 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFair Agents: Balancing Multistakeholder Alignment in Multi-Agent Personalization Systems
May 04, 2026LLM agents are increasingly used for personalization due to their ability to communicate directly with users in natural language, integrate external knowledge bases, and negotiate with other (possibly human) agents. Especially in multistakeholder AI systems with multiple distinct objectives, LLM agents are used to independently optimize for each stakeholder's goals. Here, stakeholder alignment is essential to identify and map these goals to provide LLM agents with quantifiable objectives. Plus, the way in which the outputs of the LLM agents are aggregated is fundamental to ensuring fair outcomes for all agents and, therefore, stakeholders. In this work, we identify open research challenges and propose a conceptual framework for designing fair multi-agent multistakeholder personalization systems that balance competing stakeholder objectives. Our framework integrates (i) methods to align stakeholder objectives and LLM agents, (ii) aggregation strategies, e.g., based on social choice theory, to form fair collective decisions, and (iii) stakeholder-centric evaluation procedures for both individual and collective agent behavior. We showcase our framework through a tourism use case and discuss possible applications in other domains, such as education and healthcare. Finally, we discuss domain-specific fairness tensions and review datasets for evaluating multistakeholder fairness and multi-agent personalization systems.
Establishing and Evaluating Trustworthy AI: Overview and Research Challenges
Nov 15, 2024



Artificial intelligence (AI) technologies (re-)shape modern life, driving innovation in a wide range of sectors. However, some AI systems have yielded unexpected or undesirable outcomes or have been used in questionable manners. As a result, there has been a surge in public and academic discussions about aspects that AI systems must fulfill to be considered trustworthy. In this paper, we synthesize existing conceptualizations of trustworthy AI along six requirements: 1) human agency and oversight, 2) fairness and non-discrimination, 3) transparency and explainability, 4) robustness and accuracy, 5) privacy and security, and 6) accountability. For each one, we provide a definition, describe how it can be established and evaluated, and discuss requirement-specific research challenges. Finally, we conclude this analysis by identifying overarching research challenges across the requirements with respect to 1) interdisciplinary research, 2) conceptual clarity, 3) context-dependency, 4) dynamics in evolving systems, and 5) investigations in real-world contexts. Thus, this paper synthesizes and consolidates a wide-ranging and active discussion currently taking place in various academic sub-communities and public forums. It aims to serve as a reference for a broad audience and as a basis for future research directions.
AI-Powered Immersive Assistance for Interactive Task Execution in Industrial Environments
Jul 12, 2024Many industrial sectors rely on well-trained employees that are able to operate complex machinery. In this work, we demonstrate an AI-powered immersive assistance system that supports users in performing complex tasks in industrial environments. Specifically, our system leverages a VR environment that resembles a juice mixer setup. This digital twin of a physical setup simulates complex industrial machinery used to mix preparations or liquids (e.g., similar to the pharmaceutical industry) and includes various containers, sensors, pumps, and flow controllers. This setup demonstrates our system's capabilities in a controlled environment while acting as a proof-of-concept for broader industrial applications. The core components of our multimodal AI assistant are a large language model and a speech-to-text model that process a video and audio recording of an expert performing the task in a VR environment. The video and speech input extracted from the expert's video enables it to provide step-by-step guidance to support users in executing complex tasks. This demonstration showcases the potential of our AI-powered assistant to reduce cognitive load, increase productivity, and enhance safety in industrial environments.
The Impact of Differential Privacy on Recommendation Accuracy and Popularity Bias
Jan 15, 2024



Collaborative filtering-based recommender systems leverage vast amounts of behavioral user data, which poses severe privacy risks. Thus, often, random noise is added to the data to ensure Differential Privacy (DP). However, to date, it is not well understood, in which ways this impacts personalized recommendations. In this work, we study how DP impacts recommendation accuracy and popularity bias, when applied to the training data of state-of-the-art recommendation models. Our findings are three-fold: First, we find that nearly all users' recommendations change when DP is applied. Second, recommendation accuracy drops substantially while recommended item popularity experiences a sharp increase, suggesting that popularity bias worsens. Third, we find that DP exacerbates popularity bias more severely for users who prefer unpopular items than for users that prefer popular items.
ReuseKNN: Neighborhood Reuse for Privacy-Aware Recommendations
Jun 23, 2022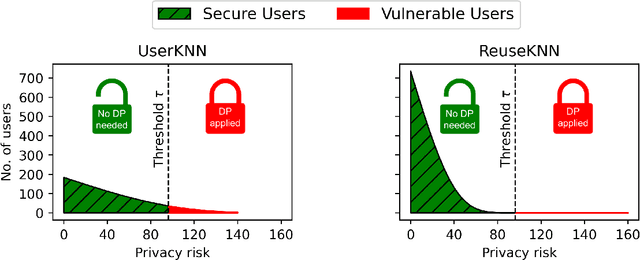

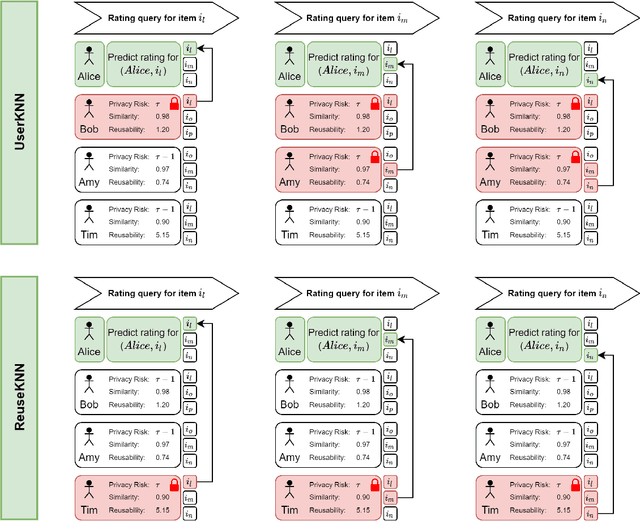
User-based KNN recommender systems (UserKNN) utilize the rating data of a target user's k nearest neighbors in the recommendation process. This, however, increases the privacy risk of the neighbors since their rating data might be exposed to other users or malicious parties. To reduce this risk, existing work applies differential privacy by adding randomness to the neighbors' ratings, which reduces the accuracy of UserKNN. In this work, we introduce ReuseKNN, a novel privacy-aware recommender system. The main idea is to identify small but highly reusable neighborhoods so that (i) only a minimal set of users requires protection with differential privacy, and (ii) most users do not need to be protected with differential privacy, since they are only rarely exploited as neighbors. In our experiments on five diverse datasets, we make two key observations: Firstly, ReuseKNN requires significantly smaller neighborhoods, and thus, fewer neighbors need to be protected with differential privacy compared to traditional UserKNN. Secondly, despite the small neighborhoods, ReuseKNN outperforms UserKNN and a fully differentially private approach in terms of accuracy. Overall, ReuseKNN's recommendation process leads to significantly less privacy risk for users than in the case of UserKNN
Position Paper on Simulating Privacy Dynamics in Recommender Systems
Sep 14, 2021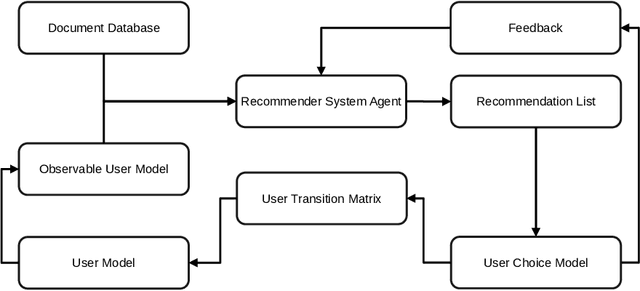
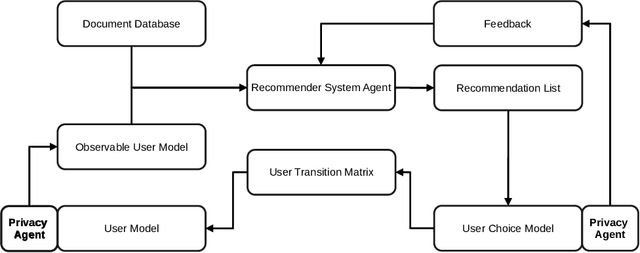
In this position paper, we discuss the merits of simulating privacy dynamics in recommender systems. We study this issue at hand from two perspectives: Firstly, we present a conceptual approach to integrate privacy into recommender system simulations, whose key elements are privacy agents. These agents can enhance users' profiles with different privacy preferences, e.g., their inclination to disclose data to the recommender system. Plus, they can protect users' privacy by guarding all actions that could be a threat to privacy. For example, agents can prohibit a user's privacy-threatening actions or apply privacy-enhancing techniques, e.g., Differential Privacy, to make actions less threatening. Secondly, we identify three critical topics for future research in privacy-aware recommender system simulations: (i) How could we model users' privacy preferences and protect users from performing any privacy-threatening actions? (ii) To what extent do privacy agents modify the users' document preferences? (iii) How do privacy preferences and privacy protections impact recommendations and privacy of others? Our conceptual privacy-aware simulation approach makes it possible to investigate the impact of privacy preferences and privacy protection on the micro-level, i.e., a single user, but also on the macro-level, i.e., all recommender system users. With this work, we hope to present perspectives on how privacy-aware simulations could be realized, such that they enable researchers to study the dynamics of privacy within a recommender system.
Robustness of Meta Matrix Factorization Against Strict Privacy Constraints
Jan 18, 2021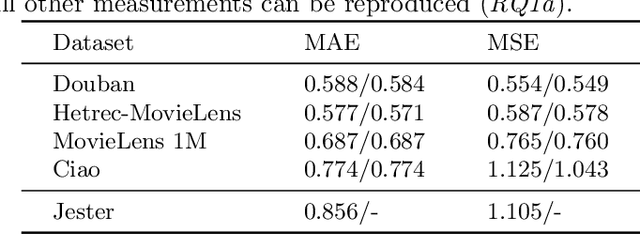
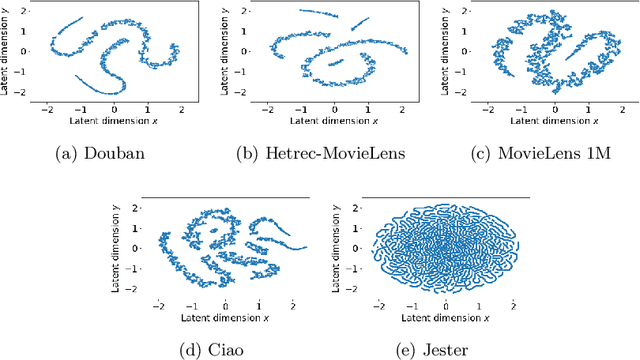
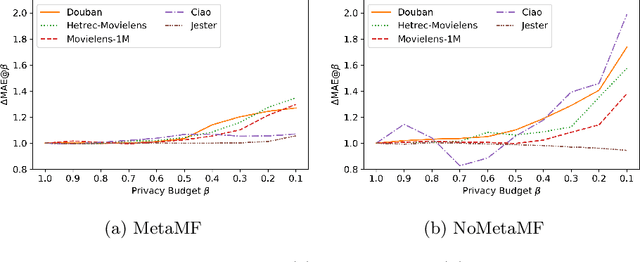
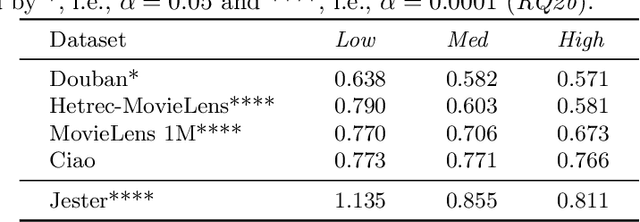
In this paper, we explore the reproducibility of MetaMF, a meta matrix factorization framework introduced by Lin et al. MetaMF employs meta learning for federated rating prediction to preserve users' privacy. We reproduce the experiments of Lin et al. on five datasets, i.e., Douban, Hetrec-MovieLens, MovieLens 1M, Ciao, and Jester. Also, we study the impact of meta learning on the accuracy of MetaMF's recommendations. Furthermore, in our work, we acknowledge that users may have different tolerances for revealing information about themselves. Hence, in a second strand of experiments, we investigate the robustness of MetaMF against strict privacy constraints. Our study illustrates that we can reproduce most of Lin et al.'s results. Plus, we provide strong evidence that meta learning is essential for MetaMF's robustness against strict privacy constraints.