 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen can transformers reason with abstract symbols?
Oct 15, 2023



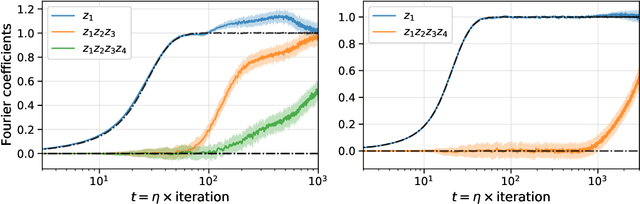
We investigate the capabilities of transformer large language models (LLMs) on relational reasoning tasks involving abstract symbols. Such tasks have long been studied in the neuroscience literature as fundamental building blocks for more complex abilities in programming, mathematics, and verbal reasoning. For (i) regression tasks, we prove that transformers generalize when trained, but require astonishingly large quantities of training data. For (ii) next-token-prediction tasks with symbolic labels, we show an "inverse scaling law": transformers fail to generalize as their embedding dimension increases. For both settings (i) and (ii), we propose subtle transformer modifications which can reduce the amount of data needed by adding two trainable parameters per head.
Provable Advantage of Curriculum Learning on Parity Targets with Mixed Inputs
Jun 29, 2023



Experimental results have shown that curriculum learning, i.e., presenting simpler examples before more complex ones, can improve the efficiency of learning. Some recent theoretical results also showed that changing the sampling distribution can help neural networks learn parities, with formal results only for large learning rates and one-step arguments. Here we show a separation result in the number of training steps with standard (bounded) learning rates on a common sample distribution: if the data distribution is a mixture of sparse and dense inputs, there exists a regime in which a 2-layer ReLU neural network trained by a curriculum noisy-GD (or SGD) algorithm that uses sparse examples first, can learn parities of sufficiently large degree, while any fully connected neural network of possibly larger width or depth trained by noisy-GD on the unordered samples cannot learn without additional steps. We also provide experimental results supporting the qualitative separation beyond the specific regime of the theoretical results.
Transformers learn through gradual rank increase
Jun 12, 2023



We identify incremental learning dynamics in transformers, where the difference between trained and initial weights progressively increases in rank. We rigorously prove this occurs under the simplifying assumptions of diagonal weight matrices and small initialization. Our experiments support the theory and also show that phenomenon can occur in practice without the simplifying assumptions.
SGD learning on neural networks: leap complexity and saddle-to-saddle dynamics
Feb 21, 2023



We investigate the time complexity of SGD learning on fully-connected neural networks with isotropic data. We put forward a complexity measure -- the leap -- which measures how "hierarchical" target functions are. For $d$-dimensional uniform Boolean or isotropic Gaussian data, our main conjecture states that the time complexity to learn a function $f$ with low-dimensional support is $\tilde\Theta (d^{\max(\mathrm{Leap}(f),2)})$. We prove a version of this conjecture for a class of functions on Gaussian isotropic data and 2-layer neural networks, under additional technical assumptions on how SGD is run. We show that the training sequentially learns the function support with a saddle-to-saddle dynamic. Our result departs from [Abbe et al. 2022] by going beyond leap 1 (merged-staircase functions), and by going beyond the mean-field and gradient flow approximations that prohibit the full complexity control obtained here. Finally, we note that this gives an SGD complexity for the full training trajectory that matches that of Correlational Statistical Query (CSQ) lower-bounds.
Generalization on the Unseen, Logic Reasoning and Degree Curriculum
Jan 30, 2023



This paper considers the learning of logical (Boolean) functions with focus on the generalization on the unseen (GOTU) setting, a strong case of out-of-distribution generalization. This is motivated by the fact that the rich combinatorial nature of data in certain reasoning tasks (e.g., arithmetic/logic) makes representative data sampling challenging, and learning successfully under GOTU gives a first vignette of an 'extrapolating' or 'reasoning' learner. We then study how different network architectures trained by (S)GD perform under GOTU and provide both theoretical and experimental evidence that for a class of network models including instances of Transformers, random features models, and diagonal linear networks, a min-degree-interpolator (MDI) is learned on the unseen. We also provide evidence that other instances with larger learning rates or mean-field networks reach leaky MDIs. These findings lead to two implications: (1) we provide an explanation to the length generalization problem (e.g., Anil et al. 2022); (2) we introduce a curriculum learning algorithm called Degree-Curriculum that learns monomials more efficiently by incrementing supports.
On the non-universality of deep learning: quantifying the cost of symmetry
Aug 05, 2022


We prove computational limitations for learning with neural networks trained by noisy gradient descent (GD). Our result applies whenever GD training is equivariant (true for many standard architectures), and quantifies the alignment needed between architectures and data in order for GD to learn. As applications, (i) we characterize the functions that fully-connected networks can weak-learn on the binary hypercube and unit sphere, demonstrating that depth-2 is as powerful as any other depth for this task; (ii) we extend the merged-staircase necessity result for learning with latent low-dimensional structure [ABM22] to beyond the mean-field regime. Our techniques extend to stochastic gradient descent (SGD), for which we show nontrivial hardness results for learning with fully-connected networks, based on cryptographic assumptions.
Learning to Reason with Neural Networks: Generalization, Unseen Data and Boolean Measures
May 26, 2022
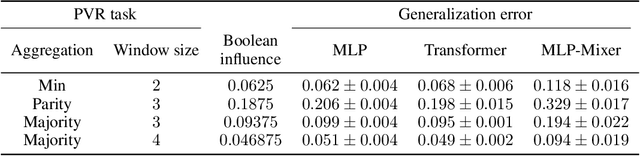
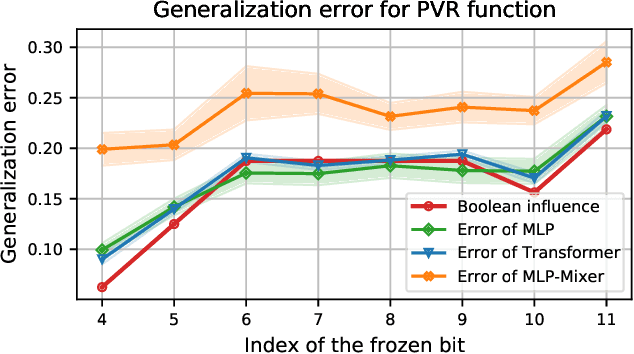
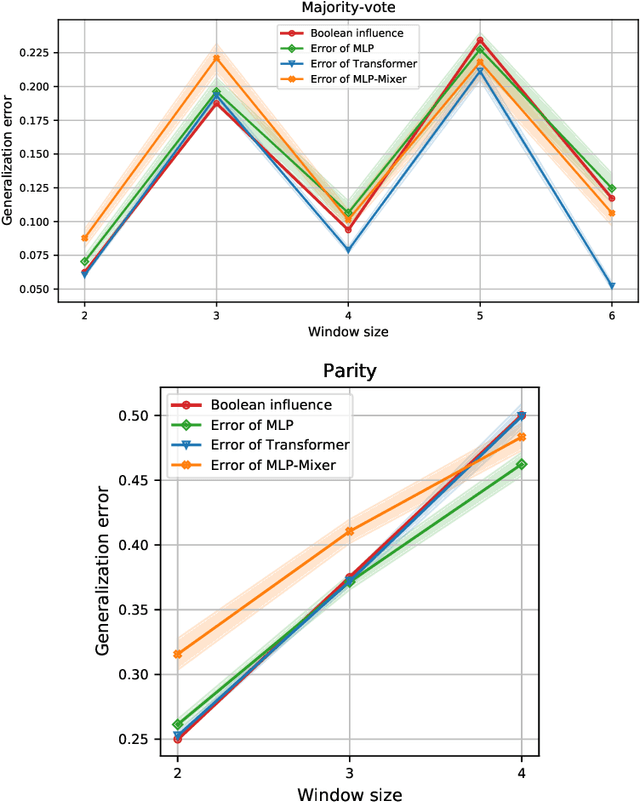
This paper considers the Pointer Value Retrieval (PVR) benchmark introduced in [ZRKB21], where a 'reasoning' function acts on a string of digits to produce the label. More generally, the paper considers the learning of logical functions with gradient descent (GD) on neural networks. It is first shown that in order to learn logical functions with gradient descent on symmetric neural networks, the generalization error can be lower-bounded in terms of the noise-stability of the target function, supporting a conjecture made in [ZRKB21]. It is then shown that in the distribution shift setting, when the data withholding corresponds to freezing a single feature (referred to as canonical holdout), the generalization error of gradient descent admits a tight characterization in terms of the Boolean influence for several relevant architectures. This is shown on linear models and supported experimentally on other models such as MLPs and Transformers. In particular, this puts forward the hypothesis that for such architectures and for learning logical functions such as PVR functions, GD tends to have an implicit bias towards low-degree representations, which in turn gives the Boolean influence for the generalization error under quadratic loss.
An initial alignment between neural network and target is needed for gradient descent to learn
Feb 25, 2022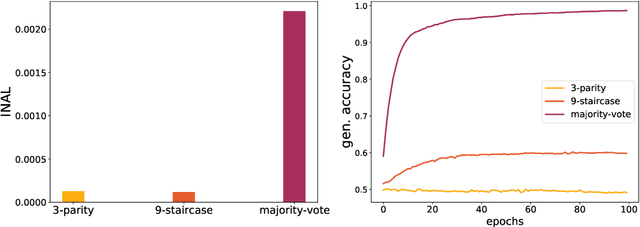
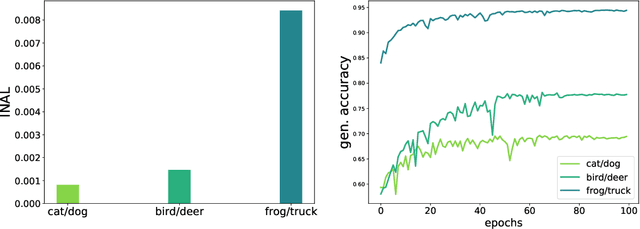
This paper introduces the notion of "Initial Alignment" (INAL) between a neural network at initialization and a target function. It is proved that if a network and target function do not have a noticeable INAL, then noisy gradient descent on a fully connected network with normalized i.i.d. initialization will not learn in polynomial time. Thus a certain amount of knowledge about the target (measured by the INAL) is needed in the architecture design. This also provides an answer to an open problem posed in [AS20]. The results are based on deriving lower-bounds for descent algorithms on symmetric neural networks without explicit knowledge of the target function beyond its INAL.
The merged-staircase property: a necessary and nearly sufficient condition for SGD learning of sparse functions on two-layer neural networks
Feb 17, 2022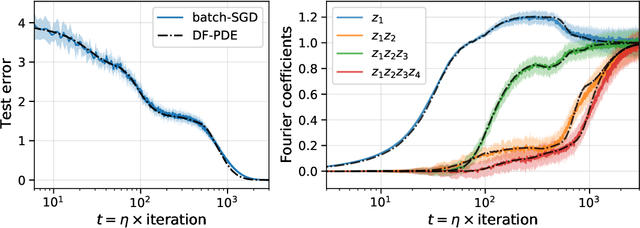
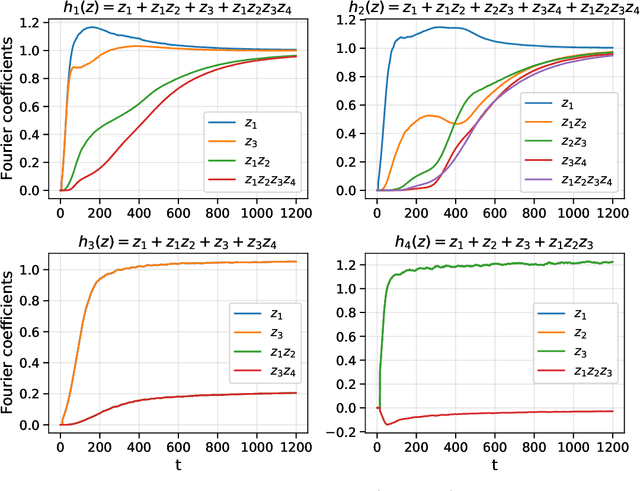
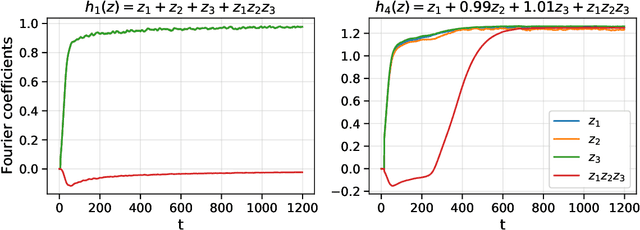
It is currently known how to characterize functions that neural networks can learn with SGD for two extremal parameterizations: neural networks in the linear regime, and neural networks with no structural constraints. However, for the main parametrization of interest (non-linear but regular networks) no tight characterization has yet been achieved, despite significant developments. We take a step in this direction by considering depth-2 neural networks trained by SGD in the mean-field regime. We consider functions on binary inputs that depend on a latent low-dimensional subspace (i.e., small number of coordinates). This regime is of interest since it is poorly understood how neural networks routinely tackle high-dimensional datasets and adapt to latent low-dimensional structure without suffering from the curse of dimensionality. Accordingly, we study SGD-learnability with $O(d)$ sample complexity in a large ambient dimension $d$. Our main results characterize a hierarchical property, the "merged-staircase property", that is both necessary and nearly sufficient for learning in this setting. We further show that non-linear training is necessary: for this class of functions, linear methods on any feature map (e.g., the NTK) are not capable of learning efficiently. The key tools are a new "dimension-free" dynamics approximation result that applies to functions defined on a latent space of low-dimension, a proof of global convergence based on polynomial identity testing, and an improvement of lower bounds against linear methods for non-almost orthogonal functions.
Binary perceptron: efficient algorithms can find solutions in a rare well-connected cluster
Nov 04, 2021

It was recently shown that almost all solutions in the symmetric binary perceptron are isolated, even at low constraint densities, suggesting that finding typical solutions is hard. In contrast, some algorithms have been shown empirically to succeed in finding solutions at low density. This phenomenon has been justified numerically by the existence of subdominant and dense connected regions of solutions, which are accessible by simple learning algorithms. In this paper, we establish formally such a phenomenon for both the symmetric and asymmetric binary perceptrons. We show that at low constraint density (equivalently for overparametrized perceptrons), there exists indeed a subdominant connected cluster of solutions with almost maximal diameter, and that an efficient multiscale majority algorithm can find solutions in such a cluster with high probability, settling in particular an open problem posed by Perkins-Xu '21. In addition, even close to the critical threshold, we show that there exist clusters of linear diameter for the symmetric perceptron, as well as for the asymmetric perceptron under additional assumptions.