 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuto-conditioned Recurrent Mixture Density Networks for Learning Generalizable Robot Skills
Mar 20, 2019
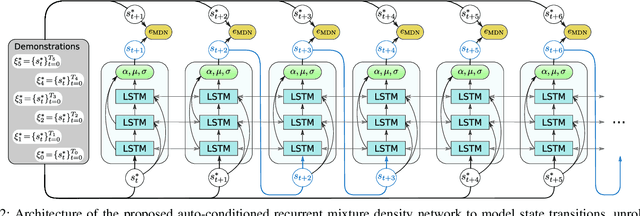
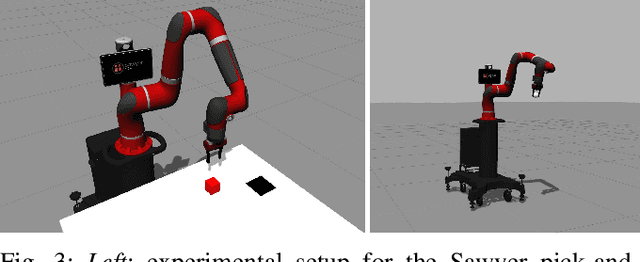
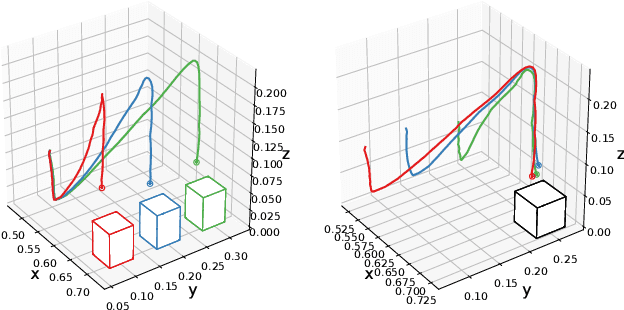
Personal robots assisting humans must perform complex manipulation tasks that are typically difficult to specify in traditional motion planning pipelines, where multiple objectives must be met and the high-level context be taken into consideration. Learning from demonstration (LfD) provides a promising way to learn these kind of complex manipulation skills even from non-technical users. However, it is challenging for existing LfD methods to efficiently learn skills that can generalize to task specifications that are not covered by demonstrations. In this paper, we introduce a state transition model (STM) that generates joint-space trajectories by imitating motions from expert behavior. Given a few demonstrations, we show in real robot experiments that the learned STM can quickly generalize to unseen tasks and synthesize motions having longer time horizons than the expert trajectories. Compared to conventional motion planners, our approach enables the robot to accomplish complex behaviors from high-level instructions without laborious hand-engineering of planning objectives, while being able to adapt to changing goals during the skill execution. In conjunction with a trajectory optimizer, our STM can construct a high-quality skeleton of a trajectory that can be further improved in smoothness and precision. In combination with a learned inverse dynamics model, we additionally present results where the STM is used as a high-level planner. A video of our experiments is available at https://youtu.be/85DX9Ojq-90
Scaling simulation-to-real transfer by learning composable robot skills
Nov 13, 2018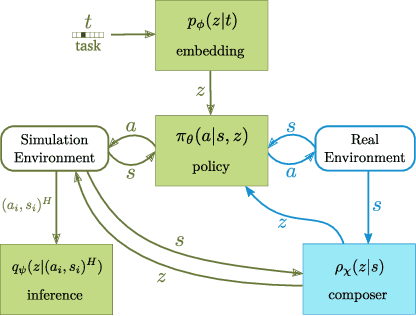
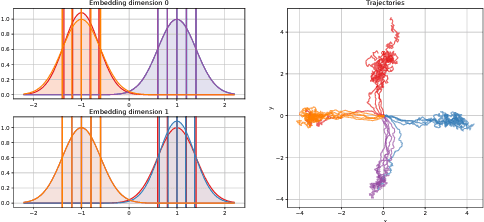

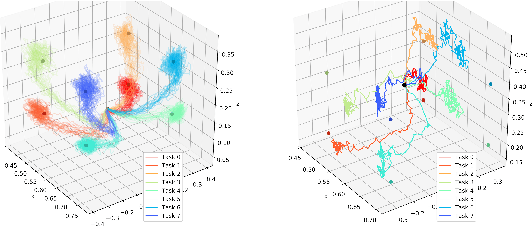
We present a novel solution to the problem of simulation-to-real transfer, which builds on recent advances in robot skill decomposition. Rather than focusing on minimizing the simulation-reality gap, we learn a set of diverse policies that are parameterized in a way that makes them easily reusable. This diversity and parameterization of low-level skills allows us to find a transferable policy that is able to use combinations and variations of different skills to solve more complex, high-level tasks. In particular, we first use simulation to jointly learn a policy for a set of low-level skills, and a "skill embedding" parameterization which can be used to compose them. Later, we learn high-level policies which actuate the low-level policies via this skill embedding parameterization. The high-level policies encode how and when to reuse the low-level skills together to achieve specific high-level tasks. Importantly, our method learns to control a real robot in joint-space to achieve these high-level tasks with little or no on-robot time, despite the fact that the low-level policies may not be perfectly transferable from simulation to real, and that the low-level skills were not trained on any examples of high-level tasks. We illustrate the principles of our method using informative simulation experiments. We then verify its usefulness for real robotics problems by learning, transferring, and composing free-space and contact motion skills on a Sawyer robot using only joint-space control. We experiment with several techniques for composing pre-learned skills, and find that our method allows us to use both learning-based approaches and efficient search-based planning to achieve high-level tasks using only pre-learned skills.
Zero-Shot Skill Composition and Simulation-to-Real Transfer by Learning Task Representations
Nov 13, 2018

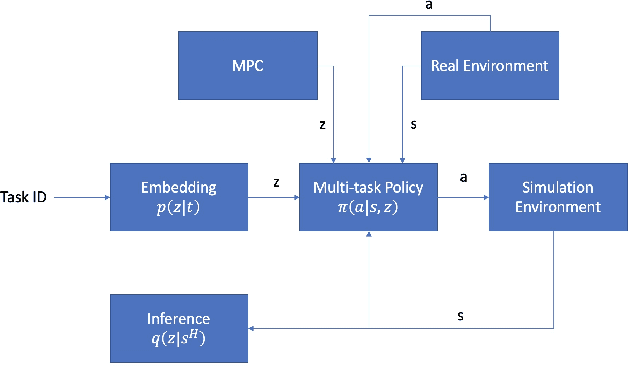
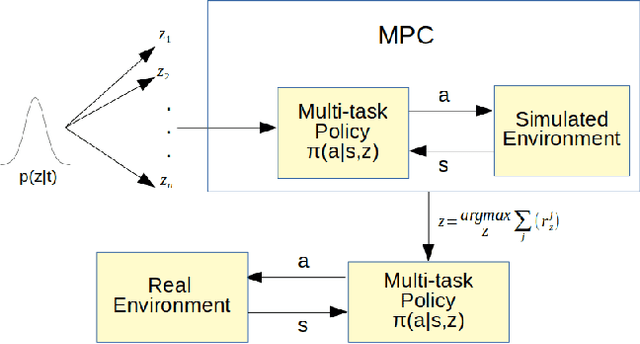
Simulation-to-real transfer is an important strategy for making reinforcement learning practical with real robots. Successful sim-to-real transfer systems have difficulty producing policies which generalize across tasks, despite training for thousands of hours equivalent real robot time. To address this shortcoming, we present a novel approach to efficiently learning new robotic skills directly on a real robot, based on model-predictive control (MPC) and an algorithm for learning task representations. In short, we show how to reuse the simulation from the pre-training step of sim-to-real methods as a tool for foresight, allowing the sim-to-real policy adapt to unseen tasks. Rather than end-to-end learning policies for single tasks and attempting to transfer them, we first use simulation to simultaneously learn (1) a continuous parameterization (i.e. a skill embedding or latent) of task-appropriate primitive skills, and (2) a single policy for these skills which is conditioned on this representation. We then directly transfer our multi-skill policy to a real robot, and actuate the robot by choosing sequences of skill latents which actuate the policy, with each latent corresponding to a pre-learned primitive skill controller. We complete unseen tasks by choosing new sequences of skill latents to control the robot using MPC, where our MPC model is composed of the pre-trained skill policy executed in the simulation environment, run in parallel with the real robot. We discuss the background and principles of our method, detail its practical implementation, and evaluate its performance by using our method to train a real Sawyer Robot to achieve motion tasks such as drawing and block pushing.