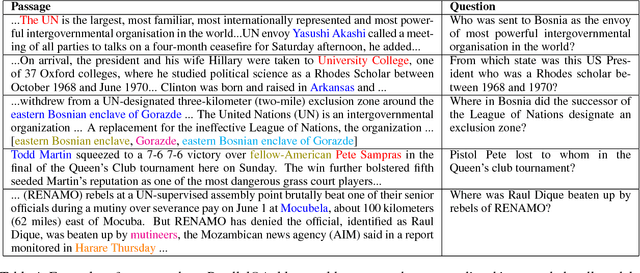

In this paper, we investigate the tendency of end-to-end neural Machine Reading Comprehension (MRC) models to match shallow patterns rather than perform inference-oriented reasoning on RC benchmarks. We aim to test the ability of these systems to answer questions which focus on referential inference. We propose ParallelQA, a strategy to formulate such questions using parallel passages. We also demonstrate that existing neural models fail to generalize well to this setting.
CMU LiveMedQA at TREC 2017 LiveQA: A Consumer Health Question Answering System
Nov 15, 2017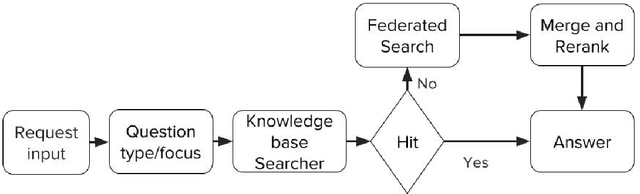

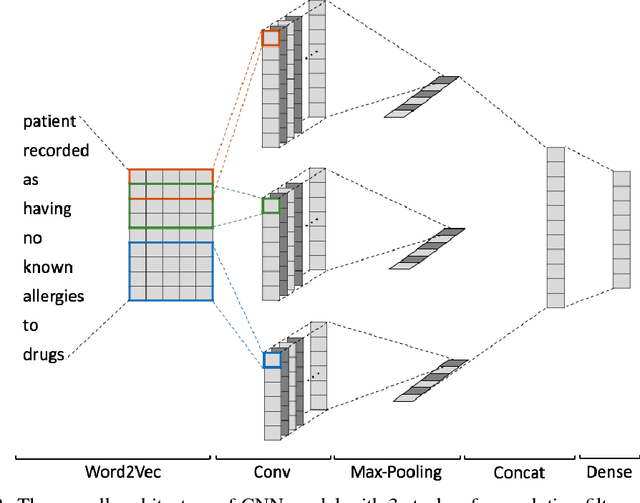
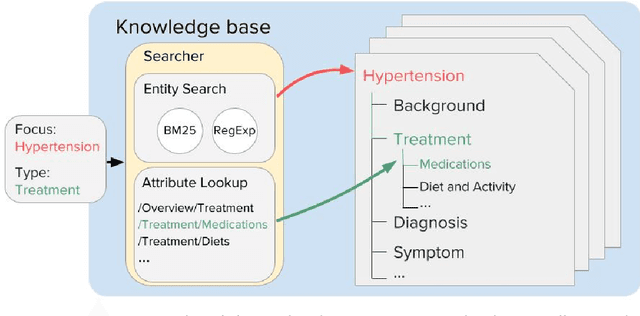
In this paper, we present LiveMedQA, a question answering system that is optimized for consumer health question. On top of the general QA system pipeline, we introduce several new features that aim to exploit domain-specific knowledge and entity structures for better performance. This includes a question type/focus analyzer based on deep text classification model, a tree-based knowledge graph for answer generation and a complementary structure-aware searcher for answer retrieval. LiveMedQA system is evaluated in the TREC 2017 LiveQA medical subtask, where it received an average score of 0.356 on a 3 point scale. Evaluation results revealed 3 substantial drawbacks in current LiveMedQA system, based on which we provide a detailed discussion and propose a few solutions that constitute the main focus of our subsequent work.