 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncremental Learning with Repetition via Pseudo-Feature Projection
Feb 27, 2025Incremental Learning scenarios do not always represent real-world inference use-cases, which tend to have less strict task boundaries, and exhibit repetition of common classes and concepts in their continual data stream. To better represent these use-cases, new scenarios with partial repetition and mixing of tasks are proposed, where the repetition patterns are innate to the scenario and unknown to the strategy. We investigate how exemplar-free incremental learning strategies are affected by data repetition, and we adapt a series of state-of-the-art approaches to analyse and fairly compare them under both settings. Further, we also propose a novel method (Horde), able to dynamically adjust an ensemble of self-reliant feature extractors, and align them by exploiting class repetition. Our proposed exemplar-free method achieves competitive results in the classic scenario without repetition, and state-of-the-art performance in the one with repetition.
Establishing and Evaluating Trustworthy AI: Overview and Research Challenges
Nov 15, 2024



Artificial intelligence (AI) technologies (re-)shape modern life, driving innovation in a wide range of sectors. However, some AI systems have yielded unexpected or undesirable outcomes or have been used in questionable manners. As a result, there has been a surge in public and academic discussions about aspects that AI systems must fulfill to be considered trustworthy. In this paper, we synthesize existing conceptualizations of trustworthy AI along six requirements: 1) human agency and oversight, 2) fairness and non-discrimination, 3) transparency and explainability, 4) robustness and accuracy, 5) privacy and security, and 6) accountability. For each one, we provide a definition, describe how it can be established and evaluated, and discuss requirement-specific research challenges. Finally, we conclude this analysis by identifying overarching research challenges across the requirements with respect to 1) interdisciplinary research, 2) conceptual clarity, 3) context-dependency, 4) dynamics in evolving systems, and 5) investigations in real-world contexts. Thus, this paper synthesizes and consolidates a wide-ranging and active discussion currently taking place in various academic sub-communities and public forums. It aims to serve as a reference for a broad audience and as a basis for future research directions.
A Simulation Benchmark for Autonomous Racing with Large-Scale Human Data
Jul 24, 2024



Despite the availability of international prize-money competitions, scaled vehicles, and simulation environments, research on autonomous racing and the control of sports cars operating close to the limit of handling has been limited by the high costs of vehicle acquisition and management, as well as the limited physics accuracy of open-source simulators. In this paper, we propose a racing simulation platform based on the simulator Assetto Corsa to test, validate, and benchmark autonomous driving algorithms, including reinforcement learning (RL) and classical Model Predictive Control (MPC), in realistic and challenging scenarios. Our contributions include the development of this simulation platform, several state-of-the-art algorithms tailored to the racing environment, and a comprehensive dataset collected from human drivers. Additionally, we evaluate algorithms in the offline RL setting. All the necessary code (including environment and benchmarks), working examples, datasets, and videos are publicly released and can be found at: https://assetto-corsa-gym.github.io
AI-Powered Immersive Assistance for Interactive Task Execution in Industrial Environments
Jul 12, 2024Many industrial sectors rely on well-trained employees that are able to operate complex machinery. In this work, we demonstrate an AI-powered immersive assistance system that supports users in performing complex tasks in industrial environments. Specifically, our system leverages a VR environment that resembles a juice mixer setup. This digital twin of a physical setup simulates complex industrial machinery used to mix preparations or liquids (e.g., similar to the pharmaceutical industry) and includes various containers, sensors, pumps, and flow controllers. This setup demonstrates our system's capabilities in a controlled environment while acting as a proof-of-concept for broader industrial applications. The core components of our multimodal AI assistant are a large language model and a speech-to-text model that process a video and audio recording of an expert performing the task in a VR environment. The video and speech input extracted from the expert's video enables it to provide step-by-step guidance to support users in executing complex tasks. This demonstration showcases the potential of our AI-powered assistant to reduce cognitive load, increase productivity, and enhance safety in industrial environments.
XAI Methods for Neural Time Series Classification: A Brief Review
Aug 18, 2021Deep learning models have recently demonstrated remarkable results in a variety of tasks, which is why they are being increasingly applied in high-stake domains, such as industry, medicine, and finance. Considering that automatic predictions in these domains might have a substantial impact on the well-being of a person, as well as considerable financial and legal consequences to an individual or a company, all actions and decisions that result from applying these models have to be accountable. Given that a substantial amount of data that is collected in high-stake domains are in the form of time series, in this paper we examine the current state of eXplainable AI (XAI) methods with a focus on approaches for opening up deep learning black boxes for the task of time series classification. Finally, our contribution also aims at deriving promising directions for future work, to advance XAI for deep learning on time series data.
* 8 pages, 0 figures, Accepted as a poster presentation
Acting upon Imagination: when to trust imagined trajectories in model based reinforcement learning
May 13, 2021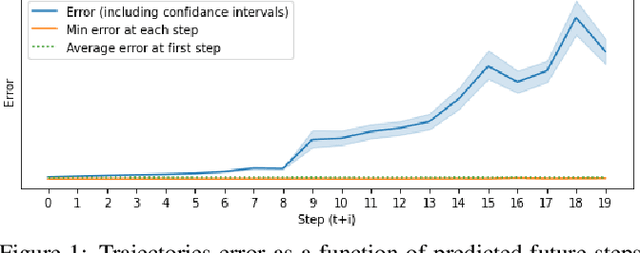
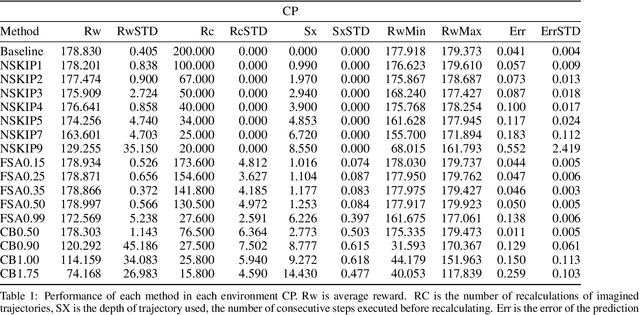

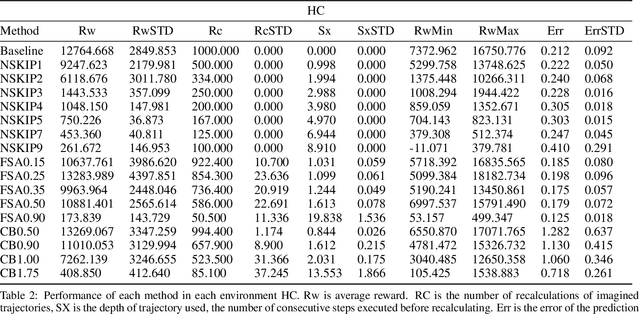
Model based reinforcement learning (MBRL) uses an imperfect model of the world to imagine trajectories of future states and plan the best actions to maximize a reward function. These trajectories are imperfect and MBRL attempts to overcome this by relying on model predictive control (MPC) to continuously re-imagine trajectories from scratch. Such re-generation of imagined trajectories carries the major computational cost and increasing complexity in tasks with longer receding horizon. This paper aims to investigate how far in the future the imagined trajectories can be relied upon while still maintaining acceptable reward. Firstly, an error analysis is presented for systematic skipping recalculations for varying number of consecutive steps.% in several challenging benchmark control tasks. Secondly, we propose two methods offering when to trust and act upon imagined trajectories, looking at recent errors with respect to expectations, or comparing the confidence in an action imagined against its execution. Thirdly, we evaluate the effects of acting upon imagination while training the model of the world. Results show that acting upon imagination can reduce calculations by at least 20% and up to 80%, depending on the environment, while retaining acceptable reward.
Formula RL: Deep Reinforcement Learning for Autonomous Racing using Telemetry Data
Apr 22, 2021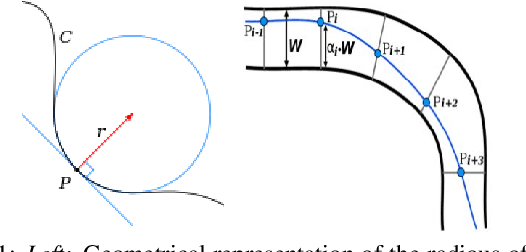

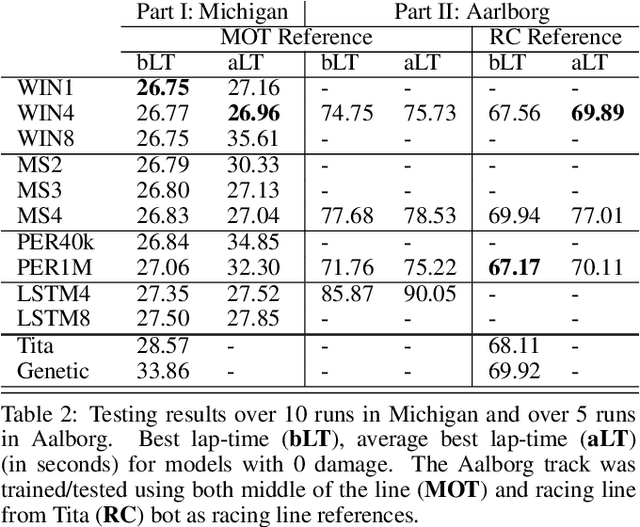
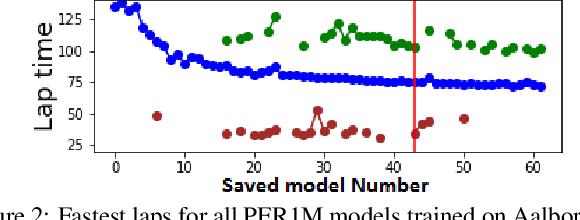
This paper explores the use of reinforcement learning (RL) models for autonomous racing. In contrast to passenger cars, where safety is the top priority, a racing car aims to minimize the lap-time. We frame the problem as a reinforcement learning task with a multidimensional input consisting of the vehicle telemetry, and a continuous action space. To find out which RL methods better solve the problem and whether the obtained models generalize to driving on unknown tracks, we put 10 variants of deep deterministic policy gradient (DDPG) to race in two experiments: i)~studying how RL methods learn to drive a racing car and ii)~studying how the learning scenario influences the capability of the models to generalize. Our studies show that models trained with RL are not only able to drive faster than the baseline open source handcrafted bots but also generalize to unknown tracks.