 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDon't Guess, Escalate: Towards Explainable Uncertainty-Calibrated AI Forensic Agents
Dec 18, 2025AI is reshaping the landscape of multimedia forensics. We propose AI forensic agents: reliable orchestrators that select and combine forensic detectors, identify provenance and context, and provide uncertainty-aware assessments. We highlight pitfalls in current solutions and introduce a unified framework to improve the authenticity verification process.
Explainable Artifacts for Synthetic Western Blot Source Attribution
Sep 27, 2024



Recent advancements in artificial intelligence have enabled generative models to produce synthetic scientific images that are indistinguishable from pristine ones, posing a challenge even for expert scientists habituated to working with such content. When exploited by organizations known as paper mills, which systematically generate fraudulent articles, these technologies can significantly contribute to the spread of misinformation about ungrounded science, potentially undermining trust in scientific research. While previous studies have explored black-box solutions, such as Convolutional Neural Networks, for identifying synthetic content, only some have addressed the challenge of generalizing across different models and providing insight into the artifacts in synthetic images that inform the detection process. This study aims to identify explainable artifacts generated by state-of-the-art generative models (e.g., Generative Adversarial Networks and Diffusion Models) and leverage them for open-set identification and source attribution (i.e., pointing to the model that created the image).
MetaFood3D: Large 3D Food Object Dataset with Nutrition Values
Sep 03, 2024



Food computing is both important and challenging in computer vision (CV). It significantly contributes to the development of CV algorithms due to its frequent presence in datasets across various applications, ranging from classification and instance segmentation to 3D reconstruction. The polymorphic shapes and textures of food, coupled with high variation in forms and vast multimodal information, including language descriptions and nutritional data, make food computing a complex and demanding task for modern CV algorithms. 3D food modeling is a new frontier for addressing food-related problems, due to its inherent capability to deal with random camera views and its straightforward representation for calculating food portion size. However, the primary hurdle in the development of algorithms for food object analysis is the lack of nutrition values in existing 3D datasets. Moreover, in the broader field of 3D research, there is a critical need for domain-specific test datasets. To bridge the gap between general 3D vision and food computing research, we propose MetaFood3D. This dataset consists of 637 meticulously labeled 3D food objects across 108 categories, featuring detailed nutrition information, weight, and food codes linked to a comprehensive nutrition database. The dataset emphasizes intra-class diversity and includes rich modalities such as textured mesh files, RGB-D videos, and segmentation masks. Experimental results demonstrate our dataset's significant potential for improving algorithm performance, highlight the challenging gap between video captures and 3D scanned data, and show the strength of the MetaFood3D dataset in high-quality data generation, simulation, and augmentation.
MetaFood CVPR 2024 Challenge on Physically Informed 3D Food Reconstruction: Methods and Results
Jul 12, 2024



The increasing interest in computer vision applications for nutrition and dietary monitoring has led to the development of advanced 3D reconstruction techniques for food items. However, the scarcity of high-quality data and limited collaboration between industry and academia have constrained progress in this field. Building on recent advancements in 3D reconstruction, we host the MetaFood Workshop and its challenge for Physically Informed 3D Food Reconstruction. This challenge focuses on reconstructing volume-accurate 3D models of food items from 2D images, using a visible checkerboard as a size reference. Participants were tasked with reconstructing 3D models for 20 selected food items of varying difficulty levels: easy, medium, and hard. The easy level provides 200 images, the medium level provides 30 images, and the hard level provides only 1 image for reconstruction. In total, 16 teams submitted results in the final testing phase. The solutions developed in this challenge achieved promising results in 3D food reconstruction, with significant potential for improving portion estimation for dietary assessment and nutritional monitoring. More details about this workshop challenge and access to the dataset can be found at https://sites.google.com/view/cvpr-metafood-2024.
Skeleton Extraction from 3D Point Clouds by Decomposing the Object into Parts
Dec 26, 2019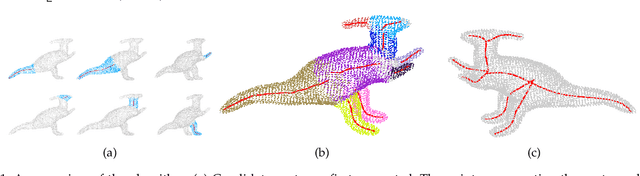
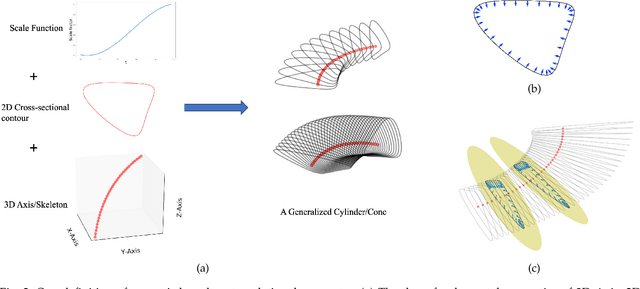

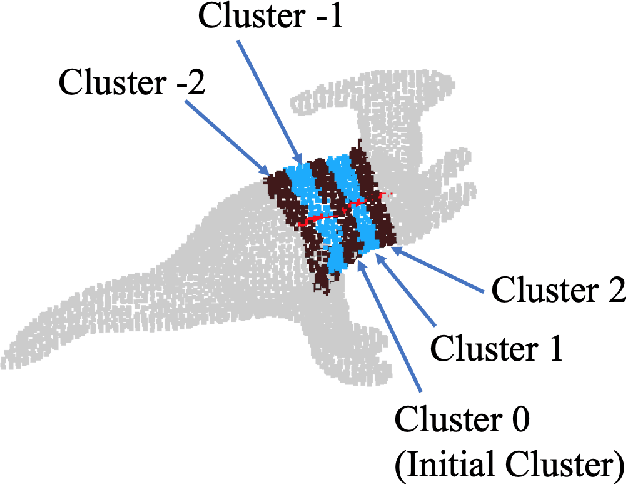
Decomposing a point cloud into its components and extracting curve skeletons from point clouds are two related problems. Decomposition of a shape into its components is often obtained as a byproduct of skeleton extraction. In this work, we propose to extract curve skeletons, from unorganized point clouds, by decomposing the object into its parts, identifying part skeletons and then linking these part skeletons together to obtain the complete skeleton. We believe it is the most natural way to extract skeletons in the sense that this would be the way a human would approach the problem. Our parts are generalized cylinders (GCs). Since, the axis of a GC is an integral part of its definition, the parts have natural skeletal representations. We use translational symmetry, the fundamental property of GCs, to extract parts from point clouds. We demonstrate how this method can handle a large variety of shapes. We compare our method with state of the art methods and show how a part based approach can deal with some of the limitations of other methods. We present an improved version of an existing point set registration algorithm and demonstrate its utility in extracting parts from point clouds. We also show how this method can be used to extract skeletons from and identify parts of noisy point clouds. A part based approach also provides a natural and intuitive interface for user interaction. We demonstrate the ease with which mistakes, if any, can be fixed with minimal user interaction with the help of a graphical user interface.
Weighted Hausdorff Distance: A Loss Function For Object Localization
Jun 20, 2018
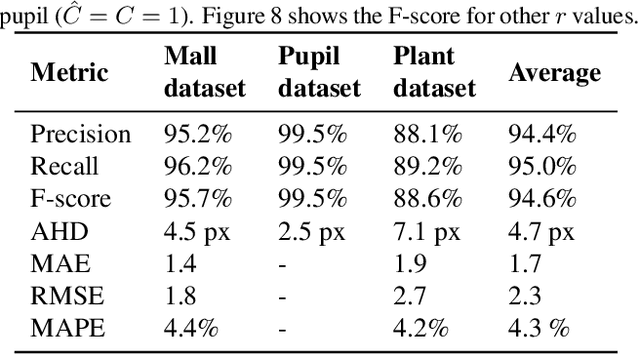

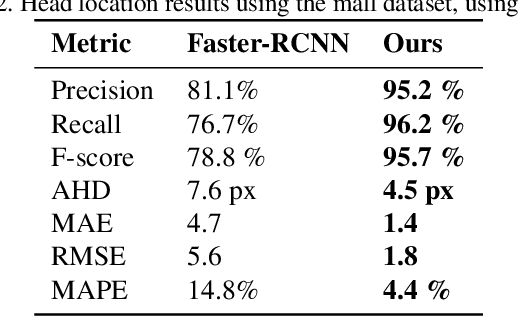
Recent advances in Convolutional Neural Networks (CNN) have achieved remarkable results in localizing objects in images. In these networks, the training procedure usually requires providing bounding boxes or the maximum number of expected objects. In this paper, we address the task of estimating object locations without annotated bounding boxes, which are typically hand-drawn and time consuming to label. We propose a loss function that can be used in any Fully Convolutional Network (FCN) to estimate object locations. This loss function is a modification of the Average Hausdorff Distance between two unordered sets of points. The proposed method does not require one to "guess" the maximum number of objects in the image, and has no notion of bounding boxes, region proposals, or sliding windows. We evaluate our method with three datasets designed to locate people's heads, pupil centers and plant centers. We report an average precision and recall of 94% for the three datasets, and an average location error of 6 pixels in 256x256 images.