 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesign Principles for Lifelong Learning AI Accelerators
Oct 05, 2023Lifelong learning - an agent's ability to learn throughout its lifetime - is a hallmark of biological learning systems and a central challenge for artificial intelligence (AI). The development of lifelong learning algorithms could lead to a range of novel AI applications, but this will also require the development of appropriate hardware accelerators, particularly if the models are to be deployed on edge platforms, which have strict size, weight, and power constraints. Here, we explore the design of lifelong learning AI accelerators that are intended for deployment in untethered environments. We identify key desirable capabilities for lifelong learning accelerators and highlight metrics to evaluate such accelerators. We then discuss current edge AI accelerators and explore the future design of lifelong learning accelerators, considering the role that different emerging technologies could play.
Understanding and Improving Optimization in Predictive Coding Networks
May 23, 2023



Backpropagation (BP), the standard learning algorithm for artificial neural networks, is often considered biologically implausible. In contrast, the standard learning algorithm for predictive coding (PC) models in neuroscience, known as the inference learning algorithm (IL), is a promising, bio-plausible alternative. However, several challenges and questions hinder IL's application to real-world problems. For example, IL is computationally demanding, and without memory-intensive optimizers like Adam, IL may converge to poor local minima. Moreover, although IL can reduce loss more quickly than BP, the reasons for these speedups or their robustness remains unclear. In this paper, we tackle these challenges by 1) altering the standard implementation of PC circuits to substantially reduce computation, 2) developing a novel optimizer that improves the convergence of IL without increasing memory usage, and 3) establishing theoretical results that help elucidate the conditions under which IL is sensitive to second and higher-order information.
NeuroBench: Advancing Neuromorphic Computing through Collaborative, Fair and Representative Benchmarking
Apr 15, 2023



The field of neuromorphic computing holds great promise in terms of advancing computing efficiency and capabilities by following brain-inspired principles. However, the rich diversity of techniques employed in neuromorphic research has resulted in a lack of clear standards for benchmarking, hindering effective evaluation of the advantages and strengths of neuromorphic methods compared to traditional deep-learning-based methods. This paper presents a collaborative effort, bringing together members from academia and the industry, to define benchmarks for neuromorphic computing: NeuroBench. The goals of NeuroBench are to be a collaborative, fair, and representative benchmark suite developed by the community, for the community. In this paper, we discuss the challenges associated with benchmarking neuromorphic solutions, and outline the key features of NeuroBench. We believe that NeuroBench will be a significant step towards defining standards that can unify the goals of neuromorphic computing and drive its technological progress. Please visit neurobench.ai for the latest updates on the benchmark tasks and metrics.
Online Transformers with Spiking Neurons for Fast Prosthetic Hand Control
Mar 21, 2023



Transformers are state-of-the-art networks for most sequence processing tasks. However, the self-attention mechanism often used in Transformers requires large time windows for each computation step and thus makes them less suitable for online signal processing compared to Recurrent Neural Networks (RNNs). In this paper, instead of the self-attention mechanism, we use a sliding window attention mechanism. We show that this mechanism is more efficient for continuous signals with finite-range dependencies between input and target, and that we can use it to process sequences element-by-element, this making it compatible with online processing. We test our model on a finger position regression dataset (NinaproDB8) with Surface Electromyographic (sEMG) signals measured on the forearm skin to estimate muscle activities. Our approach sets the new state-of-the-art in terms of accuracy on this dataset while requiring only very short time windows of 3.5 ms at each inference step. Moreover, we increase the sparsity of the network using Leaky-Integrate and Fire (LIF) units, a bio-inspired neuron model that activates sparsely in time solely when crossing a threshold. We thus reduce the number of synaptic operations up to a factor of $\times5.3$ without loss of accuracy. Our results hold great promises for accurate and fast online processing of sEMG signals for smooth prosthetic hand control and is a step towards Transformers and Spiking Neural Networks (SNNs) co-integration for energy efficient temporal signal processing.
A Theoretical Framework for Inference Learning
Jun 01, 2022
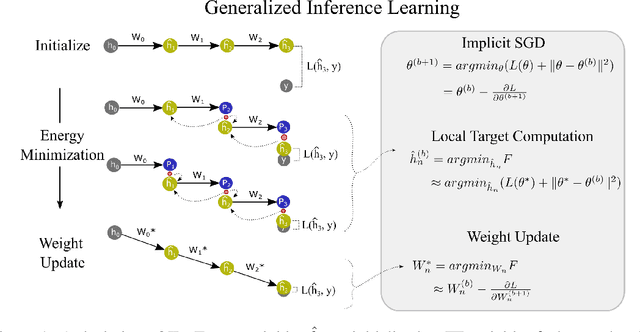
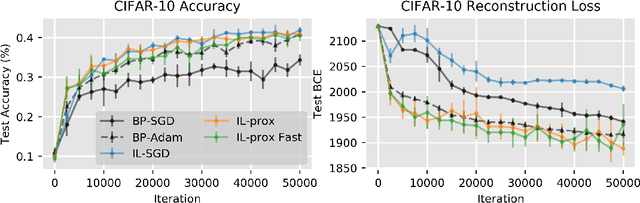
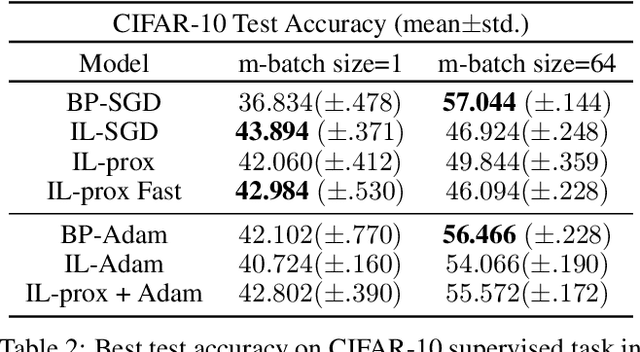
Backpropagation (BP) is the most successful and widely used algorithm in deep learning. However, the computations required by BP are challenging to reconcile with known neurobiology. This difficulty has stimulated interest in more biologically plausible alternatives to BP. One such algorithm is the inference learning algorithm (IL). IL has close connections to neurobiological models of cortical function and has achieved equal performance to BP on supervised learning and auto-associative tasks. In contrast to BP, however, the mathematical foundations of IL are not well-understood. Here, we develop a novel theoretical framework for IL. Our main result is that IL closely approximates an optimization method known as implicit stochastic gradient descent (implicit SGD), which is distinct from the explicit SGD implemented by BP. Our results further show how the standard implementation of IL can be altered to better approximate implicit SGD. Our novel implementation considerably improves the stability of IL across learning rates, which is consistent with our theory, as a key property of implicit SGD is its stability. We provide extensive simulation results that further support our theoretical interpretations and also demonstrate IL achieves quicker convergence when trained with small mini-batches while matching the performance of BP for large mini-batches.
Policy Distillation with Selective Input Gradient Regularization for Efficient Interpretability
May 18, 2022
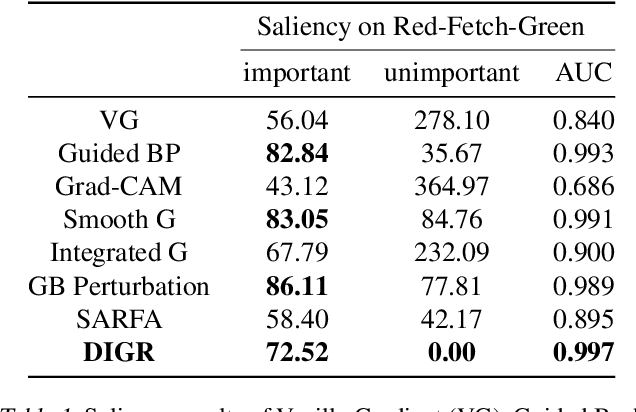
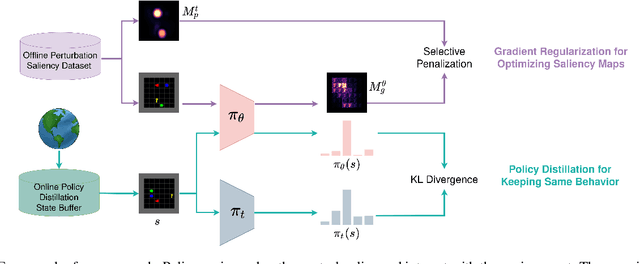
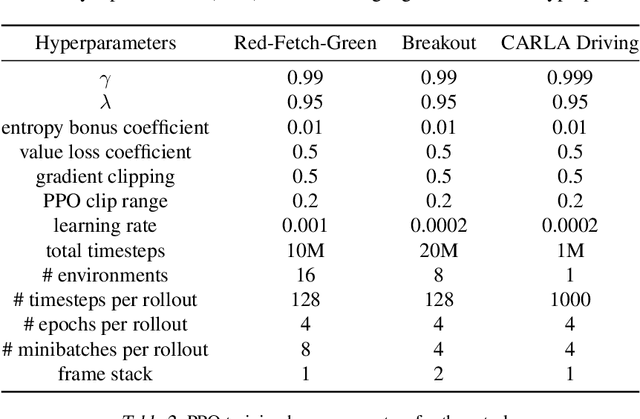
Although deep Reinforcement Learning (RL) has proven successful in a wide range of tasks, one challenge it faces is interpretability when applied to real-world problems. Saliency maps are frequently used to provide interpretability for deep neural networks. However, in the RL domain, existing saliency map approaches are either computationally expensive and thus cannot satisfy the real-time requirement of real-world scenarios or cannot produce interpretable saliency maps for RL policies. In this work, we propose an approach of Distillation with selective Input Gradient Regularization (DIGR) which uses policy distillation and input gradient regularization to produce new policies that achieve both high interpretability and computation efficiency in generating saliency maps. Our approach is also found to improve the robustness of RL policies to multiple adversarial attacks. We conduct experiments on three tasks, MiniGrid (Fetch Object), Atari (Breakout) and CARLA Autonomous Driving, to demonstrate the importance and effectiveness of our approach.
Meta-learning Spiking Neural Networks with Surrogate Gradient Descent
Jan 26, 2022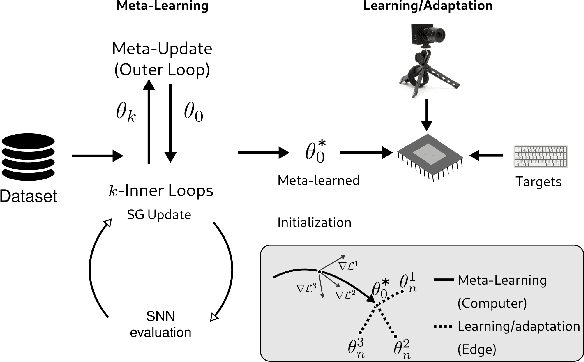
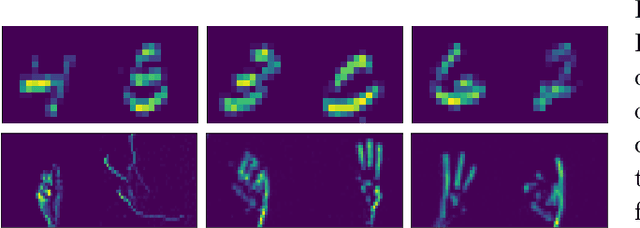
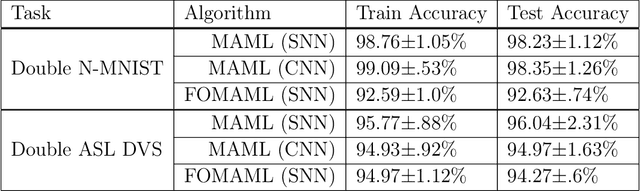
Adaptive "life-long" learning at the edge and during online task performance is an aspirational goal of AI research. Neuromorphic hardware implementing Spiking Neural Networks (SNNs) are particularly attractive in this regard, as their real-time, event-based, local computing paradigm makes them suitable for edge implementations and fast learning. However, the long and iterative learning that characterizes state-of-the-art SNN training is incompatible with the physical nature and real-time operation of neuromorphic hardware. Bi-level learning, such as meta-learning is increasingly used in deep learning to overcome these limitations. In this work, we demonstrate gradient-based meta-learning in SNNs using the surrogate gradient method that approximates the spiking threshold function for gradient estimations. Because surrogate gradients can be made twice differentiable, well-established, and effective second-order gradient meta-learning methods such as Model Agnostic Meta Learning (MAML) can be used. We show that SNNs meta-trained using MAML match or exceed the performance of conventional ANNs meta-trained with MAML on event-based meta-datasets. Furthermore, we demonstrate the specific advantages that accrue from meta-learning: fast learning without the requirement of high precision weights or gradients. Our results emphasize how meta-learning techniques can become instrumental for deploying neuromorphic learning technologies on real-world problems.
Training Spiking Neural Networks Using Lessons From Deep Learning
Oct 01, 2021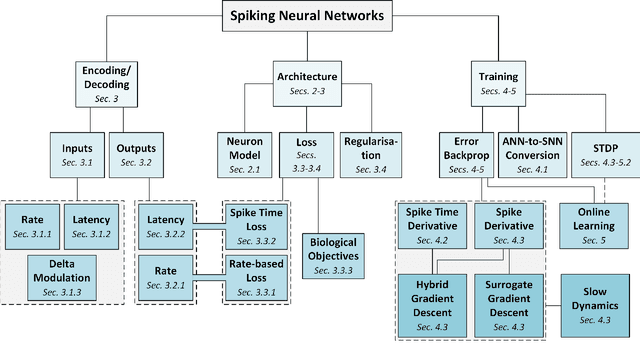

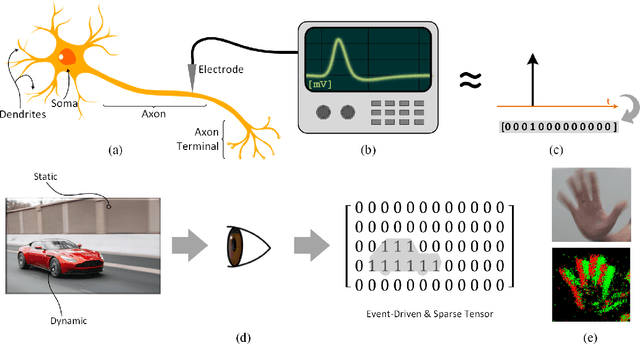

The brain is the perfect place to look for inspiration to develop more efficient neural networks. The inner workings of our synapses and neurons provide a glimpse at what the future of deep learning might look like. This paper serves as a tutorial and perspective showing how to apply the lessons learnt from several decades of research in deep learning, gradient descent, backpropagation and neuroscience to biologically plausible spiking neural neural networks. We also explore the delicate interplay between encoding data as spikes and the learning process; the challenges and solutions of applying gradient-based learning to spiking neural networks; the subtle link between temporal backpropagation and spike timing dependent plasticity, and how deep learning might move towards biologically plausible online learning. Some ideas are well accepted and commonly used amongst the neuromorphic engineering community, while others are presented or justified for the first time here. A series of companion interactive tutorials complementary to this paper using our Python package, snnTorch, are also made available: https://snntorch.readthedocs.io/en/latest/tutorials/index.html
Tightening the Biological Constraints on Gradient-Based Predictive Coding
Apr 30, 2021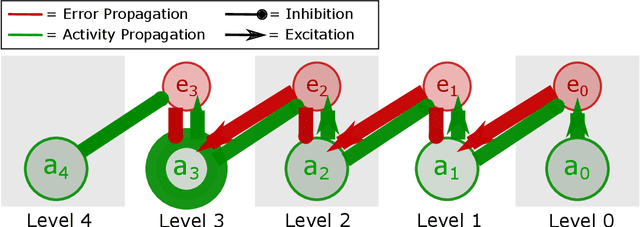

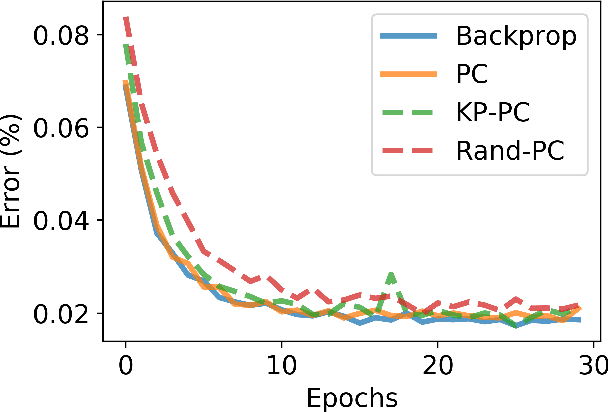
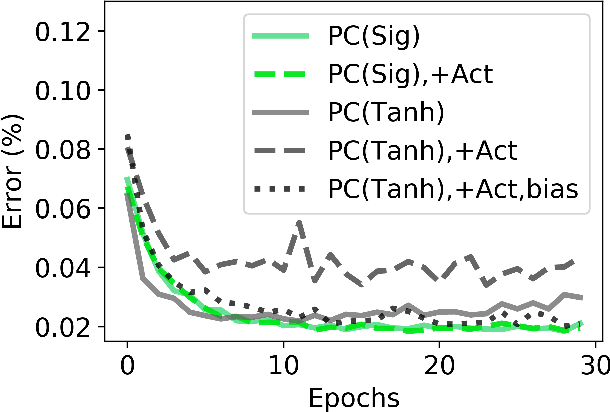
Predictive coding (PC) is a general theory of cortical function. The local, gradient-based learning rules found in one kind of PC model have recently been shown to closely approximate backpropagation. This finding suggests that this gradient-based PC model may be useful for understanding how the brain solves the credit assignment problem. The model may also be useful for developing local learning algorithms that are compatible with neuromorphic hardware. In this paper, we modify this PC model so that it better fits biological constraints, including the constraints that neurons can only have positive firing rates and the constraint that synapses only flow in one direction. We also compute the gradient-based weight and activity updates given the modified activity values. We show that, under certain conditions, these modified PC networks perform as well or nearly as well on MNIST data as the unmodified PC model and networks trained with backpropagation.
Hessian Aware Quantization of Spiking Neural Networks
Apr 29, 2021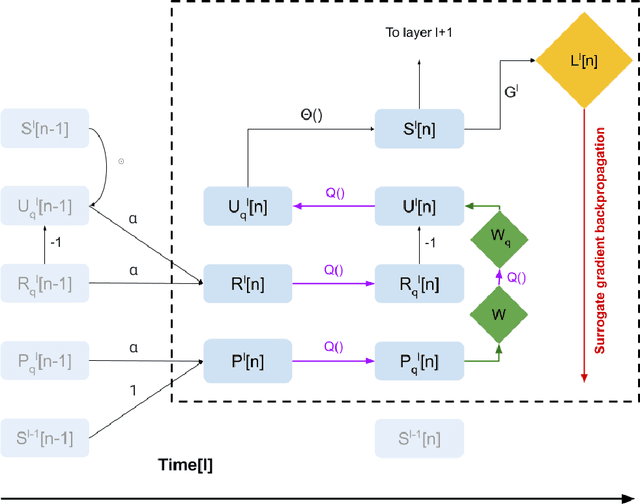
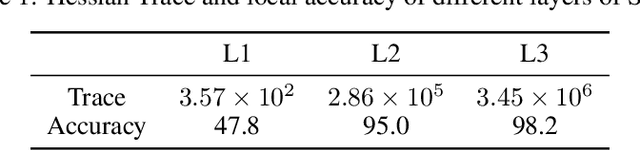
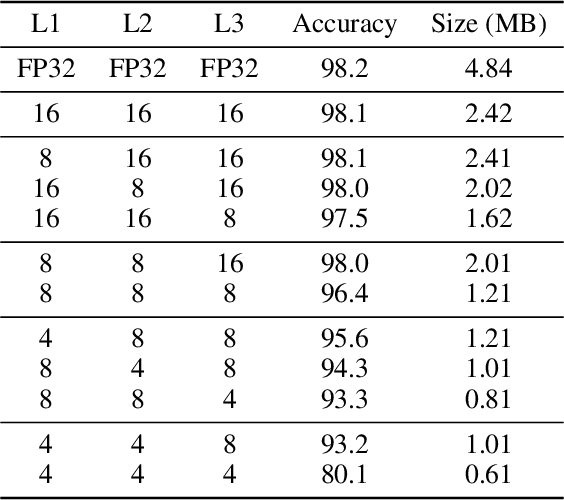
To achieve the low latency, high throughput, and energy efficiency benefits of Spiking Neural Networks (SNNs), reducing the memory and compute requirements when running on a neuromorphic hardware is an important step. Neuromorphic architecture allows massively parallel computation with variable and local bit-precisions. However, how different bit-precisions should be allocated to different layers or connections of the network is not trivial. In this work, we demonstrate how a layer-wise Hessian trace analysis can measure the sensitivity of the loss to any perturbation of the layer's weights, and this can be used to guide the allocation of a layer-specific bit-precision when quantizing an SNN. In addition, current gradient based methods of SNN training use a complex neuron model with multiple state variables, which is not ideal for compute and memory efficiency. To address this challenge, we present a simplified neuron model that reduces the number of state variables by 4-fold while still being compatible with gradient based training. We find that the impact on model accuracy when using a layer-wise bit-precision correlated well with that layer's Hessian trace. The accuracy of the optimal quantized network only dropped by 0.2%, yet the network size was reduced by 58%. This reduces memory usage and allows fixed-point arithmetic with simpler digital circuits to be used, increasing the overall throughput and energy efficiency.