 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRazmecheno: Named Entity Recognition from Digital Archive of Diaries "Prozhito"
Jan 24, 2022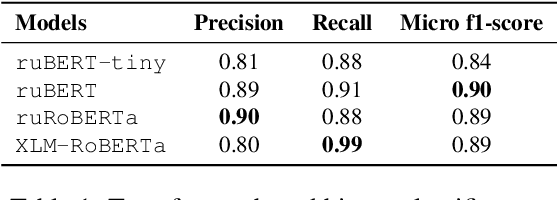

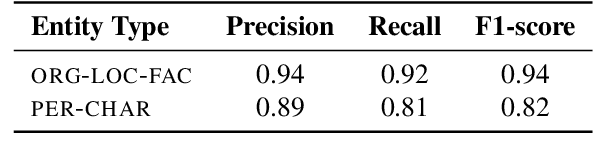
The vast majority of existing datasets for Named Entity Recognition (NER) are built primarily on news, research papers and Wikipedia with a few exceptions, created from historical and literary texts. What is more, English is the main source for data for further labelling. This paper aims to fill in multiple gaps by creating a novel dataset "Razmecheno", gathered from the diary texts of the project "Prozhito" in Russian. Our dataset is of interest for multiple research lines: literary studies of diary texts, transfer learning from other domains, low-resource or cross-lingual named entity recognition. Razmecheno comprises 1331 sentences and 14119 tokens, sampled from diaries, written during the Perestroika. The annotation schema consists of five commonly used entity tags: person, characteristics, location, organisation, and facility. The labelling is carried out on the crowdsourcing platfrom Yandex.Toloka in two stages. First, workers selected sentences, which contain an entity of particular type. Second, they marked up entity spans. As a result 1113 entities were obtained. Empirical evaluation of Razmecheno is carried out with off-the-shelf NER tools and by fine-tuning pre-trained contextualized encoders. We release the annotated dataset for open access.
Call Larisa Ivanovna: Code-Switching Fools Multilingual NLU Models
Sep 29, 2021
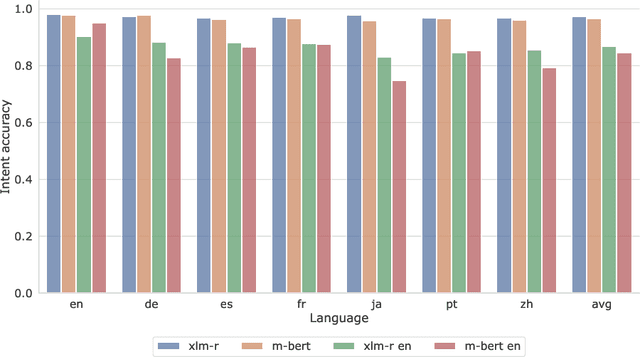

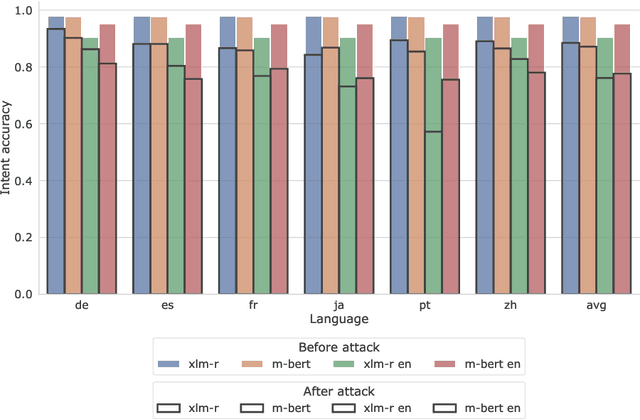
Practical needs of developing task-oriented dialogue assistants require the ability to understand many languages. Novel benchmarks for multilingual natural language understanding (NLU) include monolingual sentences in several languages, annotated with intents and slots. In such setup models for cross-lingual transfer show remarkable performance in joint intent recognition and slot filling. However, existing benchmarks lack of code-switched utterances, which are difficult to gather and label due to complexity in the grammatical structure. The evaluation of NLU models seems biased and limited, since code-switching is being left out of scope. Our work adopts recognized methods to generate plausible and naturally-sounding code-switched utterances and uses them to create a synthetic code-switched test set. Based on experiments, we report that the state-of-the-art NLU models are unable to handle code-switching. At worst, the performance, evaluated by semantic accuracy, drops as low as 15\% from 80\% across languages. Further we show, that pre-training on synthetic code-mixed data helps to maintain performance on the proposed test set at a comparable level with monolingual data. Finally, we analyze different language pairs and show that the closer the languages are, the better the NLU model handles their alternation. This is in line with the common understanding of how multilingual models conduct transferring between languages
Shaking Syntactic Trees on the Sesame Street: Multilingual Probing with Controllable Perturbations
Sep 28, 2021
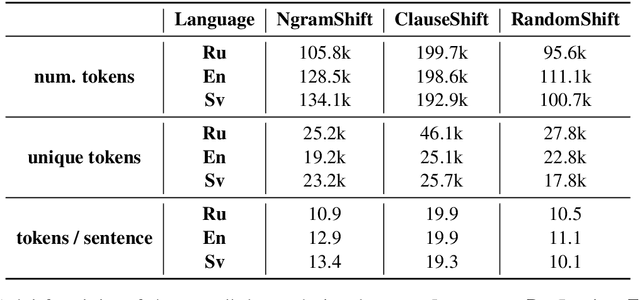
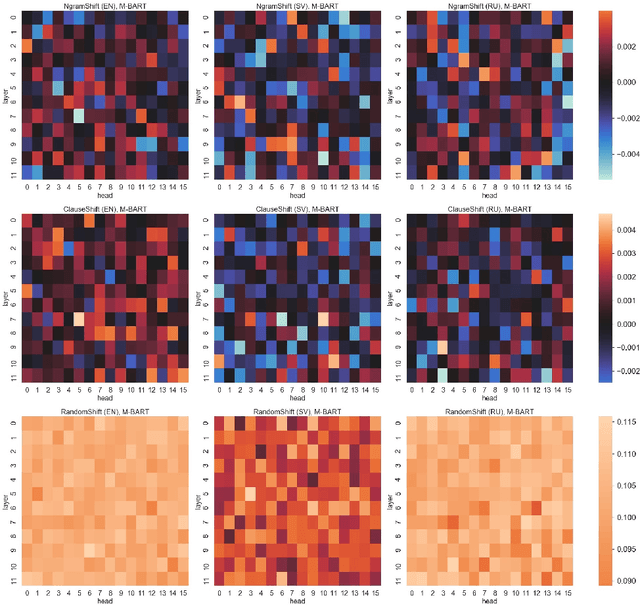

Recent research has adopted a new experimental field centered around the concept of text perturbations which has revealed that shuffled word order has little to no impact on the downstream performance of Transformer-based language models across many NLP tasks. These findings contradict the common understanding of how the models encode hierarchical and structural information and even question if the word order is modeled with position embeddings. To this end, this paper proposes nine probing datasets organized by the type of \emph{controllable} text perturbation for three Indo-European languages with a varying degree of word order flexibility: English, Swedish and Russian. Based on the probing analysis of the M-BERT and M-BART models, we report that the syntactic sensitivity depends on the language and model pre-training objectives. We also find that the sensitivity grows across layers together with the increase of the perturbation granularity. Last but not least, we show that the models barely use the positional information to induce syntactic trees from their intermediate self-attention and contextualized representations.
Artificial Text Detection via Examining the Topology of Attention Maps
Sep 10, 2021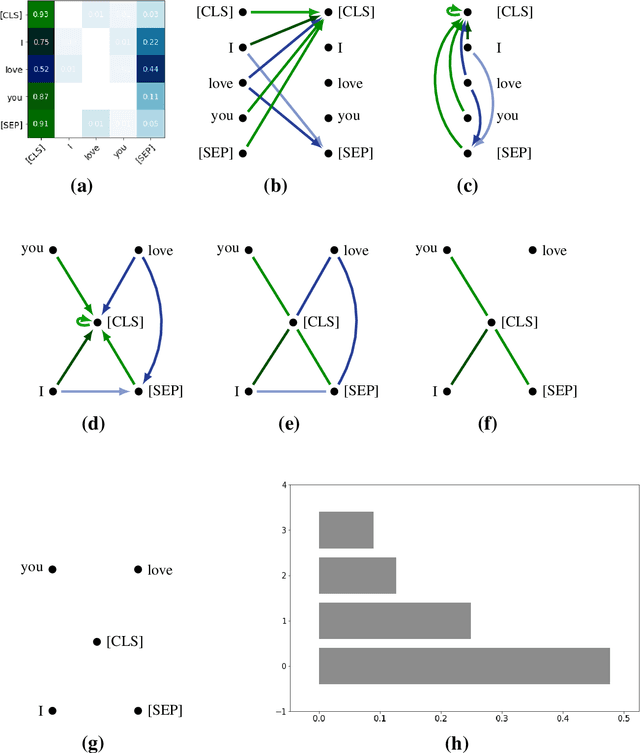
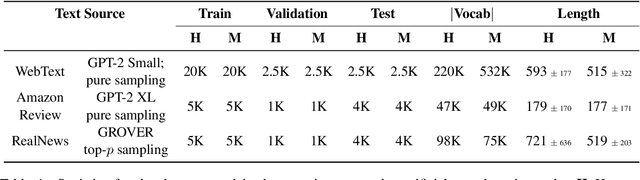
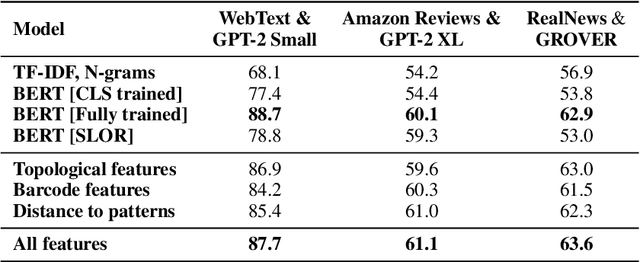
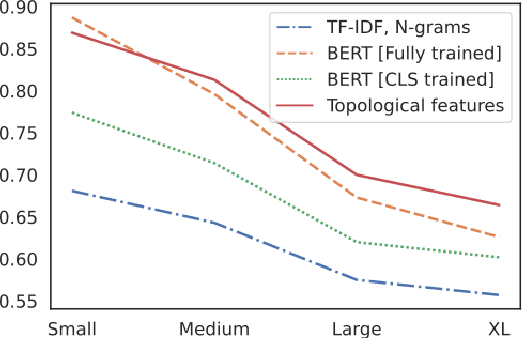
The impressive capabilities of recent generative models to create texts that are challenging to distinguish from the human-written ones can be misused for generating fake news, product reviews, and even abusive content. Despite the prominent performance of existing methods for artificial text detection, they still lack interpretability and robustness towards unseen models. To this end, we propose three novel types of interpretable topological features for this task based on Topological Data Analysis (TDA) which is currently understudied in the field of NLP. We empirically show that the features derived from the BERT model outperform count- and neural-based baselines up to 10\% on three common datasets, and tend to be the most robust towards unseen GPT-style generation models as opposed to existing methods. The probing analysis of the features reveals their sensitivity to the surface and syntactic properties. The results demonstrate that TDA is a promising line with respect to NLP tasks, specifically the ones that incorporate surface and structural information.
NEREL: A Russian Dataset with Nested Named Entities, Relations and Events
Sep 03, 2021
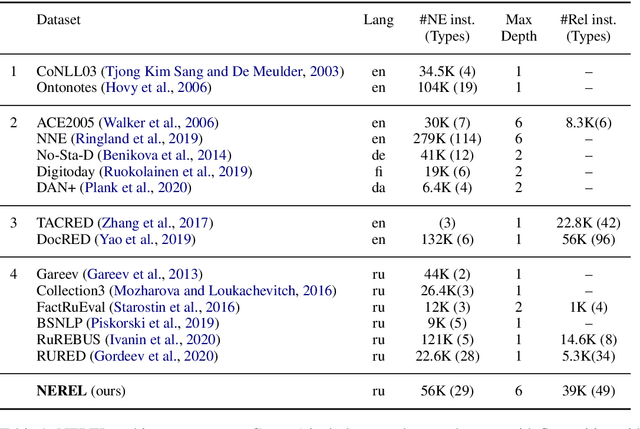
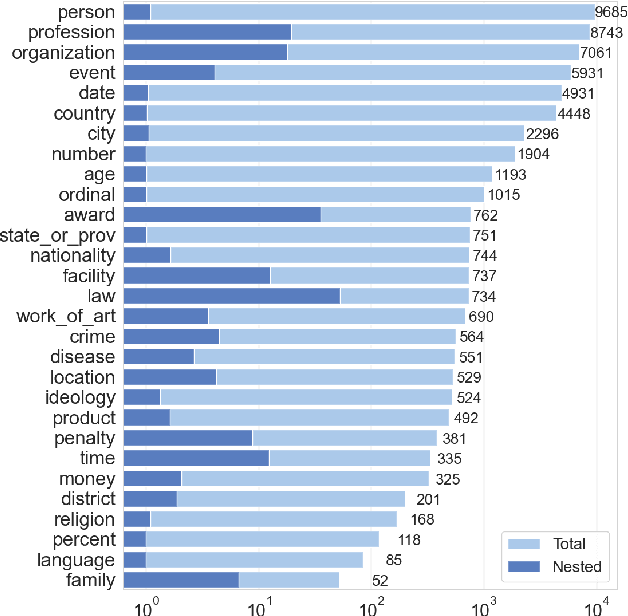
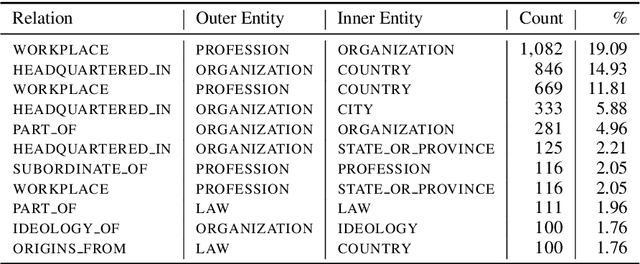
In this paper, we present NEREL, a Russian dataset for named entity recognition and relation extraction. NEREL is significantly larger than existing Russian datasets: to date it contains 56K annotated named entities and 39K annotated relations. Its important difference from previous datasets is annotation of nested named entities, as well as relations within nested entities and at the discourse level. NEREL can facilitate development of novel models that can extract relations between nested named entities, as well as relations on both sentence and document levels. NEREL also contains the annotation of events involving named entities and their roles in the events. The NEREL collection is available via https://github.com/nerel-ds/NEREL.
A Single Example Can Improve Zero-Shot Data Generation
Aug 16, 2021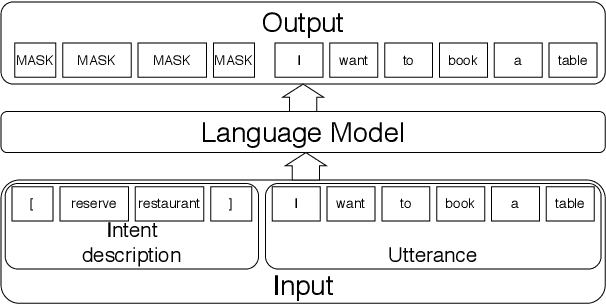
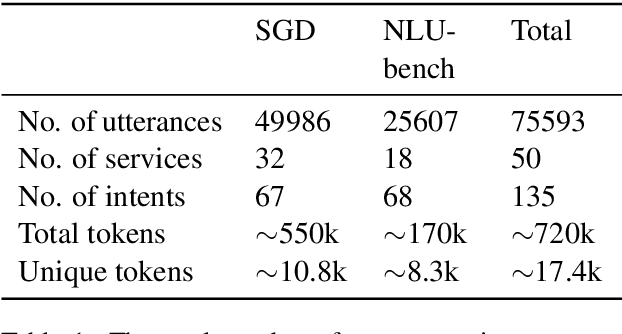
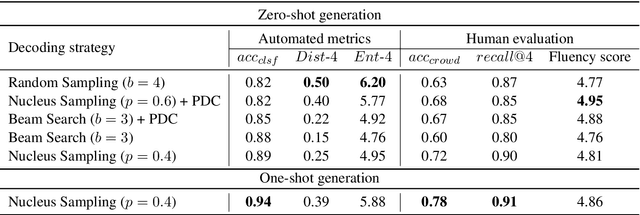
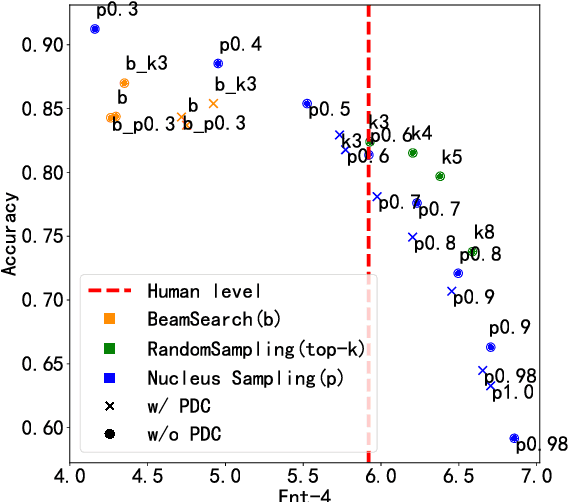
Sub-tasks of intent classification, such as robustness to distribution shift, adaptation to specific user groups and personalization, out-of-domain detection, require extensive and flexible datasets for experiments and evaluation. As collecting such datasets is time- and labor-consuming, we propose to use text generation methods to gather datasets. The generator should be trained to generate utterances that belong to the given intent. We explore two approaches to generating task-oriented utterances. In the zero-shot approach, the model is trained to generate utterances from seen intents and is further used to generate utterances for intents unseen during training. In the one-shot approach, the model is presented with a single utterance from a test intent. We perform a thorough automatic, and human evaluation of the dataset generated utilizing two proposed approaches. Our results reveal that the attributes of the generated data are close to original test sets, collected via crowd-sourcing.
A Differentiable Language Model Adversarial Attack on Text Classifiers
Jul 23, 2021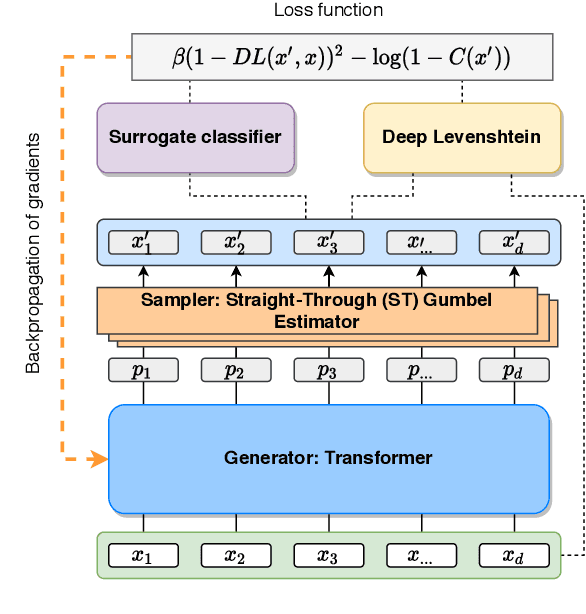
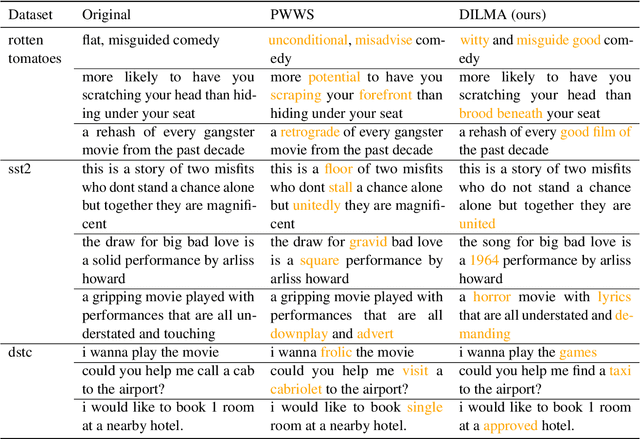
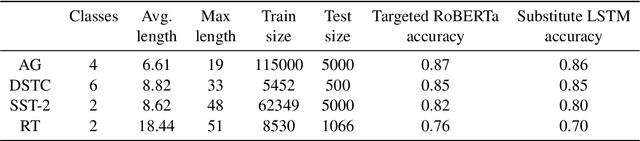
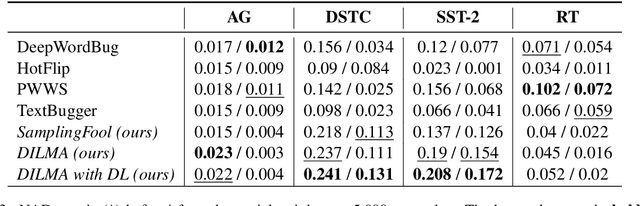
Robustness of huge Transformer-based models for natural language processing is an important issue due to their capabilities and wide adoption. One way to understand and improve robustness of these models is an exploration of an adversarial attack scenario: check if a small perturbation of an input can fool a model. Due to the discrete nature of textual data, gradient-based adversarial methods, widely used in computer vision, are not applicable per~se. The standard strategy to overcome this issue is to develop token-level transformations, which do not take the whole sentence into account. In this paper, we propose a new black-box sentence-level attack. Our method fine-tunes a pre-trained language model to generate adversarial examples. A proposed differentiable loss function depends on a substitute classifier score and an approximate edit distance computed via a deep learning model. We show that the proposed attack outperforms competitors on a diverse set of NLP problems for both computed metrics and human evaluation. Moreover, due to the usage of the fine-tuned language model, the generated adversarial examples are hard to detect, thus current models are not robust. Hence, it is difficult to defend from the proposed attack, which is not the case for other attacks.
Teaching a Massive Open Online Course on Natural Language Processing
May 04, 2021

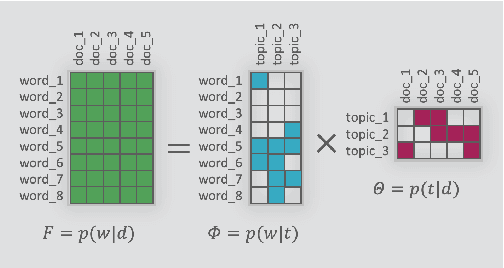
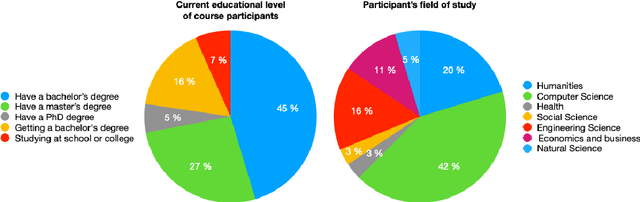
This paper presents a new Massive Open Online Course on Natural Language Processing, targeted at non-English speaking students. The course lasts 12 weeks; every week consists of lectures, practical sessions, and quiz assignments. Three weeks out of 12 are followed by Kaggle-style coding assignments. Our course intends to serve multiple purposes: (i) familiarize students with the core concepts and methods in NLP, such as language modeling or word or sentence representations, (ii) show that recent advances, including pre-trained Transformer-based models, are built upon these concepts; (iii) introduce architectures for most demanded real-life applications, (iv) develop practical skills to process texts in multiple languages. The course was prepared and recorded during 2020, launched by the end of the year, and in early 2021 has received positive feedback.
Morph Call: Probing Morphosyntactic Content of Multilingual Transformers
May 04, 2021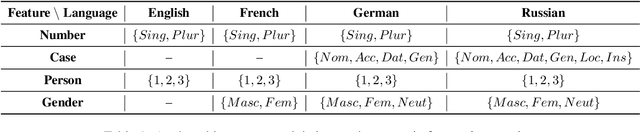
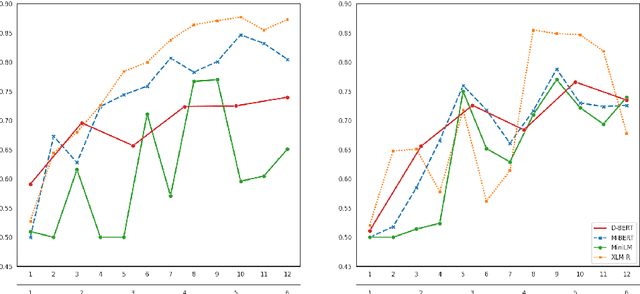
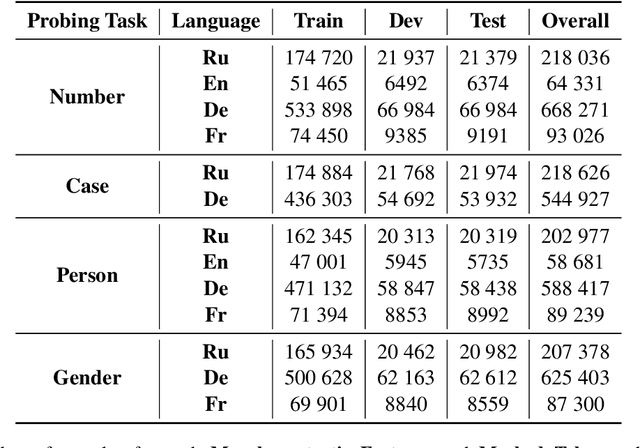
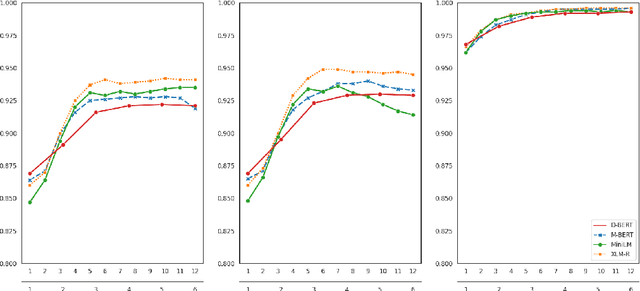
The outstanding performance of transformer-based language models on a great variety of NLP and NLU tasks has stimulated interest in exploring their inner workings. Recent research has focused primarily on higher-level and complex linguistic phenomena such as syntax, semantics, world knowledge, and common sense. The majority of the studies are anglocentric, and little remains known regarding other languages, precisely their morphosyntactic properties. To this end, our work presents Morph Call, a suite of 46 probing tasks for four Indo-European languages of different morphology: English, French, German and Russian. We propose a new type of probing task based on the detection of guided sentence perturbations. We use a combination of neuron-, layer- and representation-level introspection techniques to analyze the morphosyntactic content of four multilingual transformers, including their less explored distilled versions. Besides, we examine how fine-tuning for POS-tagging affects the model knowledge. The results show that fine-tuning can improve and decrease the probing performance and change how morphosyntactic knowledge is distributed across the model. The code and data are publicly available, and we hope to fill the gaps in the less studied aspect of transformers.
MOROCCO: Model Resource Comparison Framework
Apr 29, 2021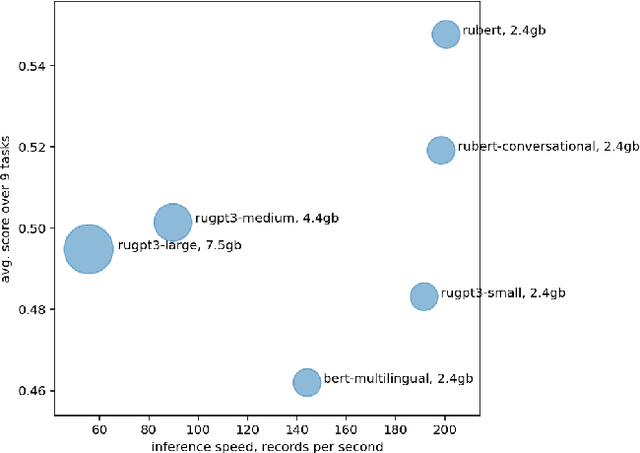
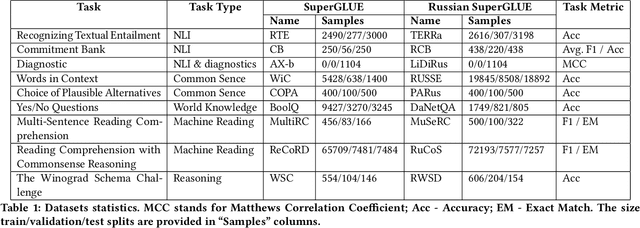
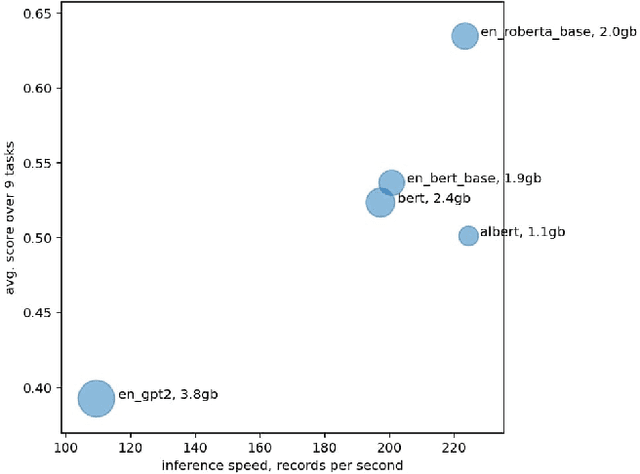
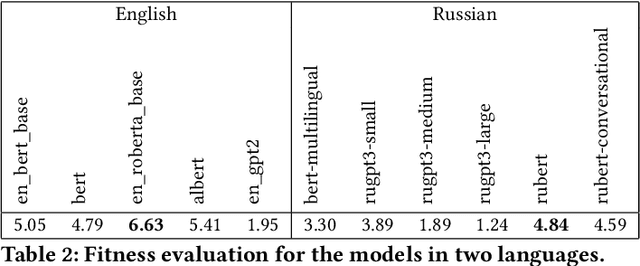
The new generation of pre-trained NLP models push the SOTA to the new limits, but at the cost of computational resources, to the point that their use in real production environments is often prohibitively expensive. We tackle this problem by evaluating not only the standard quality metrics on downstream tasks but also the memory footprint and inference time. We present MOROCCO, a framework to compare language models compatible with \texttt{jiant} environment which supports over 50 NLU tasks, including SuperGLUE benchmark and multiple probing suites. We demonstrate its applicability for two GLUE-like suites in different languages.