 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Cards: Towards an Applied Framework for Machine-Readable AI and Risk Documentation Inspired by the EU AI Act
Jun 26, 2024



With the upcoming enforcement of the EU AI Act, documentation of high-risk AI systems and their risk management information will become a legal requirement playing a pivotal role in demonstration of compliance. Despite its importance, there is a lack of standards and guidelines to assist with drawing up AI and risk documentation aligned with the AI Act. This paper aims to address this gap by providing an in-depth analysis of the AI Act's provisions regarding technical documentation, wherein we particularly focus on AI risk management. On the basis of this analysis, we propose AI Cards as a novel holistic framework for representing a given intended use of an AI system by encompassing information regarding technical specifications, context of use, and risk management, both in human- and machine-readable formats. While the human-readable representation of AI Cards provides AI stakeholders with a transparent and comprehensible overview of the AI use case, its machine-readable specification leverages on state of the art Semantic Web technologies to embody the interoperability needed for exchanging documentation within the AI value chain. This brings the flexibility required for reflecting changes applied to the AI system and its context, provides the scalability needed to accommodate potential amendments to legal requirements, and enables development of automated tools to assist with legal compliance and conformity assessment tasks. To solidify the benefits, we provide an exemplar AI Card for an AI-based student proctoring system and further discuss its potential applications within and beyond the context of the AI Act.
Synocene, Beyond the Anthropocene: De-Anthropocentralising Human-Nature-AI Interaction
Dec 13, 2023



Recent publications explore AI biases in detecting objects and people in the environment. However, there is no research tackling how AI examines nature. This case study presents a pioneering exploration into the AI attitudes (ecocentric, anthropocentric and antipathetic) toward nature. Experiments with a Large Language Model (LLM) and an image captioning algorithm demonstrate the presence of anthropocentric biases in AI. Moreover, to delve deeper into these biases and Human-Nature-AI interaction, we conducted a real-life experiment in which participants underwent an immersive de-anthropocentric experience in a forest and subsequently engaged with ChatGPT to co-create narratives. By creating fictional AI chatbot characters with ecocentric attributes, emotions and views, we successfully amplified ecocentric exchanges. We encountered some difficulties, mainly that participants deviated from narrative co-creation to short dialogues and questions and answers, possibly due to the novelty of interacting with LLMs. To solve this problem, we recommend providing preliminary guidelines on interacting with LLMs and allowing participants to get familiar with the technology. We plan to repeat this experiment in various countries and forests to expand our corpus of ecocentric materials.
Behind Recommender Systems: the Geography of the ACM RecSys Community
Sep 07, 2023The amount and dissemination rate of media content accessible online is nowadays overwhelming. Recommender Systems filter this information into manageable streams or feeds, adapted to our personal needs or preferences. It is of utter importance that algorithms employed to filter information do not distort or cut out important elements from our perspectives of the world. Under this principle, it is essential to involve diverse views and teams from the earliest stages of their design and development. This has been highlighted, for instance, in recent European Union regulations such as the Digital Services Act, via the requirement of risk monitoring, including the risk of discrimination, and the AI Act, through the requirement to involve people with diverse backgrounds in the development of AI systems. We look into the geographic diversity of the recommender systems research community, specifically by analyzing the affiliation countries of the authors who contributed to the ACM Conference on Recommender Systems (RecSys) during the last 15 years. This study has been carried out in the framework of the Diversity in AI - DivinAI project, whose main objective is the long-term monitoring of diversity in AI forums through a set of indexes.
Use case cards: a use case reporting framework inspired by the European AI Act
Jun 23, 2023



Despite recent efforts by the Artificial Intelligence (AI) community to move towards standardised procedures for documenting models, methods, systems or datasets, there is currently no methodology focused on use cases aligned with the risk-based approach of the European AI Act (AI Act). In this paper, we propose a new framework for the documentation of use cases, that we call "use case cards", based on the use case modelling included in the Unified Markup Language (UML) standard. Unlike other documentation methodologies, we focus on the intended purpose and operational use of an AI system. It consists of two main parts. Firstly, a UML-based template, tailored to allow implicitly assessing the risk level of the AI system and defining relevant requirements. Secondly, a supporting UML diagram designed to provide information about the system-user interactions and relationships. The proposed framework is the result of a co-design process involving a relevant team of EU policy experts and scientists. We have validated our proposal with 11 experts with different backgrounds and a reasonable knowledge of the AI Act as a prerequisite. We provide the 5 "use case cards" used in the co-design and validation process. "Use case cards" allows framing and contextualising use cases in an effective way, and we hope this methodology can be a useful tool for policy makers and providers for documenting use cases, assessing the risk level, adapting the different requirements and building a catalogue of existing usages of AI.
Documenting use cases in the affective computing domain using Unified Modeling Language
Sep 19, 2022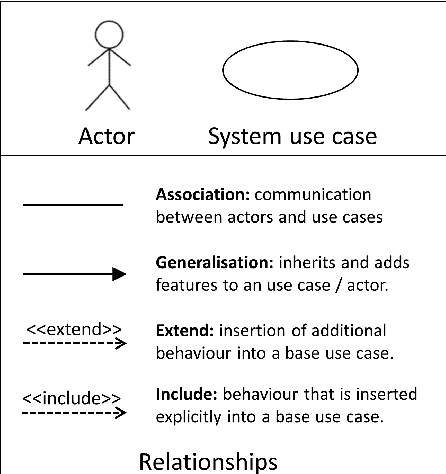
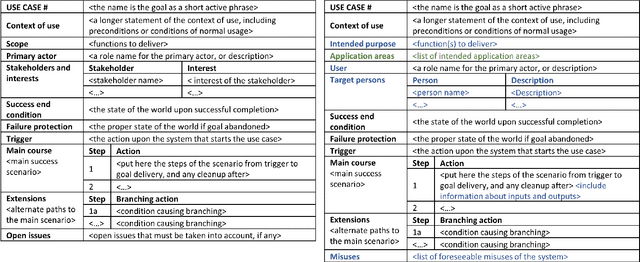
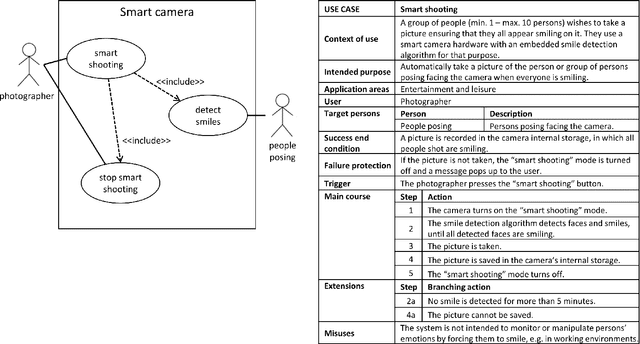
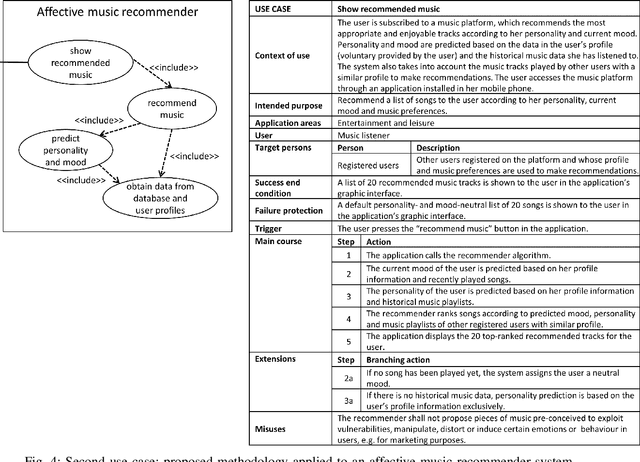
The study of the ethical impact of AI and the design of trustworthy systems needs the analysis of the scenarios where AI systems are used, which is related to the software engineering concept of "use case" and the "intended purpose" legal term. However, there is no standard methodology for use case documentation covering the context of use, scope, functional requirements and risks of an AI system. In this work, we propose a novel documentation methodology for AI use cases, with a special focus on the affective computing domain. Our approach builds upon an assessment of use case information needs documented in the research literature and the recently proposed European regulatory framework for AI. From this assessment, we adopt and adapt the Unified Modeling Language (UML), which has been used in the last two decades mostly by software engineers. Each use case is then represented by an UML diagram and a structured table, and we provide a set of examples illustrating its application to several affective computing scenarios.
Monitoring Diversity of AI Conferences: Lessons Learnt and Future Challenges in the DivinAI Project
Mar 03, 2022

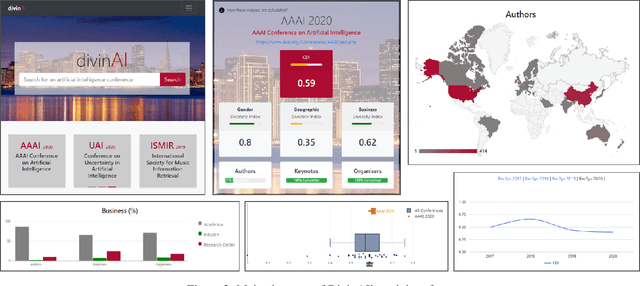
DivinAI is an open and collaborative initiative promoted by the European Commission's Joint Research Centre to measure and monitor diversity indicators related to AI conferences, with special focus on gender balance, geographical representation, and presence of academia vs companies. This paper summarizes the main achievements and lessons learnt during the first year of life of the DivinAI project, and proposes a set of recommendations for its further development and maintenance by the AI community.
Rank-based verification for long-term face tracking in crowded scenes
Jul 28, 2021
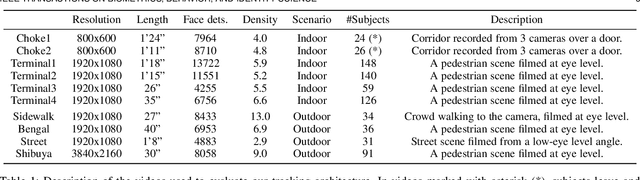
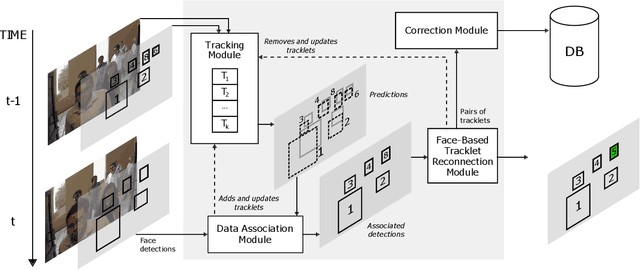
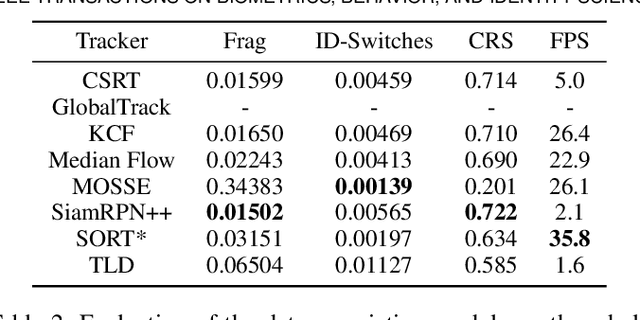
Most current multi-object trackers focus on short-term tracking, and are based on deep and complex systems that often cannot operate in real-time, making them impractical for video-surveillance. In this paper we present a long-term, multi-face tracking architecture conceived for working in crowded contexts where faces are often the only visible part of a person. Our system benefits from advances in the fields of face detection and face recognition to achieve long-term tracking, and is particularly unconstrained to the motion and occlusions of people. It follows a tracking-by-detection approach, combining a fast short-term visual tracker with a novel online tracklet reconnection strategy grounded on rank-based face verification. The proposed rank-based constraint favours higher inter-class distance among tracklets, and reduces the propagation of errors due to wrong reconnections. Additionally, a correction module is included to correct past assignments with no extra computational cost. We present a series of experiments introducing novel specialized metrics for the evaluation of long-term tracking capabilities, and publicly release a video dataset with 10 manually annotated videos and a total length of 8' 54". Our findings validate the robustness of each of the proposed modules, and demonstrate that, in these challenging contexts, our approach yields up to 50% longer tracks than state-of-the-art deep learning trackers.
* arXiv admin note: substantial text overlap with arXiv:2010.08675
Does the Goal Matter? Emotion Recognition Tasks Can Change the Social Value of Facial Mimicry towards Artificial Agents
May 05, 2021

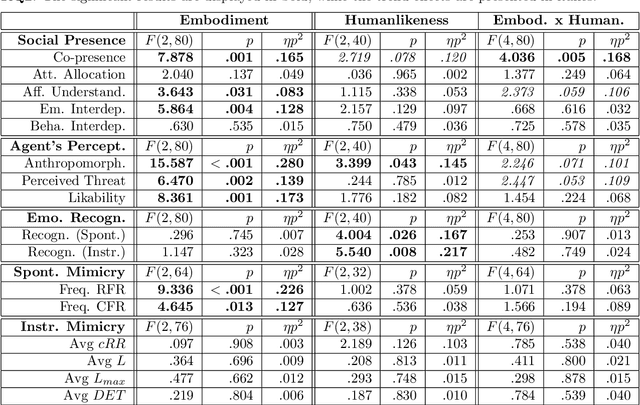

In this paper, we present a study aimed at understanding whether the embodiment and humanlikeness of an artificial agent can affect people's spontaneous and instructed mimicry of its facial expressions. The study followed a mixed experimental design and revolved around an emotion recognition task. Participants were randomly assigned to one level of humanlikeness (between-subject variable: humanlike, characterlike, or morph facial texture of the artificial agents) and observed the facial expressions displayed by a human (control) and three artificial agents differing in embodiment (within-subject variable: video-recorded robot, physical robot, and virtual agent). To study both spontaneous and instructed facial mimicry, we divided the experimental sessions into two phases. In the first phase, we asked participants to observe and recognize the emotions displayed by the agents. In the second phase, we asked them to look at the agents' facial expressions, replicate their dynamics as closely as possible, and then identify the observed emotions. In both cases, we assessed participants' facial expressions with an automated Action Unit (AU) intensity detector. Contrary to our hypotheses, our results disclose that the agent that was perceived as the least uncanny, and most anthropomorphic, likable, and co-present, was the one spontaneously mimicked the least. Moreover, they show that instructed facial mimicry negatively predicts spontaneous facial mimicry. Further exploratory analyses revealed that spontaneous facial mimicry appeared when participants were less certain of the emotion they recognized. Hence, we postulate that an emotion recognition goal can flip the social value of facial mimicry as it transforms a likable artificial agent into a distractor.
Hierarchical Residual Attention Network for Single Image Super-Resolution
Dec 08, 2020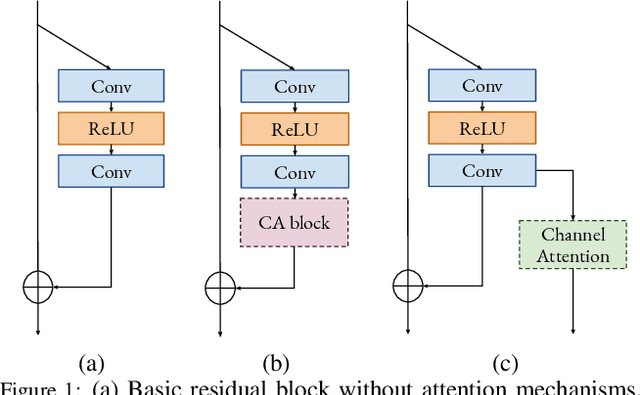
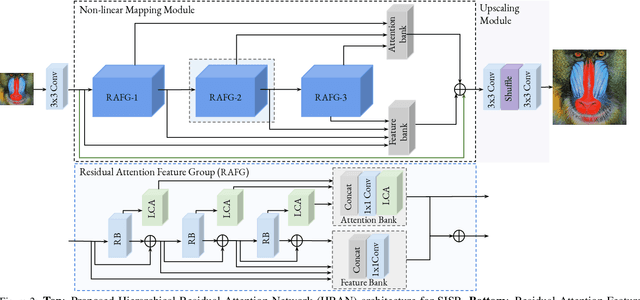
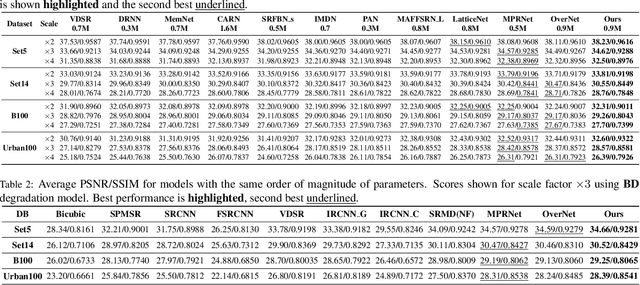
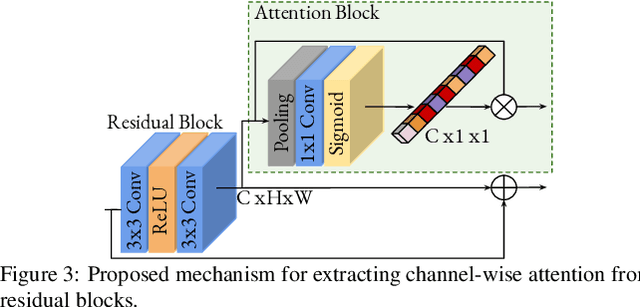
Convolutional neural networks are the most successful models in single image super-resolution. Deeper networks, residual connections, and attention mechanisms have further improved their performance. However, these strategies often improve the reconstruction performance at the expense of considerably increasing the computational cost. This paper introduces a new lightweight super-resolution model based on an efficient method for residual feature and attention aggregation. In order to make an efficient use of the residual features, these are hierarchically aggregated into feature banks for posterior usage at the network output. In parallel, a lightweight hierarchical attention mechanism extracts the most relevant features from the network into attention banks for improving the final output and preventing the information loss through the successive operations inside the network. Therefore, the processing is split into two independent paths of computation that can be simultaneously carried out, resulting in a highly efficient and effective model for reconstructing fine details on high-resolution images from their low-resolution counterparts. Our proposed architecture surpasses state-of-the-art performance in several datasets, while maintaining relatively low computation and memory footprint.
Long-Term Face Tracking for Crowded Video-Surveillance Scenarios
Oct 17, 2020

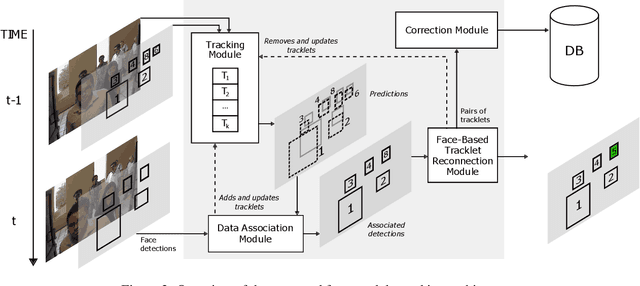
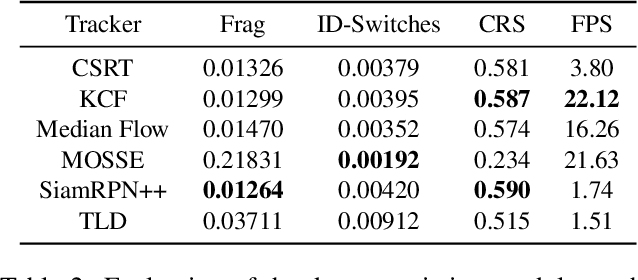
Most current multi-object trackers focus on short-term tracking, and are based on deep and complex systems that do not operate in real-time, often making them impractical for video-surveillance. In this paper, we present a long-term multi-face tracking architecture conceived for working in crowded contexts, particularly unconstrained in terms of movement and occlusions, and where the face is often the only visible part of the person. Our system benefits from advances in the fields of face detection and face recognition to achieve long-term tracking. It follows a tracking-by-detection approach, combining a fast short-term visual tracker with a novel online tracklet reconnection strategy grounded on face verification. Additionally, a correction module is included to correct past track assignments with no extra computational cost. We present a series of experiments introducing novel, specialized metrics for the evaluation of long-term tracking capabilities and a video dataset that we publicly release. Findings demonstrate that, in this context, our approach allows to obtain up to 50% longer tracks than state-of-the-art deep learning trackers.