 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuiding Neural Machine Translation with Retrieved Translation Pieces
Apr 07, 2018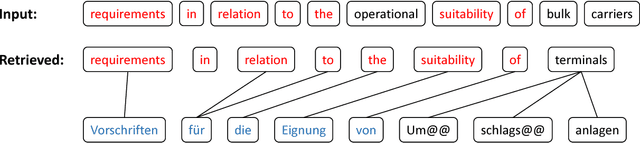

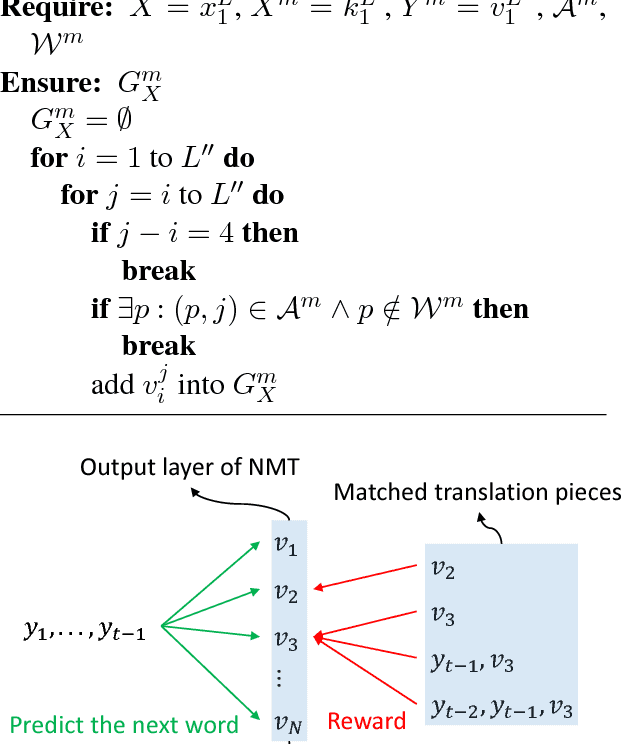
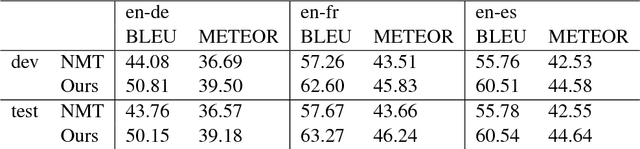
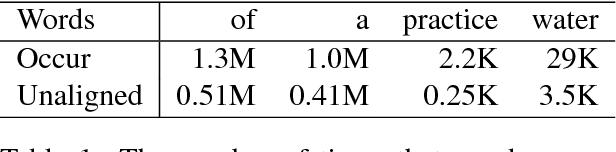
One of the difficulties of neural machine translation (NMT) is the recall and appropriate translation of low-frequency words or phrases. In this paper, we propose a simple, fast, and effective method for recalling previously seen translation examples and incorporating them into the NMT decoding process. Specifically, for an input sentence, we use a search engine to retrieve sentence pairs whose source sides are similar with the input sentence, and then collect $n$-grams that are both in the retrieved target sentences and aligned with words that match in the source sentences, which we call "translation pieces". We compute pseudo-probabilities for each retrieved sentence based on similarities between the input sentence and the retrieved source sentences, and use these to weight the retrieved translation pieces. Finally, an existing NMT model is used to translate the input sentence, with an additional bonus given to outputs that contain the collected translation pieces. We show our method improves NMT translation results up to 6 BLEU points on three narrow domain translation tasks where repetitiveness of the target sentences is particularly salient. It also causes little increase in the translation time, and compares favorably to another alternative retrieval-based method with respect to accuracy, speed, and simplicity of implementation.
Improving Neural Machine Translation through Phrase-based Forced Decoding
Nov 01, 2017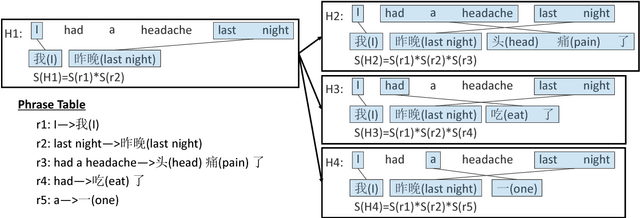

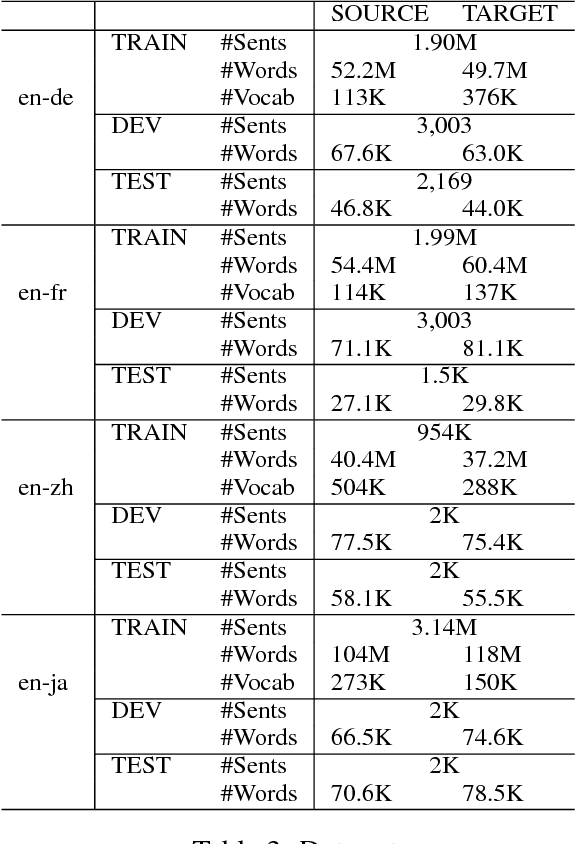
Compared to traditional statistical machine translation (SMT), neural machine translation (NMT) often sacrifices adequacy for the sake of fluency. We propose a method to combine the advantages of traditional SMT and NMT by exploiting an existing phrase-based SMT model to compute the phrase-based decoding cost for an NMT output and then using this cost to rerank the n-best NMT outputs. The main challenge in implementing this approach is that NMT outputs may not be in the search space of the standard phrase-based decoding algorithm, because the search space of phrase-based SMT is limited by the phrase-based translation rule table. We propose a soft forced decoding algorithm, which can always successfully find a decoding path for any NMT output. We show that using the forced decoding cost to rerank the NMT outputs can successfully improve translation quality on four different language pairs.
Connecting Phrase based Statistical Machine Translation Adaptation
Jul 29, 2016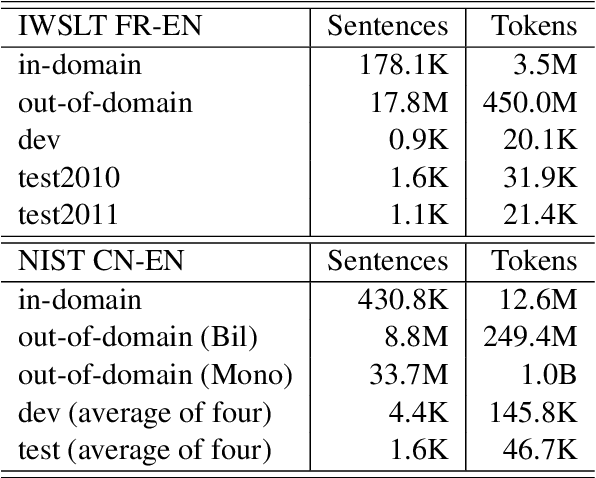
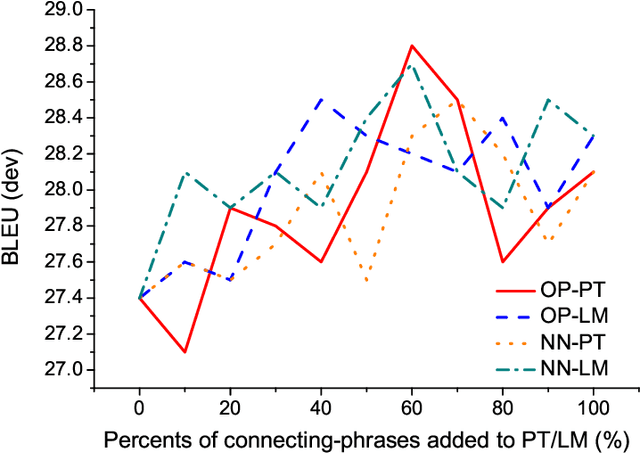
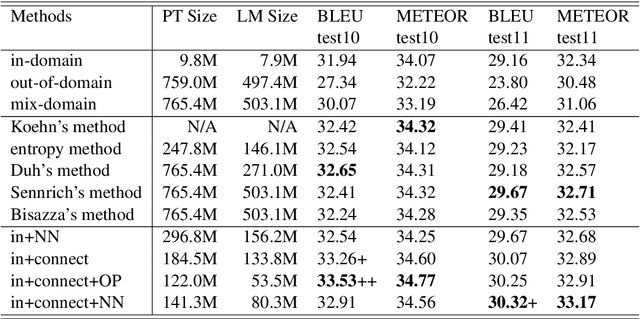
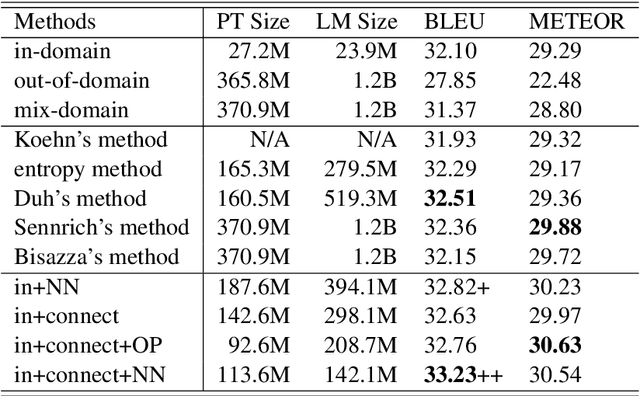
Although more additional corpora are now available for Statistical Machine Translation (SMT), only the ones which belong to the same or similar domains with the original corpus can indeed enhance SMT performance directly. Most of the existing adaptation methods focus on sentence selection. In comparison, phrase is a smaller and more fine grained unit for data selection, therefore we propose a straightforward and efficient connecting phrase based adaptation method, which is applied to both bilingual phrase pair and monolingual n-gram adaptation. The proposed method is evaluated on IWSLT/NIST data sets, and the results show that phrase based SMT performance are significantly improved (up to +1.6 in comparison with phrase based SMT baseline system and +0.9 in comparison with existing methods).
* under review by COLING-2016