 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Robustness Without Sacrificing Accuracy with Patch Gaussian Augmentation
Jun 06, 2019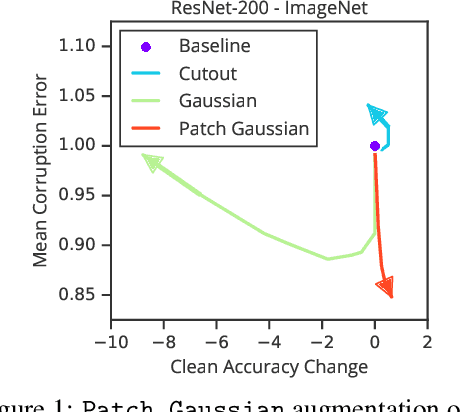
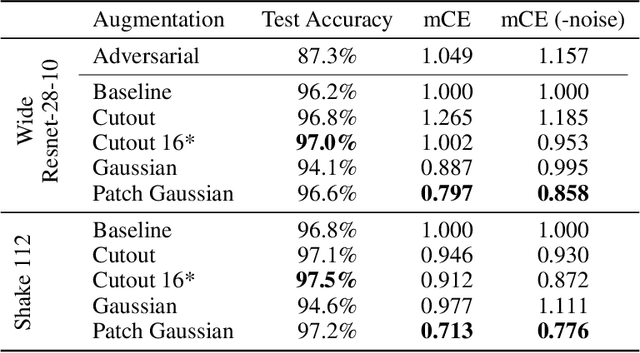
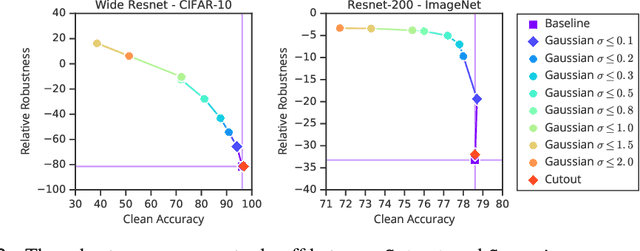
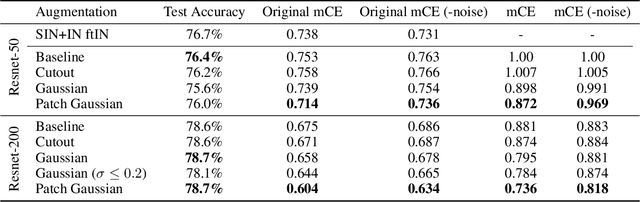
Deploying machine learning systems in the real world requires both high accuracy on clean data and robustness to naturally occurring corruptions. While architectural advances have led to improved accuracy, building robust models remains challenging. Prior work has argued that there is an inherent trade-off between robustness and accuracy, which is exemplified by standard data augment techniques such as Cutout, which improves clean accuracy but not robustness, and additive Gaussian noise, which improves robustness but hurts accuracy. To overcome this trade-off, we introduce Patch Gaussian, a simple augmentation scheme that adds noise to randomly selected patches in an input image. Models trained with Patch Gaussian achieve state of the art on the CIFAR-10 and ImageNetCommon Corruptions benchmarks while also improving accuracy on clean data. We find that this augmentation leads to reduced sensitivity to high frequency noise(similar to Gaussian) while retaining the ability to take advantage of relevant high frequency information in the image (similar to Cutout). Finally, we show that Patch Gaussian can be used in conjunction with other regularization methods and data augmentation policies such as AutoAugment, and improves performance on the COCO object detection benchmark.
SpecAugment: A Simple Data Augmentation Method for Automatic Speech Recognition
Apr 18, 2019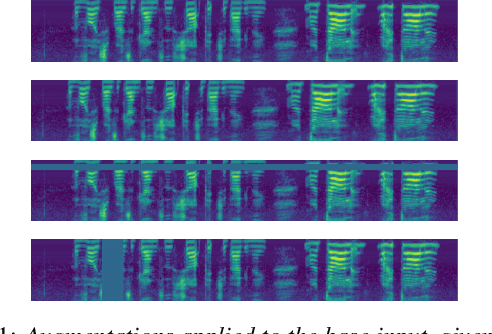
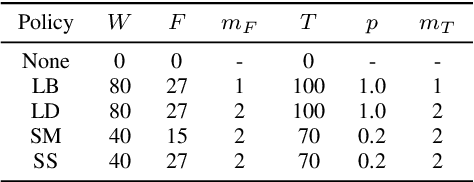
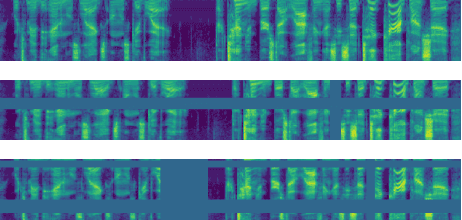
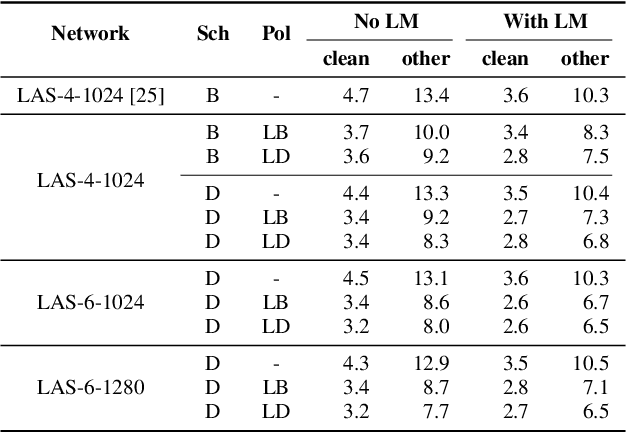
We present SpecAugment, a simple data augmentation method for speech recognition. SpecAugment is applied directly to the feature inputs of a neural network (i.e., filter bank coefficients). The augmentation policy consists of warping the features, masking blocks of frequency channels, and masking blocks of time steps. We apply SpecAugment on Listen, Attend and Spell networks for end-to-end speech recognition tasks. We achieve state-of-the-art performance on the LibriSpeech 960h and Swichboard 300h tasks, outperforming all prior work. On LibriSpeech, we achieve 6.8% WER on test-other without the use of a language model, and 5.8% WER with shallow fusion with a language model. This compares to the previous state-of-the-art hybrid system of 7.5% WER. For Switchboard, we achieve 7.2%/14.6% on the Switchboard/CallHome portion of the Hub5'00 test set without the use of a language model, and 6.8%/14.1% with shallow fusion, which compares to the previous state-of-the-art hybrid system at 8.3%/17.3% WER.
Realistic Evaluation of Deep Semi-Supervised Learning Algorithms
Oct 26, 2018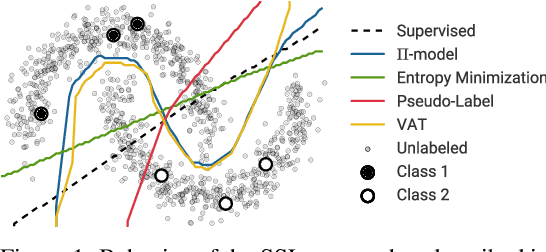

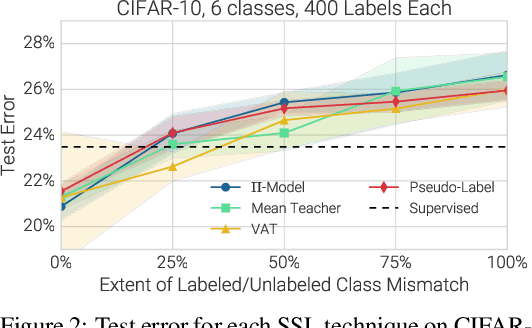

Semi-supervised learning (SSL) provides a powerful framework for leveraging unlabeled data when labels are limited or expensive to obtain. SSL algorithms based on deep neural networks have recently proven successful on standard benchmark tasks. However, we argue that these benchmarks fail to address many issues that these algorithms would face in real-world applications. After creating a unified reimplementation of various widely-used SSL techniques, we test them in a suite of experiments designed to address these issues. We find that the performance of simple baselines which do not use unlabeled data is often underreported, that SSL methods differ in sensitivity to the amount of labeled and unlabeled data, and that performance can degrade substantially when the unlabeled dataset contains out-of-class examples. To help guide SSL research towards real-world applicability, we make our unified reimplemention and evaluation platform publicly available.
AutoAugment: Learning Augmentation Policies from Data
Oct 09, 2018
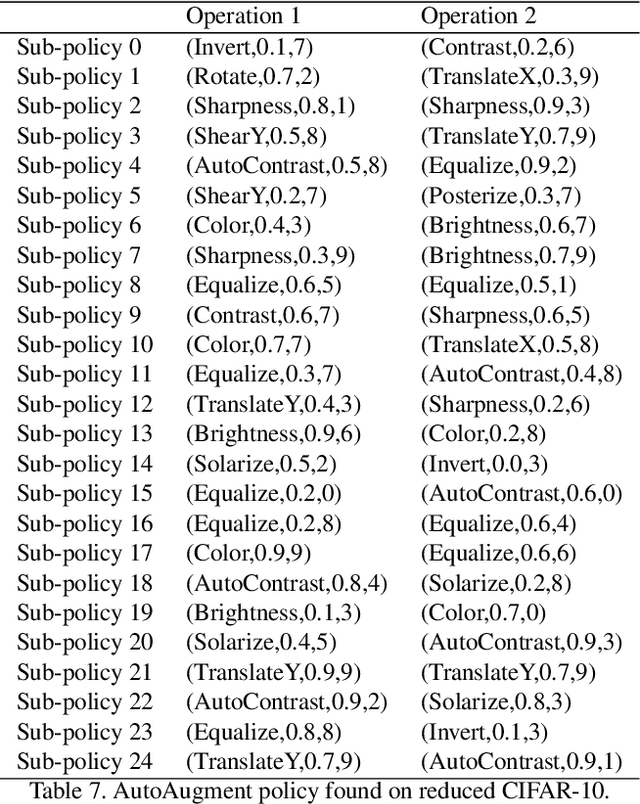


In this paper, we take a closer look at data augmentation for images, and describe a simple procedure called AutoAugment to search for improved data augmentation policies. Our key insight is to create a search space of data augmentation policies, evaluating the quality of a particular policy directly on the dataset of interest. In our implementation, we have designed a search space where a policy consists of many sub-policies, one of which is randomly chosen for each image in each mini-batch. A sub-policy consists of two operations, each operation being an image processing function such as translation, rotation, or shearing, and the probabilities and magnitudes with which the functions are applied. We use a search algorithm to find the best policy such that the neural network yields the highest validation accuracy on a target dataset. Our method achieves state-of-the-art accuracy on CIFAR-10, CIFAR-100, SVHN, and ImageNet (without additional data). On ImageNet, we attain a Top-1 accuracy of 83.54%. On CIFAR-10, we achieve an error rate of 1.48%, which is 0.65% better than the previous state-of-the-art. Finally, policies learned from one dataset can be transferred to work well on other similar datasets. For example, the policy learned on ImageNet allows us to achieve state-of-the-art accuracy on the fine grained visual classification dataset Stanford Cars, without fine-tuning weights pre-trained on additional data. Code to train Wide-ResNet, Shake-Shake and ShakeDrop models with AutoAugment policies can be found at https://github.com/tensorflow/models/tree/master/research/autoaugment
Intriguing Properties of Adversarial Examples
Nov 08, 2017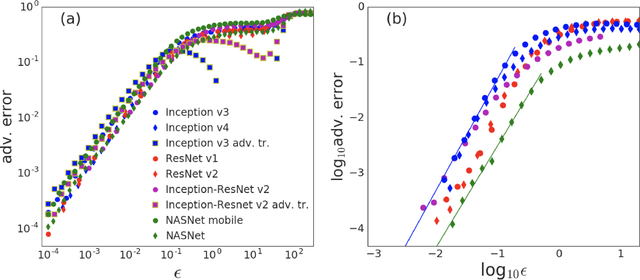

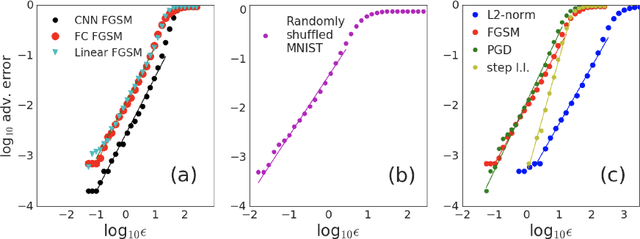
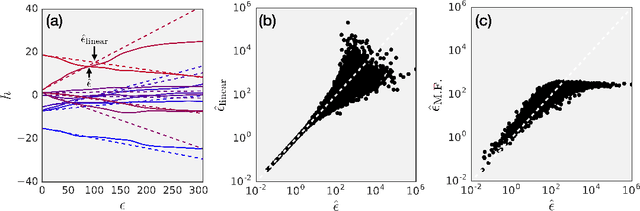
It is becoming increasingly clear that many machine learning classifiers are vulnerable to adversarial examples. In attempting to explain the origin of adversarial examples, previous studies have typically focused on the fact that neural networks operate on high dimensional data, they overfit, or they are too linear. Here we argue that the origin of adversarial examples is primarily due to an inherent uncertainty that neural networks have about their predictions. We show that the functional form of this uncertainty is independent of architecture, dataset, and training protocol; and depends only on the statistics of the logit differences of the network, which do not change significantly during training. This leads to adversarial error having a universal scaling, as a power-law, with respect to the size of the adversarial perturbation. We show that this universality holds for a broad range of datasets (MNIST, CIFAR10, ImageNet, and random data), models (including state-of-the-art deep networks, linear models, adversarially trained networks, and networks trained on randomly shuffled labels), and attacks (FGSM, step l.l., PGD). Motivated by these results, we study the effects of reducing prediction entropy on adversarial robustness. Finally, we study the effect of network architectures on adversarial sensitivity. To do this, we use neural architecture search with reinforcement learning to find adversarially robust architectures on CIFAR10. Our resulting architecture is more robust to white \emph{and} black box attacks compared to previous attempts.