 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetection of local geometry in random graphs: information-theoretic and computational limits
Mar 25, 2026We study the problem of detecting local geometry in random graphs. We introduce a model $\mathcal{G}(n, p, d, k)$, where a hidden community of average size $k$ has edges drawn as a random geometric graph on $\mathbb{S}^{d-1}$, while all remaining edges follow the Erdős--Rényi model $\mathcal{G}(n, p)$. The random geometric graph is generated by thresholding inner products of latent vectors on $\mathbb{S}^{d-1}$, with each edge having marginal probability equal to $p$. This implies that $\mathcal{G}(n, p, d, k)$ and $\mathcal{G}(n, p)$ are indistinguishable at the level of the marginals, and the signal lies entirely in the edge dependencies induced by the local geometry. We investigate both the information-theoretic and computational limits of detection. On the information-theoretic side, our upper bounds follow from three tests based on signed triangle counts: a global test, a scan test, and a constrained scan test; our lower bounds follow from two complementary methods: truncated second moment via Wishart--GOE comparison, and tensorization of KL divergence. These results together settle the detection threshold at $d = \widetildeΘ(k^2 \vee k^6/n^3)$ for fixed $p$, and extend the state-of-the-art bounds from the full model (i.e., $k = n$) for vanishing $p$. On the computational side, we identify a computational--statistical gap and provide evidence via the low-degree polynomial framework, as well as the suboptimality of signed cycle counts of length $\ell \geq 4$.
Synthetic continued pretraining
Sep 11, 2024



Pretraining on large-scale, unstructured internet text has enabled language models to acquire a significant amount of world knowledge. However, this knowledge acquisition is data-inefficient -- to learn a given fact, models must be trained on hundreds to thousands of diverse representations of it. This poses a challenge when adapting a pretrained model to a small corpus of domain-specific documents, where each fact may appear rarely or only once. We propose to bridge this gap with synthetic continued pretraining: using the small domain-specific corpus to synthesize a large corpus more amenable to learning, and then performing continued pretraining on the synthesized corpus. We instantiate this proposal with EntiGraph, a synthetic data augmentation algorithm that extracts salient entities from the source documents and then generates diverse text by drawing connections between the sampled entities. Synthetic continued pretraining using EntiGraph enables a language model to answer questions and follow generic instructions related to the source documents without access to them. If instead, the source documents are available at inference time, we show that the knowledge acquired through our approach compounds with retrieval-augmented generation. To better understand these results, we build a simple mathematical model of EntiGraph, and show how synthetic data augmentation can "rearrange" knowledge to enable more data-efficient learning.
Spectral clustering in the Gaussian mixture block model
Apr 29, 2023
Gaussian mixture block models are distributions over graphs that strive to model modern networks: to generate a graph from such a model, we associate each vertex $i$ with a latent feature vector $u_i \in \mathbb{R}^d$ sampled from a mixture of Gaussians, and we add edge $(i,j)$ if and only if the feature vectors are sufficiently similar, in that $\langle u_i,u_j \rangle \ge \tau$ for a pre-specified threshold $\tau$. The different components of the Gaussian mixture represent the fact that there may be different types of nodes with different distributions over features -- for example, in a social network each component represents the different attributes of a distinct community. Natural algorithmic tasks associated with these networks are embedding (recovering the latent feature vectors) and clustering (grouping nodes by their mixture component). In this paper we initiate the study of clustering and embedding graphs sampled from high-dimensional Gaussian mixture block models, where the dimension of the latent feature vectors $d\to \infty$ as the size of the network $n \to \infty$. This high-dimensional setting is most appropriate in the context of modern networks, in which we think of the latent feature space as being high-dimensional. We analyze the performance of canonical spectral clustering and embedding algorithms for such graphs in the case of 2-component spherical Gaussian mixtures, and begin to sketch out the information-computation landscape for clustering and embedding in these models.
Binary perceptron: efficient algorithms can find solutions in a rare well-connected cluster
Nov 04, 2021

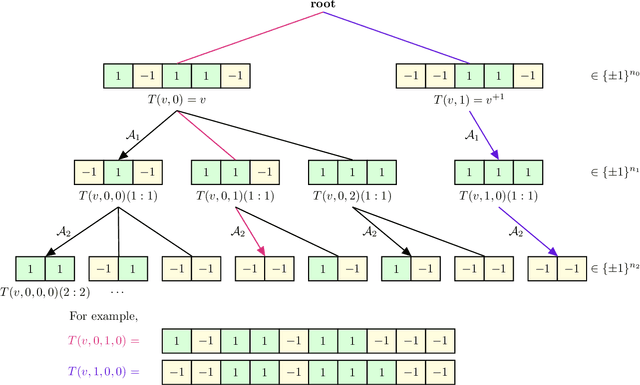
It was recently shown that almost all solutions in the symmetric binary perceptron are isolated, even at low constraint densities, suggesting that finding typical solutions is hard. In contrast, some algorithms have been shown empirically to succeed in finding solutions at low density. This phenomenon has been justified numerically by the existence of subdominant and dense connected regions of solutions, which are accessible by simple learning algorithms. In this paper, we establish formally such a phenomenon for both the symmetric and asymmetric binary perceptrons. We show that at low constraint density (equivalently for overparametrized perceptrons), there exists indeed a subdominant connected cluster of solutions with almost maximal diameter, and that an efficient multiscale majority algorithm can find solutions in such a cluster with high probability, settling in particular an open problem posed by Perkins-Xu '21. In addition, even close to the critical threshold, we show that there exist clusters of linear diameter for the symmetric perceptron, as well as for the asymmetric perceptron under additional assumptions.
Proof of the Contiguity Conjecture and Lognormal Limit for the Symmetric Perceptron
Feb 25, 2021We consider the symmetric binary perceptron model, a simple model of neural networks that has gathered significant attention in the statistical physics, information theory and probability theory communities, with recent connections made to the performance of learning algorithms in Baldassi et al. '15. We establish that the partition function of this model, normalized by its expected value, converges to a lognormal distribution. As a consequence, this allows us to establish several conjectures for this model: (i) it proves the contiguity conjecture of Aubin et al. '19 between the planted and unplanted models in the satisfiable regime; (ii) it establishes the sharp threshold conjecture; (iii) it proves the frozen 1-RSB conjecture in the symmetric case, conjectured first by Krauth-M\'ezard '89 in the asymmetric case. In a recent concurrent work of Perkins-Xu [PX21], the last two conjectures were also established by proving that the partition function concentrates on an exponential scale. This left open the contiguity conjecture and the lognormal limit characterization, which are established here. In particular, our proof technique relies on a dense counter-part of the small graph conditioning method, which was developed for sparse models in the celebrated work of Robinson and Wormald.
Learning Sparse Graphons and the Generalized Kesten-Stigum Threshold
Jun 13, 2020The problem of learning graphons has attracted considerable attention across several scientific communities, with significant progress over the recent years in sparser regimes. Yet, the current techniques still require diverging degrees in order to succeed with efficient algorithms in the challenging cases where the local structure of the graph is homogeneous. This paper provides an efficient algorithm to learn graphons in the constant expected degree regime. The algorithm is shown to succeed in estimating the rank-$k$ projection of a graphon in the $L_2$ metric if the top $k$ eigenvalues of the graphon satisfy a generalized Kesten-Stigum condition.