 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring and Eliciting Needs and Preferences from Editors for Wikidata Recommendations
Dec 04, 2022



Wikidata is an open knowledge graph created, managed, and maintained collaboratively by a global community of volunteers. As it continues to grow, it faces substantial editor engagement challenges, including acquiring new editors to tackle an increasing workload and retaining existing editors. Experiences from other online communities and peer-production systems, including Wikipedia, suggest that recommending tasks to editors could help with both. Our aim with this paper is to elicit the user requirements for a Wikidata recommendations system. We conduct a mixed-methods study with a thematic analysis of in-depth interviews with 31 Wikidata editors and three Wikimedia managers, complemented by a quantitative analysis of edit records of 3,740 Wikidata editors. The insights gained from the study help us outline design requirements for the Wikidata recommender system. We conclude with a discussion of the implications of this work and directions for future work.
ProVe: A Pipeline for Automated Provenance Verification of Knowledge Graphs against Textual Sources
Oct 26, 2022



Knowledge Graphs are repositories of information that gather data from a multitude of domains and sources in the form of semantic triples, serving as a source of structured data for various crucial applications in the modern web landscape, from Wikipedia infoboxes to search engines. Such graphs mainly serve as secondary sources of information and depend on well-documented and verifiable provenance to ensure their trustworthiness and usability. However, their ability to systematically assess and assure the quality of this provenance, most crucially whether it properly supports the graph's information, relies mainly on manual processes that do not scale with size. ProVe aims at remedying this, consisting of a pipelined approach that automatically verifies whether a Knowledge Graph triple is supported by text extracted from its documented provenance. ProVe is intended to assist information curators and consists of four main steps involving rule-based methods and machine learning models: text extraction, triple verbalisation, sentence selection, and claim verification. ProVe is evaluated on a Wikidata dataset, achieving promising results overall and excellent performance on the binary classification task of detecting support from provenance, with 87.5% accuracy and 82.9% F1-macro on text-rich sources. The evaluation data and scripts used in this paper are available on GitHub and Figshare.
A Decade of Knowledge Graphs in Natural Language Processing: A Survey
Sep 30, 2022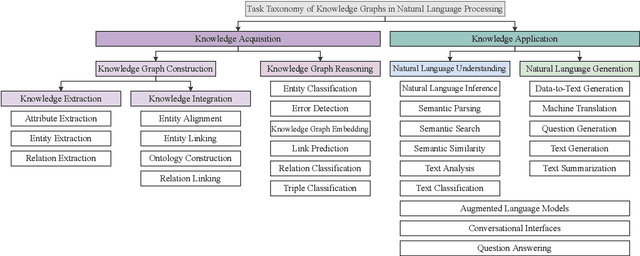
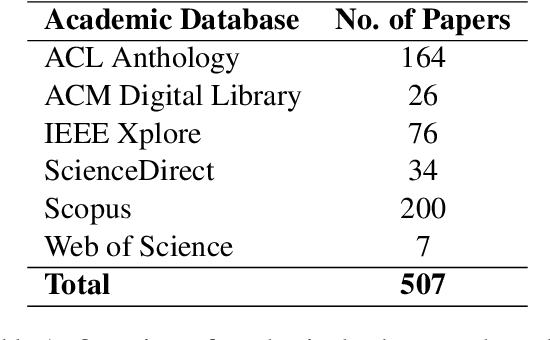
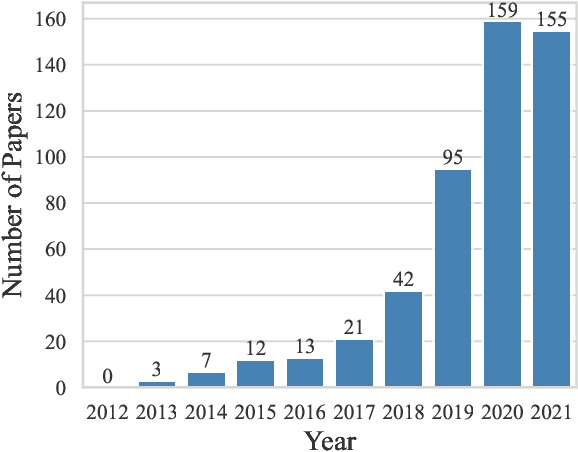
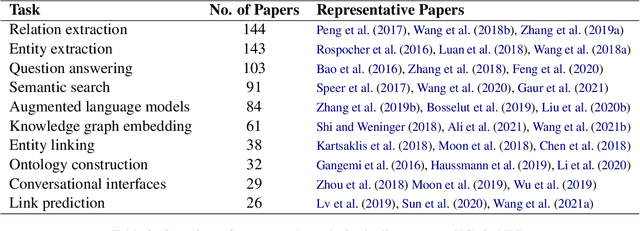
In pace with developments in the research field of artificial intelligence, knowledge graphs (KGs) have attracted a surge of interest from both academia and industry. As a representation of semantic relations between entities, KGs have proven to be particularly relevant for natural language processing (NLP), experiencing a rapid spread and wide adoption within recent years. Given the increasing amount of research work in this area, several KG-related approaches have been surveyed in the NLP research community. However, a comprehensive study that categorizes established topics and reviews the maturity of individual research streams remains absent to this day. Contributing to closing this gap, we systematically analyzed 507 papers from the literature on KGs in NLP. Our survey encompasses a multifaceted review of tasks, research types, and contributions. As a result, we present a structured overview of the research landscape, provide a taxonomy of tasks, summarize our findings, and highlight directions for future work.
Statistical and Neural Methods for Cross-lingual Entity Label Mapping in Knowledge Graphs
Jun 17, 2022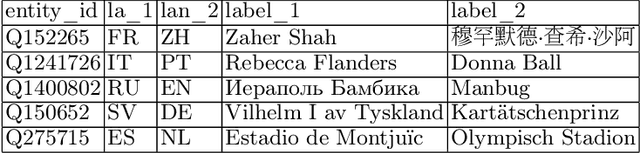
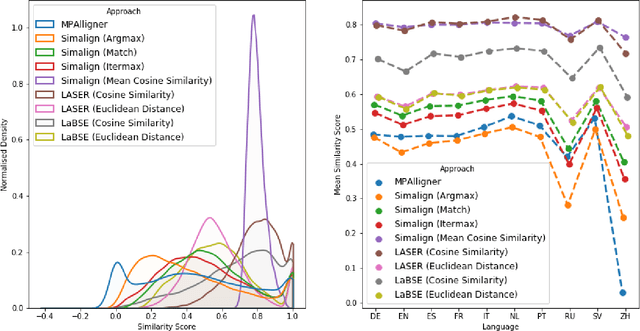
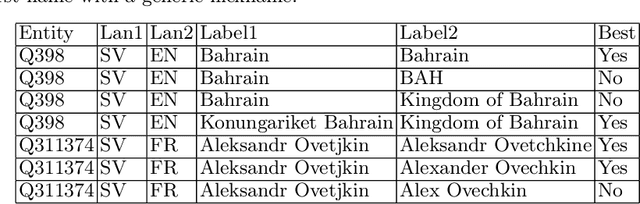
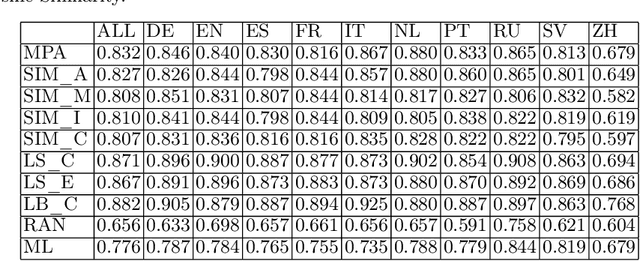
Knowledge bases such as Wikidata amass vast amounts of named entity information, such as multilingual labels, which can be extremely useful for various multilingual and cross-lingual applications. However, such labels are not guaranteed to match across languages from an information consistency standpoint, greatly compromising their usefulness for fields such as machine translation. In this work, we investigate the application of word and sentence alignment techniques coupled with a matching algorithm to align cross-lingual entity labels extracted from Wikidata in 10 languages. Our results indicate that mapping between Wikidata's main labels stands to be considerably improved (up to $20$ points in F1-score) by any of the employed methods. We show how methods relying on sentence embeddings outperform all others, even across different scripts. We believe the application of such techniques to measure the similarity of label pairs, coupled with a knowledge base rich in high-quality entity labels, to be an excellent asset to machine translation.
WDV: A Broad Data Verbalisation Dataset Built from Wikidata
May 05, 2022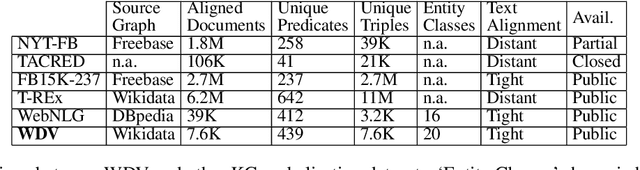
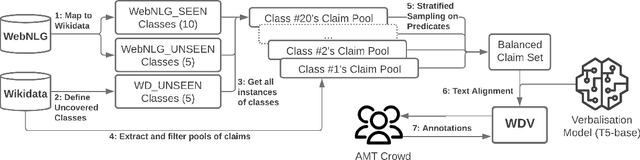
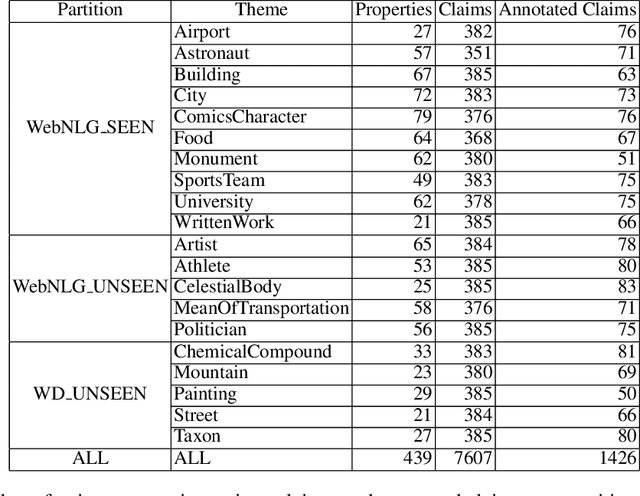
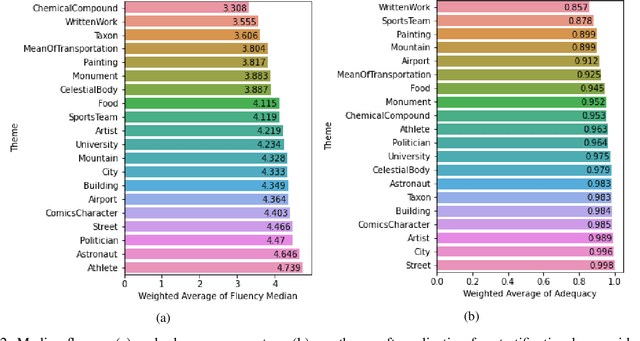
Data verbalisation is a task of great importance in the current field of natural language processing, as there is great benefit in the transformation of our abundant structured and semi-structured data into human-readable formats. Verbalising Knowledge Graph (KG) data focuses on converting interconnected triple-based claims, formed of subject, predicate, and object, into text. Although KG verbalisation datasets exist for some KGs, there are still gaps in their fitness for use in many scenarios. This is especially true for Wikidata, where available datasets either loosely couple claim sets with textual information or heavily focus on predicates around biographies, cities, and countries. To address these gaps, we propose WDV, a large KG claim verbalisation dataset built from Wikidata, with a tight coupling between triples and text, covering a wide variety of entities and predicates. We also evaluate the quality of our verbalisations through a reusable workflow for measuring human-centred fluency and adequacy scores. Our data and code are openly available in the hopes of furthering research towards KG verbalisation.
Assessing the quality of sources in Wikidata across languages: a hybrid approach
Sep 20, 2021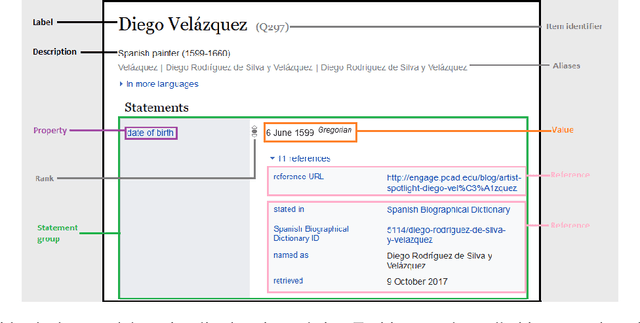
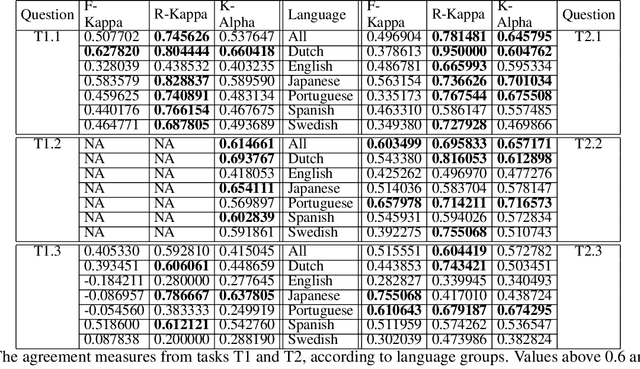
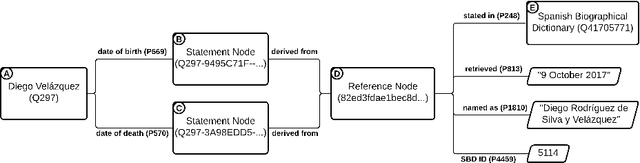
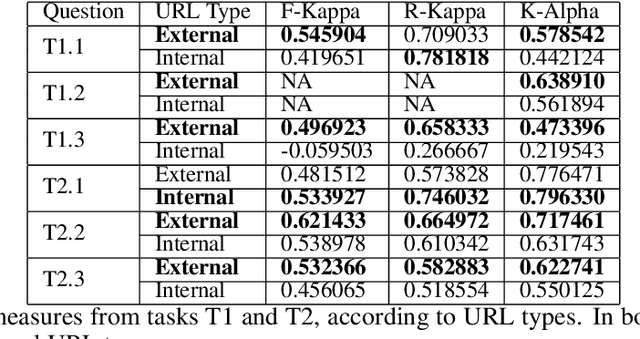
Wikidata is one of the most important sources of structured data on the web, built by a worldwide community of volunteers. As a secondary source, its contents must be backed by credible references; this is particularly important as Wikidata explicitly encourages editors to add claims for which there is no broad consensus, as long as they are corroborated by references. Nevertheless, despite this essential link between content and references, Wikidata's ability to systematically assess and assure the quality of its references remains limited. To this end, we carry out a mixed-methods study to determine the relevance, ease of access, and authoritativeness of Wikidata references, at scale and in different languages, using online crowdsourcing, descriptive statistics, and machine learning. Building on previous work of ours, we run a series of microtasks experiments to evaluate a large corpus of references, sampled from Wikidata triples with labels in several languages. We use a consolidated, curated version of the crowdsourced assessments to train several machine learning models to scale up the analysis to the whole of Wikidata. The findings help us ascertain the quality of references in Wikidata, and identify common challenges in defining and capturing the quality of user-generated multilingual structured data on the web. We also discuss ongoing editorial practices, which could encourage the use of higher-quality references in a more immediate way. All data and code used in the study are available on GitHub for feedback and further improvement and deployment by the research community.
Learning to Recommend Items to Wikidata Editors
Jul 30, 2021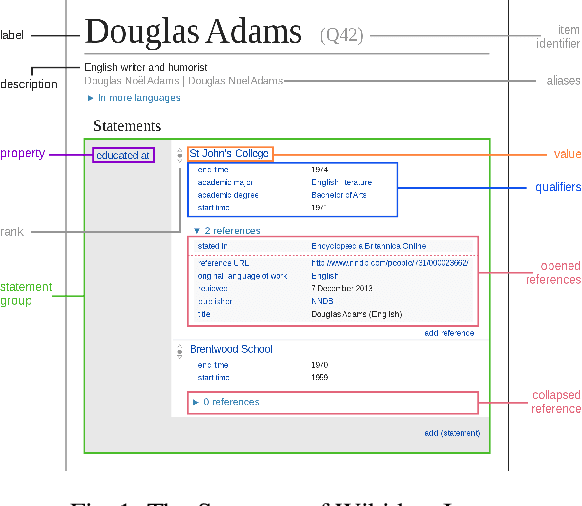
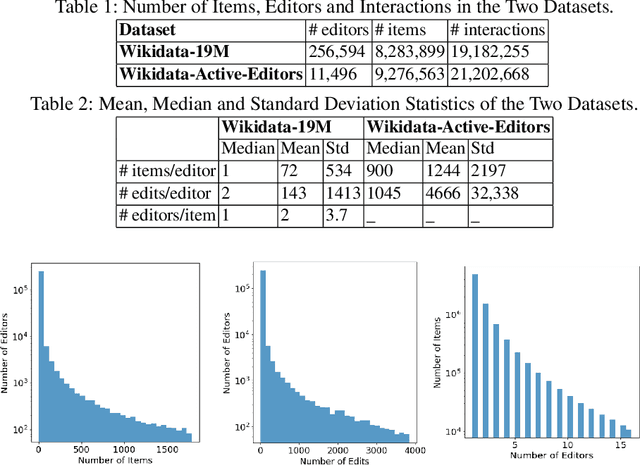
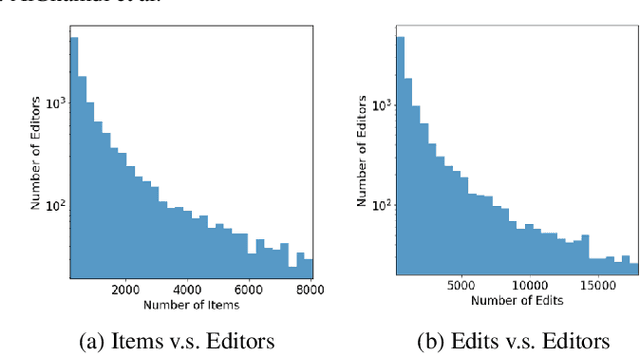
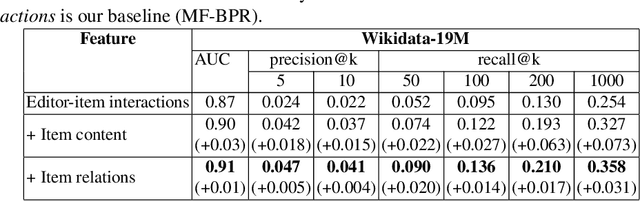
Wikidata is an open knowledge graph built by a global community of volunteers. As it advances in scale, it faces substantial challenges around editor engagement. These challenges are in terms of both attracting new editors to keep up with the sheer amount of work and retaining existing editors. Experience from other online communities and peer-production systems, including Wikipedia, suggests that personalised recommendations could help, especially newcomers, who are sometimes unsure about how to contribute best to an ongoing effort. For this reason, we propose a recommender system WikidataRec for Wikidata items. The system uses a hybrid of content-based and collaborative filtering techniques to rank items for editors relying on both item features and item-editor previous interaction. A neural network, named a neural mixture of representations, is designed to learn fine weights for the combination of item-based representations and optimize them with editor-based representation by item-editor interaction. To facilitate further research in this space, we also create two benchmark datasets, a general-purpose one with 220,000 editors responsible for 14 million interactions with 4 million items and a second one focusing on the contributions of more than 8,000 more active editors. We perform an offline evaluation of the system on both datasets with promising results. Our code and datasets are available at https://github.com/WikidataRec-developer/Wikidata_Recommender.
Learning to Generate Wikipedia Summaries for Underserved Languages from Wikidata
Apr 29, 2018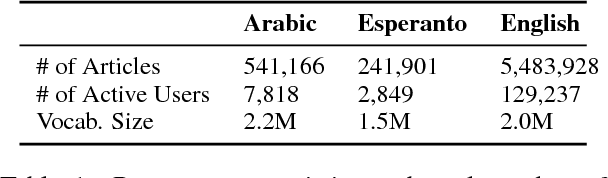
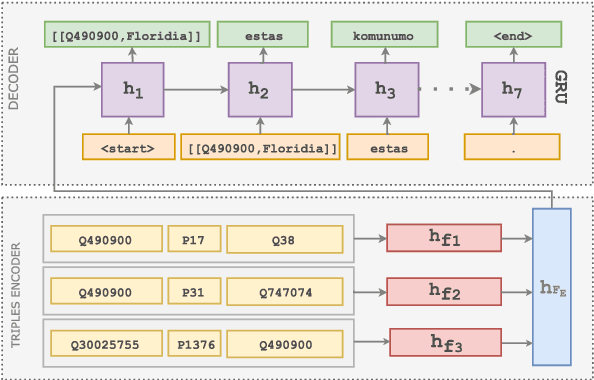

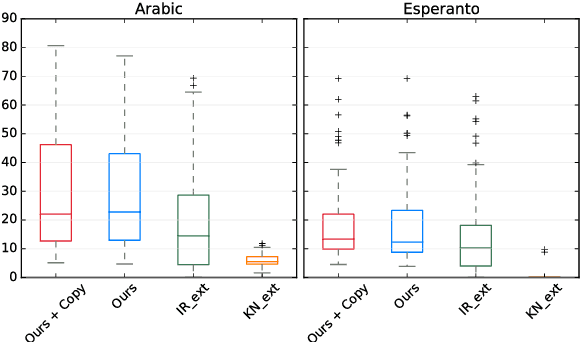
While Wikipedia exists in 287 languages, its content is unevenly distributed among them. In this work, we investigate the generation of open domain Wikipedia summaries in underserved languages using structured data from Wikidata. To this end, we propose a neural network architecture equipped with copy actions that learns to generate single-sentence and comprehensible textual summaries from Wikidata triples. We demonstrate the effectiveness of the proposed approach by evaluating it against a set of baselines on two languages of different natures: Arabic, a morphological rich language with a larger vocabulary than English, and Esperanto, a constructed language known for its easy acquisition.
Neural Wikipedian: Generating Textual Summaries from Knowledge Base Triples
Nov 01, 2017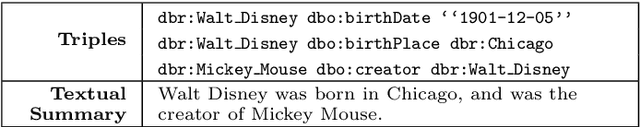
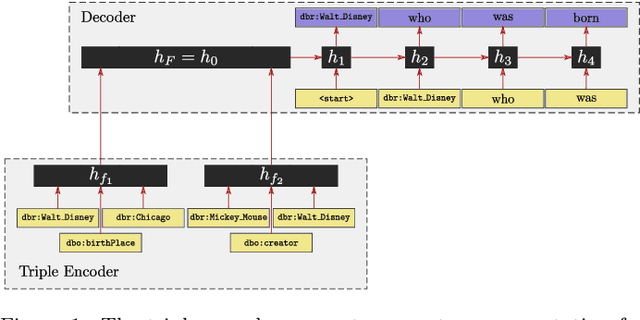
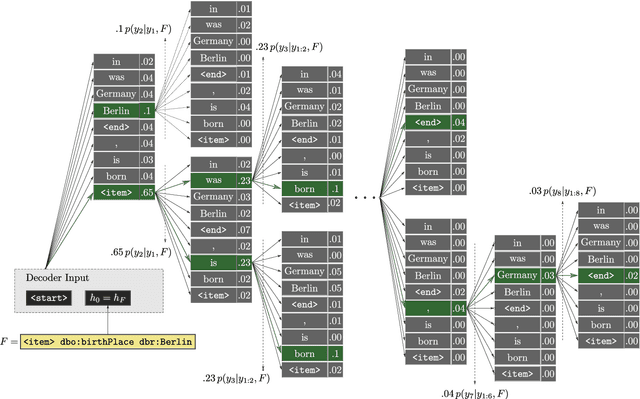

Most people do not interact with Semantic Web data directly. Unless they have the expertise to understand the underlying technology, they need textual or visual interfaces to help them make sense of it. We explore the problem of generating natural language summaries for Semantic Web data. This is non-trivial, especially in an open-domain context. To address this problem, we explore the use of neural networks. Our system encodes the information from a set of triples into a vector of fixed dimensionality and generates a textual summary by conditioning the output on the encoded vector. We train and evaluate our models on two corpora of loosely aligned Wikipedia snippets and DBpedia and Wikidata triples with promising results.
Crowdsourcing for Beyond Polarity Sentiment Analysis A Pure Emotion Lexicon
Oct 04, 2017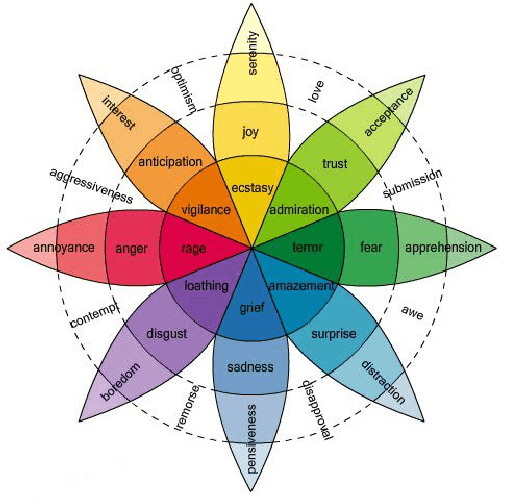
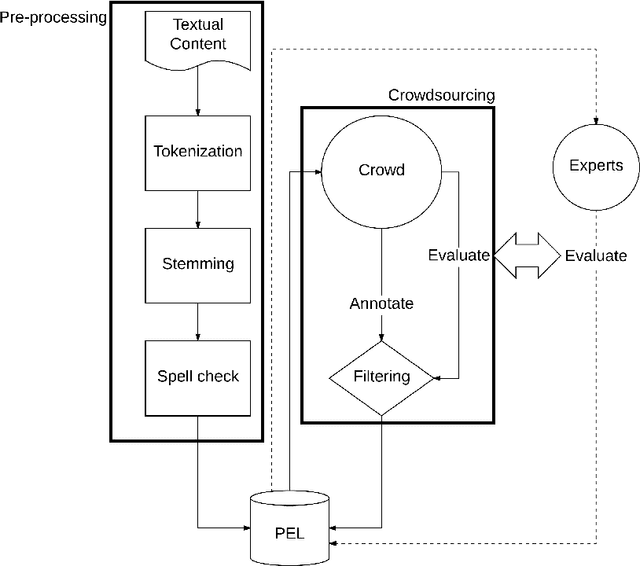
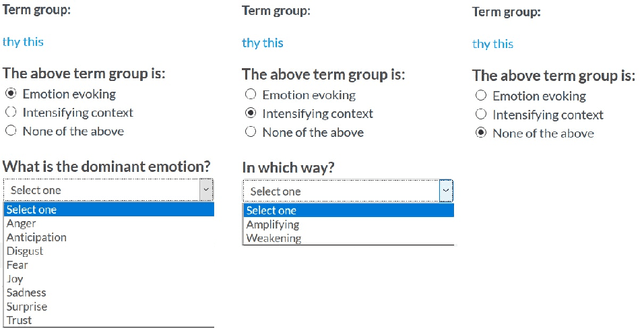

Sentiment analysis aims to uncover emotions conveyed through information. In its simplest form, it is performed on a polarity basis, where the goal is to classify information with positive or negative emotion. Recent research has explored more nuanced ways to capture emotions that go beyond polarity. For these methods to work, they require a critical resource: a lexicon that is appropriate for the task at hand, in terms of the range of emotions it captures diversity. In the past, sentiment analysis lexicons have been created by experts, such as linguists and behavioural scientists, with strict rules. Lexicon evaluation was also performed by experts or gold standards. In our paper, we propose a crowdsourcing method for lexicon acquisition, which is scalable, cost-effective, and doesn't require experts or gold standards. We also compare crowd and expert evaluations of the lexicon, to assess the overall lexicon quality, and the evaluation capabilities of the crowd.