 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRusLICA: A Russian-Language Platform for Automated Linguistic Inquiry and Category Analysis
Jan 28, 2026Defining psycholinguistic characteristics in written texts is a task gaining increasing attention from researchers. One of the most widely used tools in the current field is Linguistic Inquiry and Word Count (LIWC) that originally was developed to analyze English texts and translated into multiple languages. Our approach offers the adaptation of LIWC methodology for the Russian language, considering its grammatical and cultural specificities. The suggested approach comprises 96 categories, integrating syntactic, morphological, lexical, general statistical features, and results of predictions obtained using pre-trained language models (LMs) for text analysis. Rather than applying direct translation to existing thesauri, we built the dictionary specifically for the Russian language based on the content from several lexicographic resources, semantic dictionaries and corpora. The paper describes the process of mapping lemmas to 42 psycholinguistic categories and the implementation of the analyzer as part of RusLICA web service.
NorBench -- A Benchmark for Norwegian Language Models
May 06, 2023



We present NorBench: a streamlined suite of NLP tasks and probes for evaluating Norwegian language models (LMs) on standardized data splits and evaluation metrics. We also introduce a range of new Norwegian language models (both encoder and encoder-decoder based). Finally, we compare and analyze their performance, along with other existing LMs, across the different benchmark tests of NorBench.
RuSentEval: Linguistic Source, Encoder Force!
Mar 02, 2021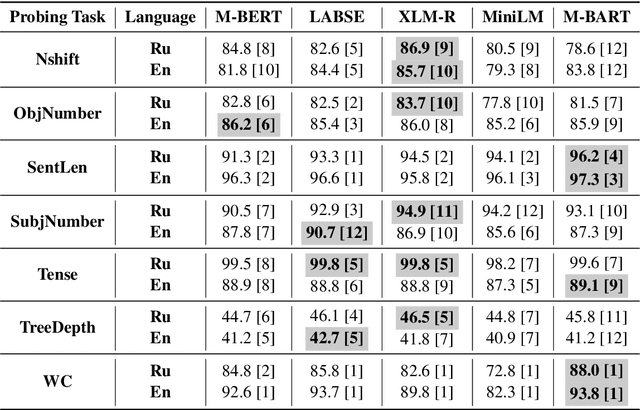
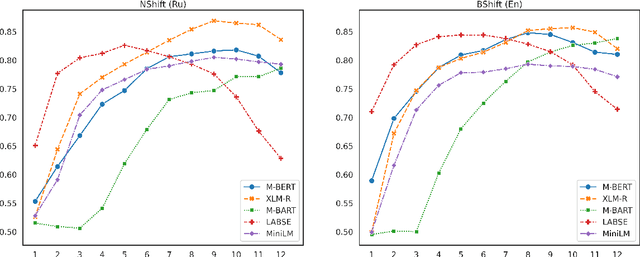
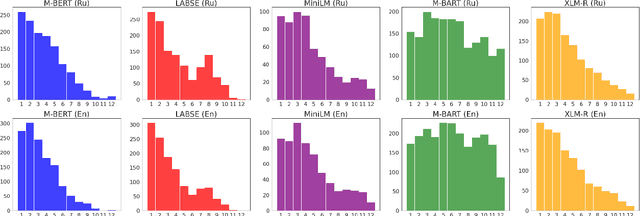
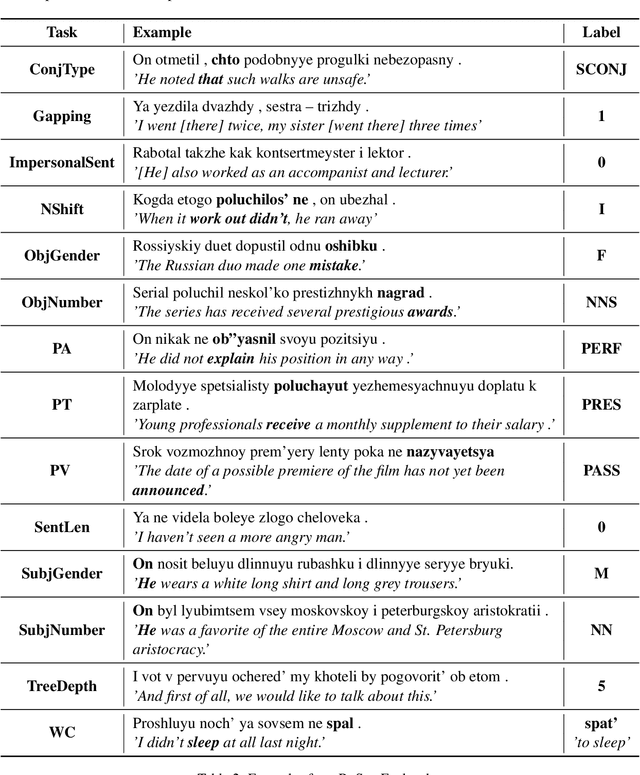
The success of pre-trained transformer language models has brought a great deal of interest on how these models work, and what they learn about language. However, prior research in the field is mainly devoted to English, and little is known regarding other languages. To this end, we introduce RuSentEval, an enhanced set of 14 probing tasks for Russian, including ones that have not been explored yet. We apply a combination of complementary probing methods to explore the distribution of various linguistic properties in five multilingual transformers for two typologically contrasting languages -- Russian and English. Our results provide intriguing findings that contradict the common understanding of how linguistic knowledge is represented, and demonstrate that some properties are learned in a similar manner despite the language differences.