 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeciphering Undersegmented Ancient Scripts Using Phonetic Prior
Oct 21, 2020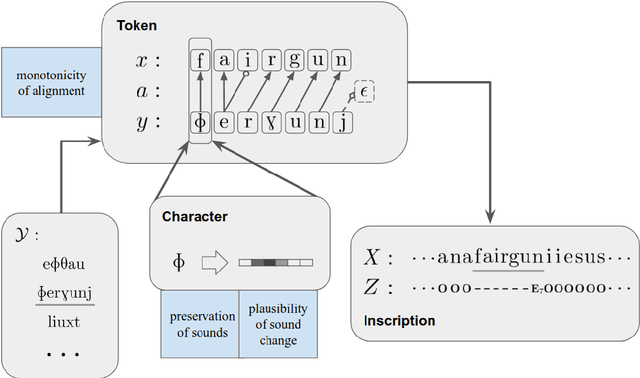

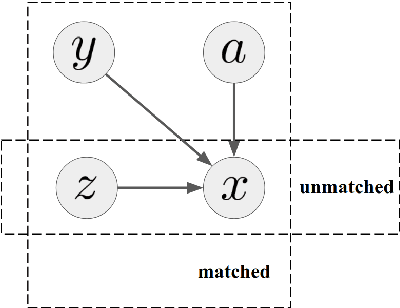
Most undeciphered lost languages exhibit two characteristics that pose significant decipherment challenges: (1) the scripts are not fully segmented into words; (2) the closest known language is not determined. We propose a decipherment model that handles both of these challenges by building on rich linguistic constraints reflecting consistent patterns in historical sound change. We capture the natural phonological geometry by learning character embeddings based on the International Phonetic Alphabet (IPA). The resulting generative framework jointly models word segmentation and cognate alignment, informed by phonological constraints. We evaluate the model on both deciphered languages (Gothic, Ugaritic) and an undeciphered one (Iberian). The experiments show that incorporating phonetic geometry leads to clear and consistent gains. Additionally, we propose a measure for language closeness which correctly identifies related languages for Gothic and Ugaritic. For Iberian, the method does not show strong evidence supporting Basque as a related language, concurring with the favored position by the current scholarship.
Towards Debiasing Fact Verification Models
Aug 31, 2019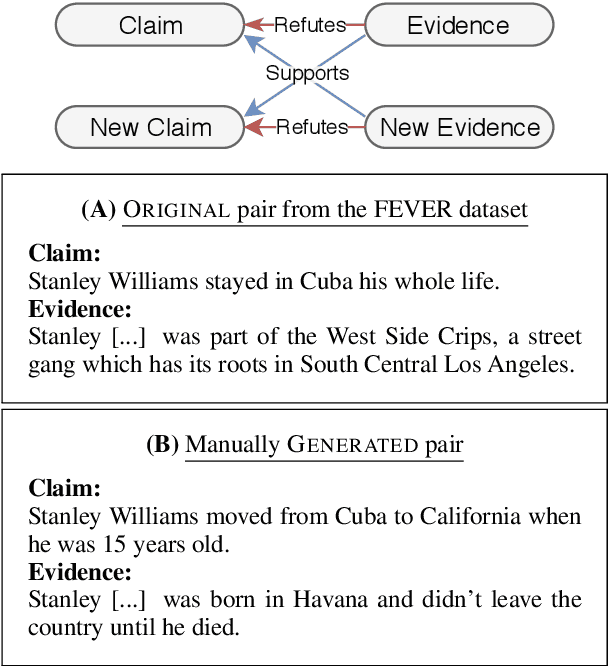
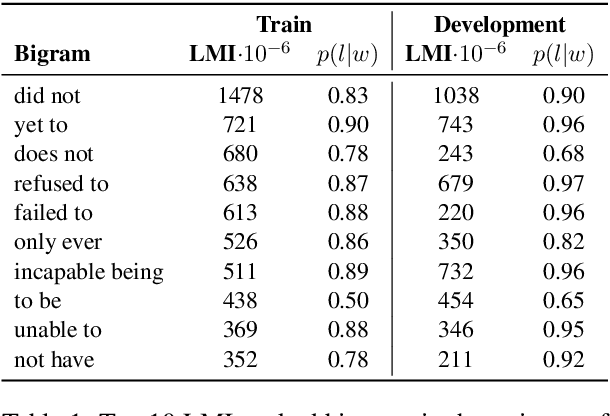
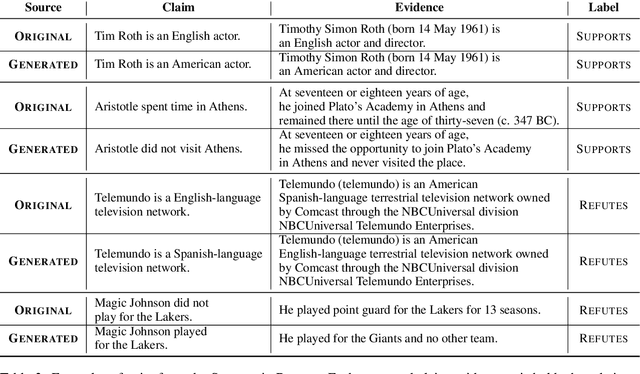
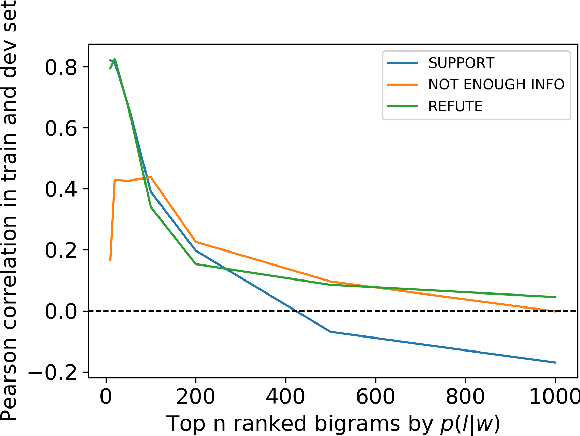
Fact verification requires validating a claim in the context of evidence. We show, however, that in the popular FEVER dataset this might not necessarily be the case. Claim-only classifiers perform competitively with top evidence-aware models. In this paper, we investigate the cause of this phenomenon, identifying strong cues for predicting labels solely based on the claim, without considering any evidence. We create an evaluation set that avoids those idiosyncrasies. The performance of FEVER-trained models significantly drops when evaluated on this test set. Therefore, we introduce a regularization method which alleviates the effect of bias in the training data, obtaining improvements on the newly created test set. This work is a step towards a more sound evaluation of reasoning capabilities in fact verification models.
A Structured Distributional Model of Sentence Meaning and Processing
Jun 17, 2019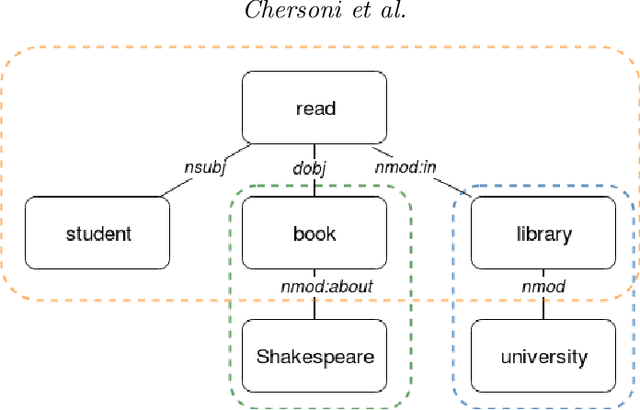

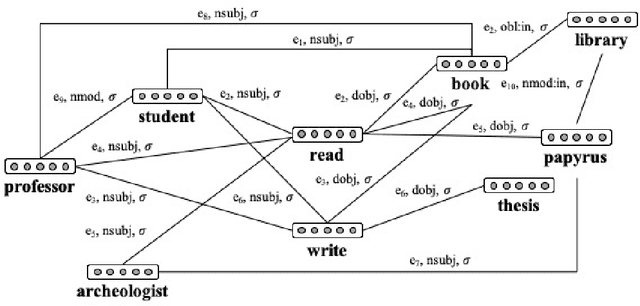
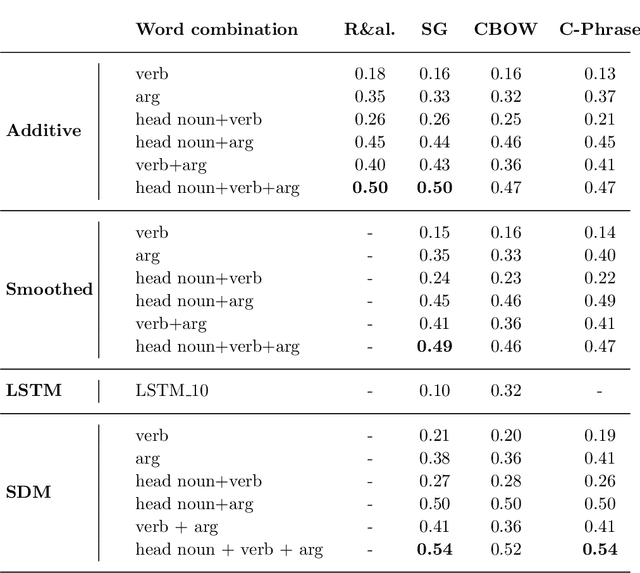
Most compositional distributional semantic models represent sentence meaning with a single vector. In this paper, we propose a Structured Distributional Model (SDM) that combines word embeddings with formal semantics and is based on the assumption that sentences represent events and situations. The semantic representation of a sentence is a formal structure derived from Discourse Representation Theory and containing distributional vectors. This structure is dynamically and incrementally built by integrating knowledge about events and their typical participants, as they are activated by lexical items. Event knowledge is modeled as a graph extracted from parsed corpora and encoding roles and relationships between participants that are represented as distributional vectors. SDM is grounded on extensive psycholinguistic research showing that generalized knowledge about events stored in semantic memory plays a key role in sentence comprehension. We evaluate SDM on two recently introduced compositionality datasets, and our results show that combining a simple compositional model with event knowledge constantly improves performances, even with different types of word embeddings.
Unsupervised Text Style Transfer via Iterative Matching and Translation
Jan 31, 2019
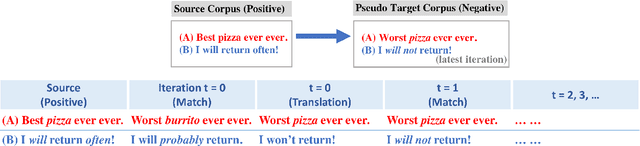
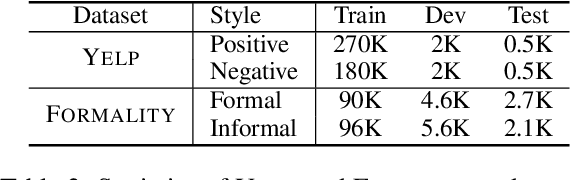
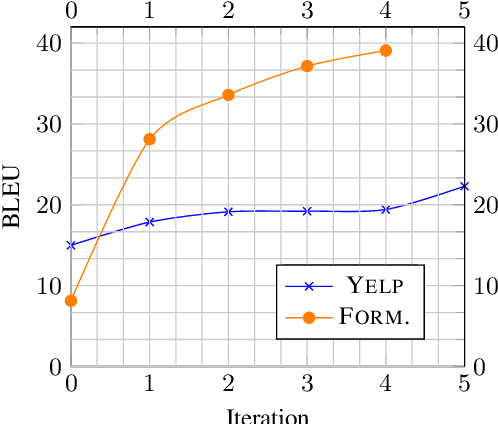
Text style transfer seeks to learn how to automatically rewrite sentences from a source domain to the target domain in different styles, while simultaneously preserving their semantic contents. A major challenge in this task stems from the lack of parallel data that connects the source and target styles. Existing approaches try to disentangle content and style, but this is quite difficult and often results in poor content-preservation and grammaticality. In contrast, we propose a novel approach by first constructing a pseudo-parallel resource that aligns a subset of sentences with similar content between source and target corpus. And then a standard sequence-to-sequence model can be applied to learn the style transfer. Subsequently, we iteratively refine the learned style transfer function while improving upon the imperfections in our original alignment. Our method is applied to the tasks of sentiment modification and formality transfer, where it outperforms state-of-the-art systems by a large margin. As an auxiliary contribution, we produced a publicly-available test set with human-generated style transfers for future community use.
GraphIE: A Graph-Based Framework for Information Extraction
Oct 31, 2018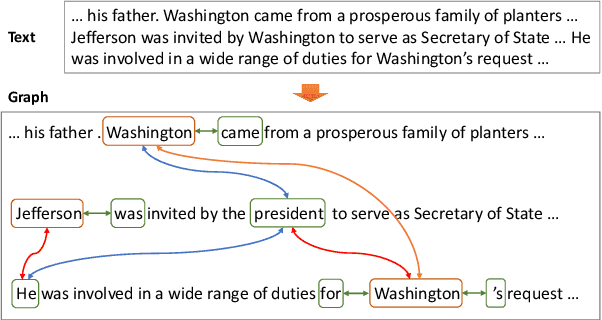


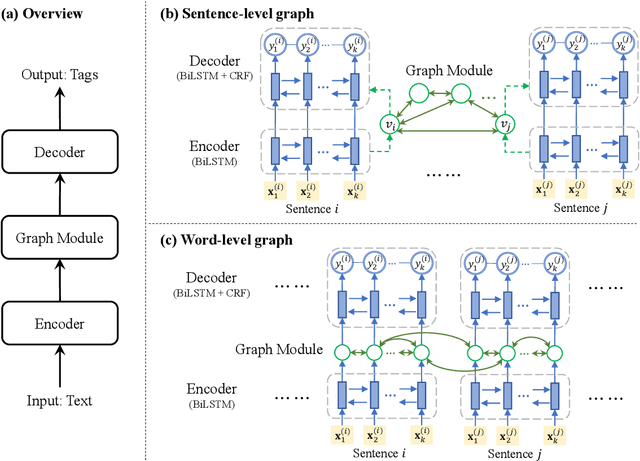
Most modern Information Extraction (IE) systems are implemented as sequential taggers and focus on modelling local dependencies. Non-local and non-sequential context is, however, a valuable source of information to improve predictions. In this paper, we introduce GraphIE, a framework that operates over a graph representing both local and non-local dependencies between textual units (i.e. words or sentences). The algorithm propagates information between connected nodes through graph convolutions and exploits the richer representation to improve word level predictions. The framework is evaluated on three different tasks, namely social media, textual and visual information extraction. Results show that GraphIE outperforms a competitive baseline (BiLSTM+CRF) in all tasks by a significant margin.
A Rank-Based Similarity Metric for Word Embeddings
May 04, 2018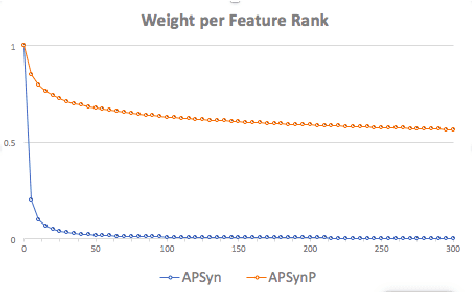

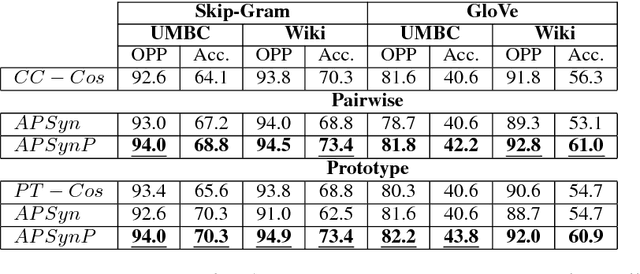
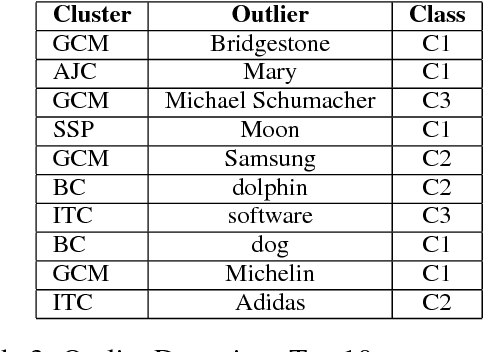
Word Embeddings have recently imposed themselves as a standard for representing word meaning in NLP. Semantic similarity between word pairs has become the most common evaluation benchmark for these representations, with vector cosine being typically used as the only similarity metric. In this paper, we report experiments with a rank-based metric for WE, which performs comparably to vector cosine in similarity estimation and outperforms it in the recently-introduced and challenging task of outlier detection, thus suggesting that rank-based measures can improve clustering quality.
BomJi at SemEval-2018 Task 10: Combining Vector-, Pattern- and Graph-based Information to Identify Discriminative Attributes
Apr 30, 2018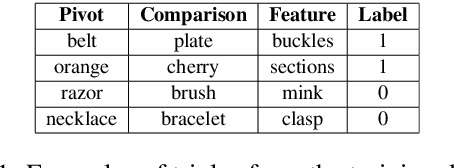
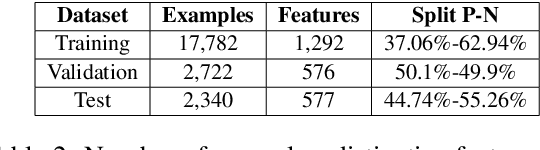
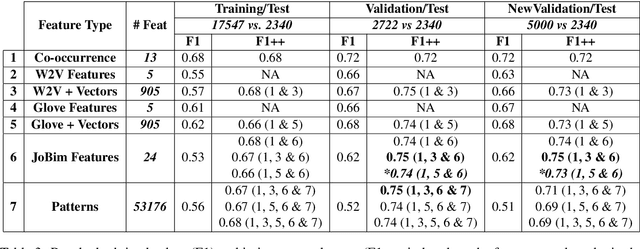
This paper describes BomJi, a supervised system for capturing discriminative attributes in word pairs (e.g. yellow as discriminative for banana over watermelon). The system relies on an XGB classifier trained on carefully engineered graph-, pattern- and word embedding based features. It participated in the SemEval- 2018 Task 10 on Capturing Discriminative Attributes, achieving an F1 score of 0:73 and ranking 2nd out of 26 participant systems.
Is Structure Necessary for Modeling Argument Expectations in Distributional Semantics?
Oct 03, 2017
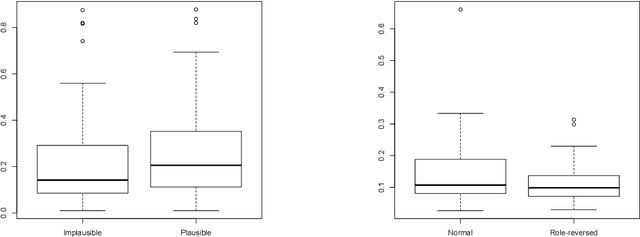
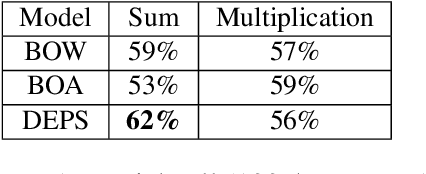
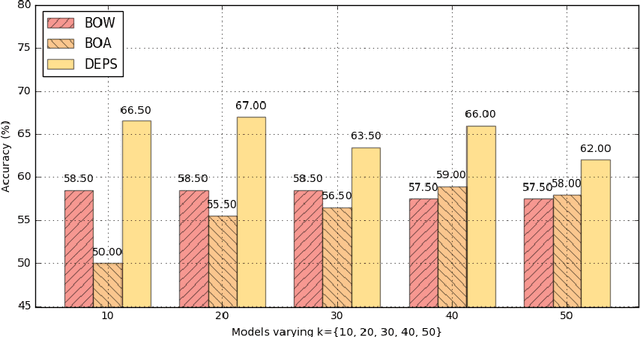
Despite the number of NLP studies dedicated to thematic fit estimation, little attention has been paid to the related task of composing and updating verb argument expectations. The few exceptions have mostly modeled this phenomenon with structured distributional models, implicitly assuming a similarly structured representation of events. Recent experimental evidence, however, suggests that human processing system could also exploit an unstructured "bag-of-arguments" type of event representation to predict upcoming input. In this paper, we re-implement a traditional structured model and adapt it to compare the different hypotheses concerning the degree of structure in our event knowledge, evaluating their relative performance in the task of the argument expectations update.
Measuring Thematic Fit with Distributional Feature Overlap
Jul 26, 2017
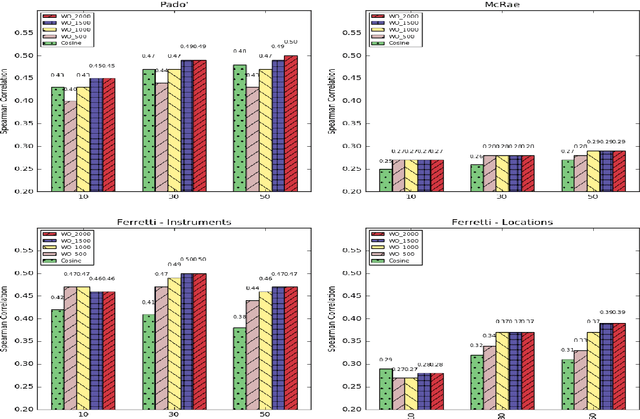
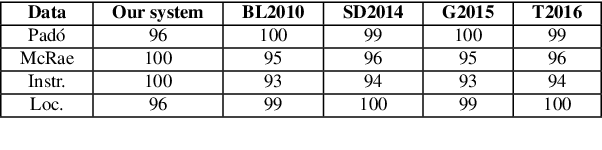
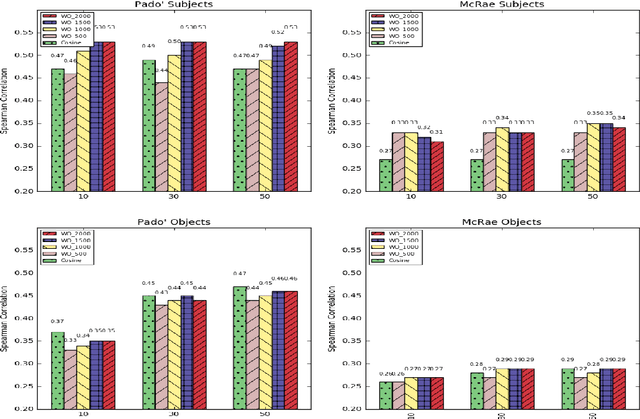
In this paper, we introduce a new distributional method for modeling predicate-argument thematic fit judgments. We use a syntax-based DSM to build a prototypical representation of verb-specific roles: for every verb, we extract the most salient second order contexts for each of its roles (i.e. the most salient dimensions of typical role fillers), and then we compute thematic fit as a weighted overlap between the top features of candidate fillers and role prototypes. Our experiments show that our method consistently outperforms a baseline re-implementing a state-of-the-art system, and achieves better or comparable results to those reported in the literature for the other unsupervised systems. Moreover, it provides an explicit representation of the features characterizing verb-specific semantic roles.
German in Flux: Detecting Metaphoric Change via Word Entropy
Jun 15, 2017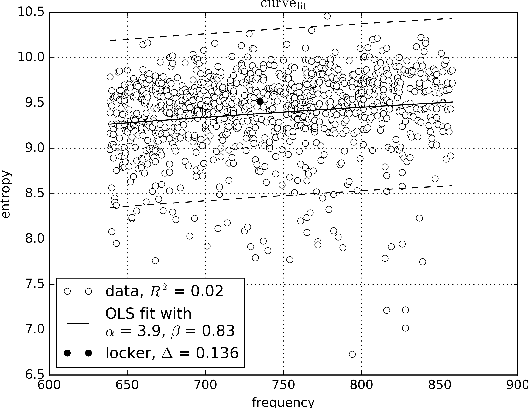
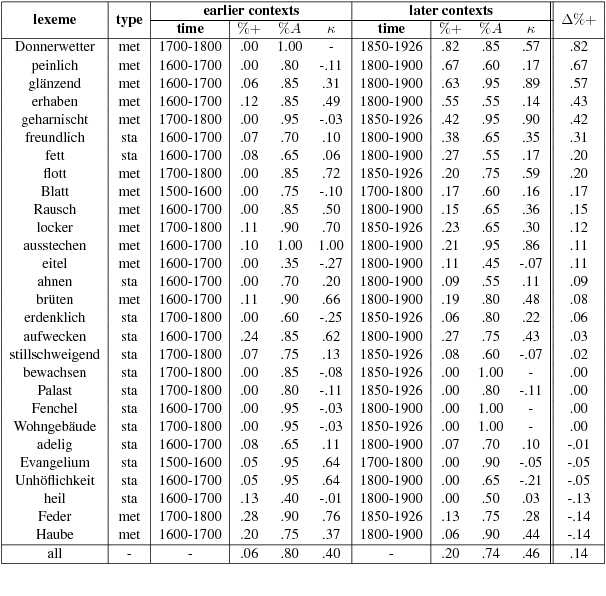

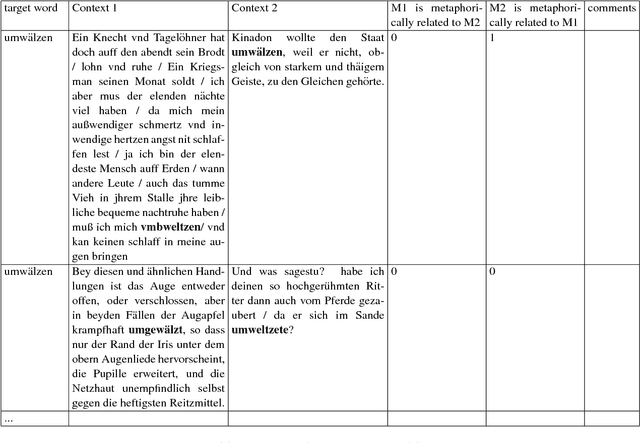
This paper explores the information-theoretic measure entropy to detect metaphoric change, transferring ideas from hypernym detection to research on language change. We also build the first diachronic test set for German as a standard for metaphoric change annotation. Our model shows high performance, is unsupervised, language-independent and generalizable to other processes of semantic change.