 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGet It in Writing: Formal Contracts Mitigate Social Dilemmas in Multi-Agent RL
Aug 22, 2022
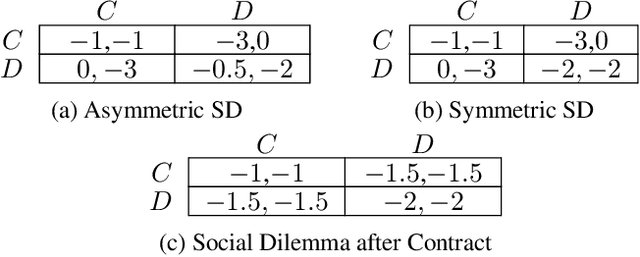
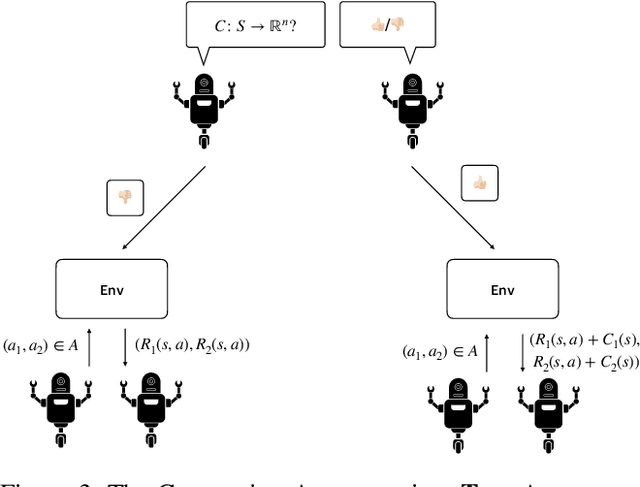
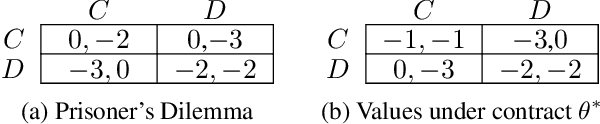
Multi-agent reinforcement learning (MARL) is a powerful tool for training automated systems acting independently in a common environment. However, it can lead to sub-optimal behavior when individual incentives and group incentives diverge. Humans are remarkably capable at solving these social dilemmas. It is an open problem in MARL to replicate such cooperative behaviors in selfish agents. In this work, we draw upon the idea of formal contracting from economics to overcome diverging incentives between agents in MARL. We propose an augmentation to a Markov game where agents voluntarily agree to binding state-dependent transfers of reward, under pre-specified conditions. Our contributions are theoretical and empirical. First, we show that this augmentation makes all subgame-perfect equilibria of all fully observed Markov games exhibit socially optimal behavior, given a sufficiently rich space of contracts. Next, we complement our game-theoretic analysis by showing that state-of-the-art RL algorithms learn socially optimal policies given our augmentation. Our experiments include classic static dilemmas like Stag Hunt, Prisoner's Dilemma and a public goods game, as well as dynamic interactions that simulate traffic, pollution management and common pool resource management.
Towards Psychologically-Grounded Dynamic Preference Models
Aug 06, 2022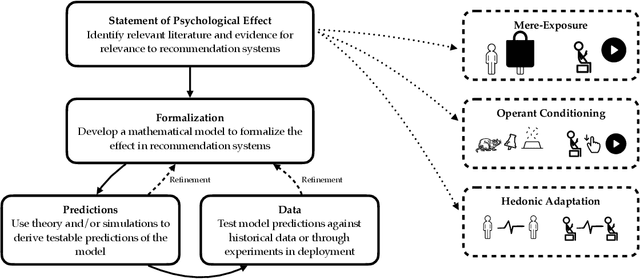
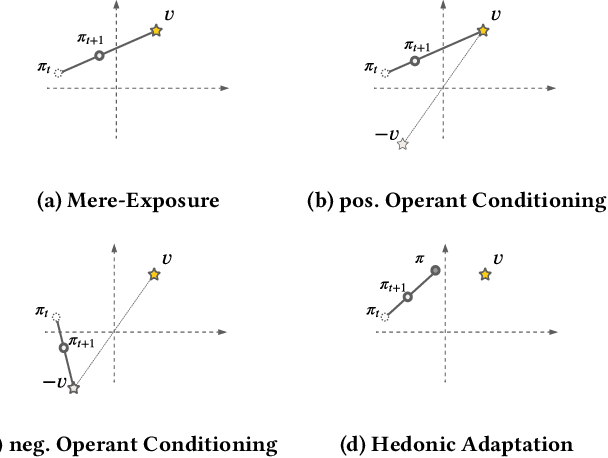
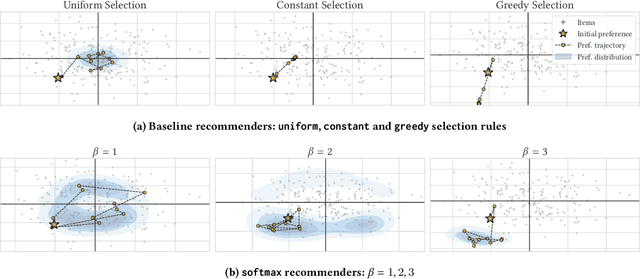
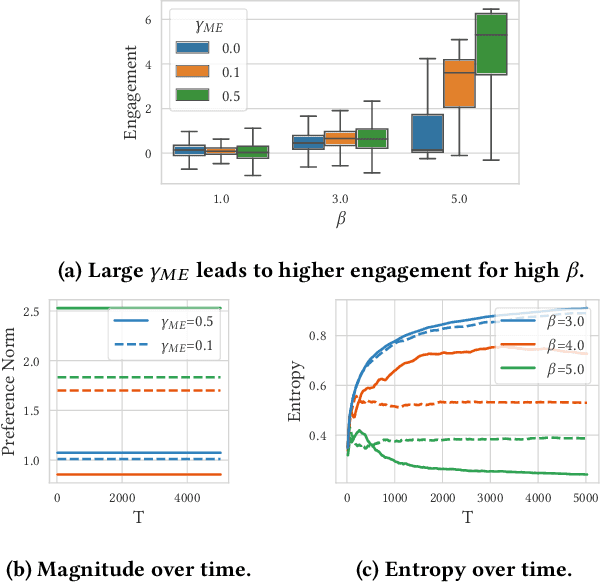
Designing recommendation systems that serve content aligned with time varying preferences requires proper accounting of the feedback effects of recommendations on human behavior and psychological condition. We argue that modeling the influence of recommendations on people's preferences must be grounded in psychologically plausible models. We contribute a methodology for developing grounded dynamic preference models. We demonstrate this method with models that capture three classic effects from the psychology literature: Mere-Exposure, Operant Conditioning, and Hedonic Adaptation. We conduct simulation-based studies to show that the psychological models manifest distinct behaviors that can inform system design. Our study has two direct implications for dynamic user modeling in recommendation systems. First, the methodology we outline is broadly applicable for psychologically grounding dynamic preference models. It allows us to critique recent contributions based on their limited discussion of psychological foundation and their implausible predictions. Second, we discuss implications of dynamic preference models for recommendation systems evaluation and design. In an example, we show that engagement and diversity metrics may be unable to capture desirable recommendation system performance.
Toward Transparent AI: A Survey on Interpreting the Inner Structures of Deep Neural Networks
Jul 28, 2022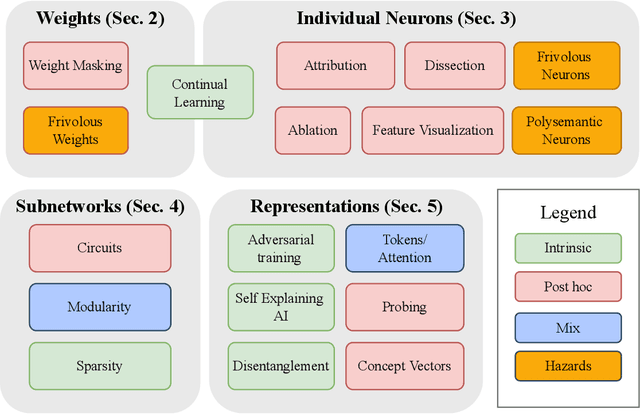
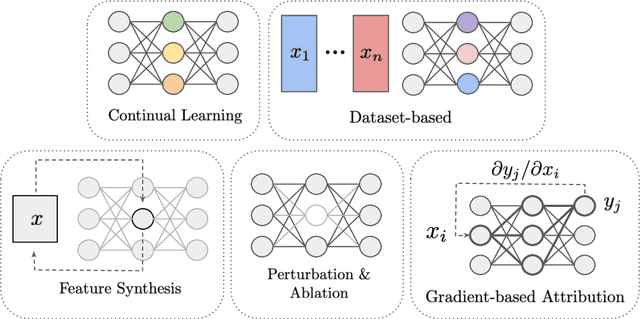
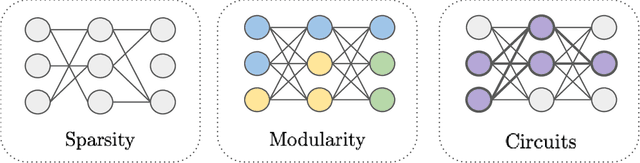
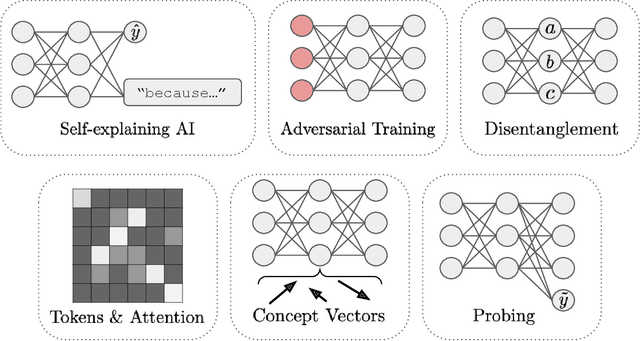
The last decade of machine learning has seen drastic increases in scale and capabilities, and deep neural networks (DNNs) are increasingly being deployed across a wide range of domains. However, the inner workings of DNNs are generally difficult to understand, raising concerns about the safety of using these systems without a rigorous understanding of how they function. In this survey, we review literature on techniques for interpreting the inner components of DNNs, which we call "inner" interpretability methods. Specifically, we review methods for interpreting weights, neurons, subnetworks, and latent representations with a focus on how these techniques relate to the goal of designing safer, more trustworthy AI systems. We also highlight connections between interpretability and work in modularity, adversarial robustness, continual learning, network compression, and studying the human visual system. Finally, we discuss key challenges and argue for future work in interpretability for AI safety that focuses on diagnostics, benchmarking, and robustness.
Building Human Values into Recommender Systems: An Interdisciplinary Synthesis
Jul 20, 2022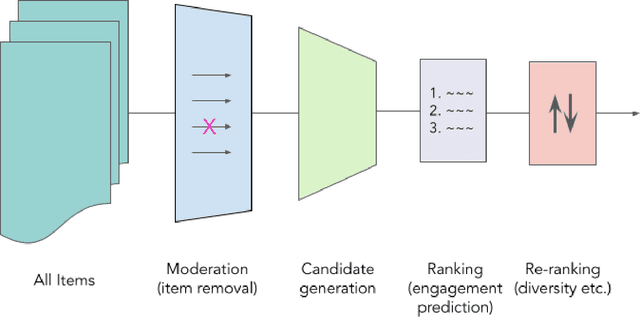
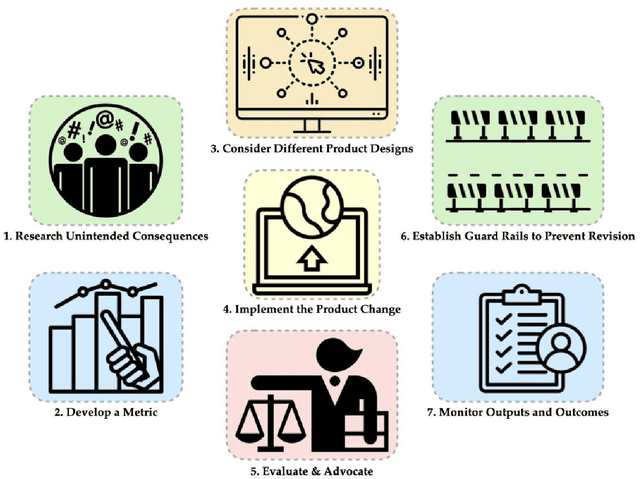
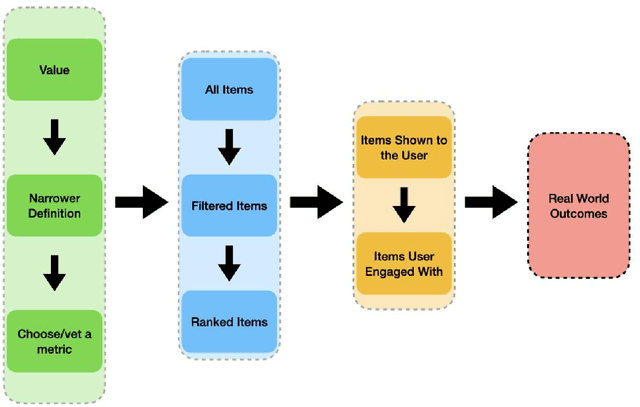

Recommender systems are the algorithms which select, filter, and personalize content across many of the worlds largest platforms and apps. As such, their positive and negative effects on individuals and on societies have been extensively theorized and studied. Our overarching question is how to ensure that recommender systems enact the values of the individuals and societies that they serve. Addressing this question in a principled fashion requires technical knowledge of recommender design and operation, and also critically depends on insights from diverse fields including social science, ethics, economics, psychology, policy and law. This paper is a multidisciplinary effort to synthesize theory and practice from different perspectives, with the goal of providing a shared language, articulating current design approaches, and identifying open problems. It is not a comprehensive survey of this large space, but a set of highlights identified by our diverse author cohort. We collect a set of values that seem most relevant to recommender systems operating across different domains, then examine them from the perspectives of current industry practice, measurement, product design, and policy approaches. Important open problems include multi-stakeholder processes for defining values and resolving trade-offs, better values-driven measurements, recommender controls that people use, non-behavioral algorithmic feedback, optimization for long-term outcomes, causal inference of recommender effects, academic-industry research collaborations, and interdisciplinary policy-making.
How to talk so your robot will learn: Instructions, descriptions, and pragmatics
Jun 16, 2022
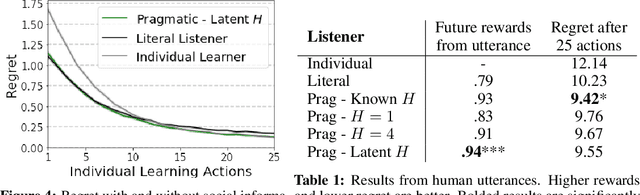
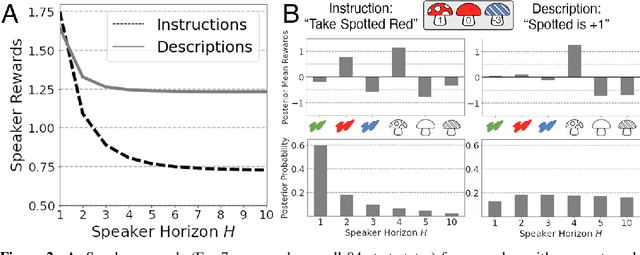
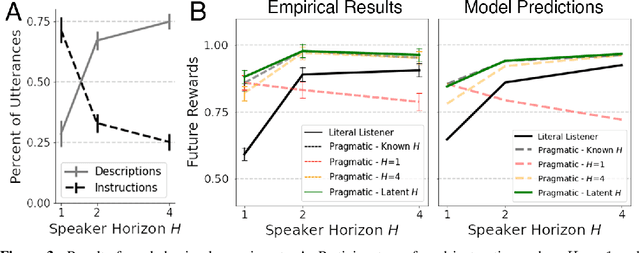
From the earliest years of our lives, humans use language to express our beliefs and desires. Being able to talk to artificial agents about our preferences would thus fulfill a central goal of value alignment. Yet today, we lack computational models explaining such flexible and abstract language use. To address this challenge, we consider social learning in a linear bandit setting and ask how a human might communicate preferences over behaviors (i.e. the reward function). We study two distinct types of language: instructions, which provide information about the desired policy, and descriptions, which provide information about the reward function. To explain how humans use these forms of language, we suggest they reason about both known present and unknown future states: instructions optimize for the present, while descriptions generalize to the future. We formalize this choice by extending reward design to consider a distribution over states. We then define a pragmatic listener agent that infers the speaker's reward function by reasoning about how the speaker expresses themselves. We validate our models with a behavioral experiment, demonstrating that (1) our speaker model predicts spontaneous human behavior, and (2) our pragmatic listener is able to recover their reward functions. Finally, we show that in traditional reinforcement learning settings, pragmatic social learning can integrate with and accelerate individual learning. Our findings suggest that social learning from a wider range of language -- in particular, expanding the field's present focus on instructions to include learning from descriptions -- is a promising approach for value alignment and reinforcement learning more broadly.
Estimating and Penalizing Induced Preference Shifts in Recommender Systems
Apr 25, 2022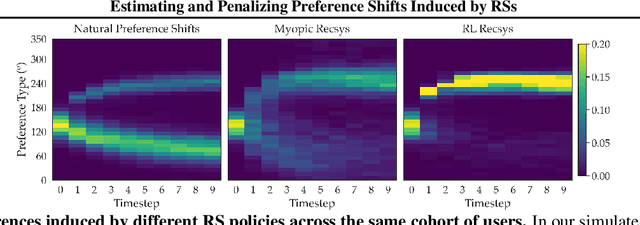
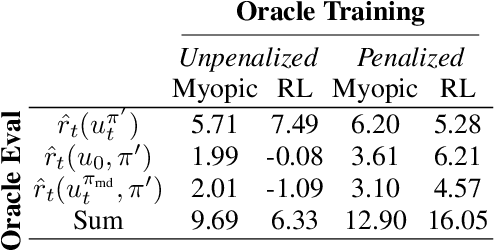
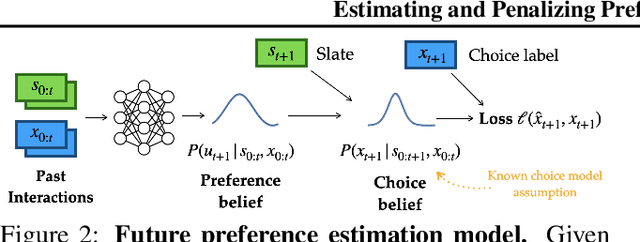
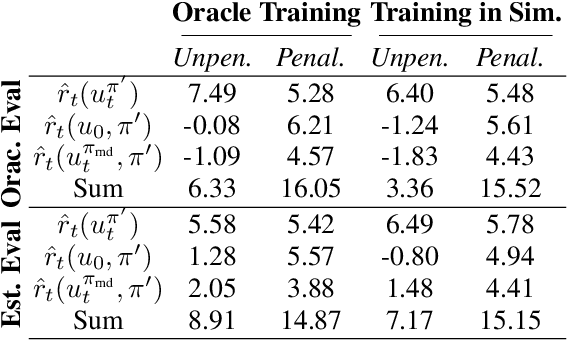
The content that a recommender system (RS) shows to users influences them. Therefore, when choosing which recommender to deploy, one is implicitly also choosing to induce specific internal states in users. Even more, systems trained via long-horizon optimization will have direct incentives to manipulate users, e.g. shift their preferences so they are easier to satisfy. In this work we focus on induced preference shifts in users. We argue that - before deployment - system designers should: estimate the shifts a recommender would induce; evaluate whether such shifts would be undesirable; and even actively optimize to avoid problematic shifts. These steps involve two challenging ingredients: estimation requires anticipating how hypothetical policies would influence user preferences if deployed - we do this by using historical user interaction data to train predictive user model which implicitly contains their preference dynamics; evaluation and optimization additionally require metrics to assess whether such influences are manipulative or otherwise unwanted - we use the notion of "safe shifts", that define a trust region within which behavior is safe. In simulated experiments, we show that our learned preference dynamics model is effective in estimating user preferences and how they would respond to new recommenders. Additionally, we show that recommenders that optimize for staying in the trust region can avoid manipulative behaviors while still generating engagement.
Linguistic communication as (inverse) reward design
Apr 11, 2022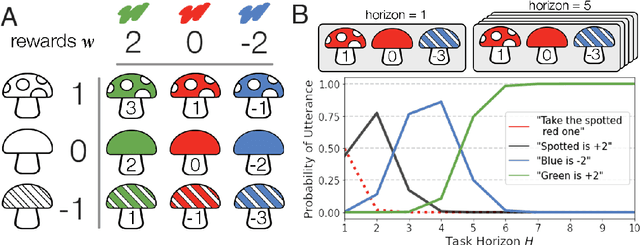
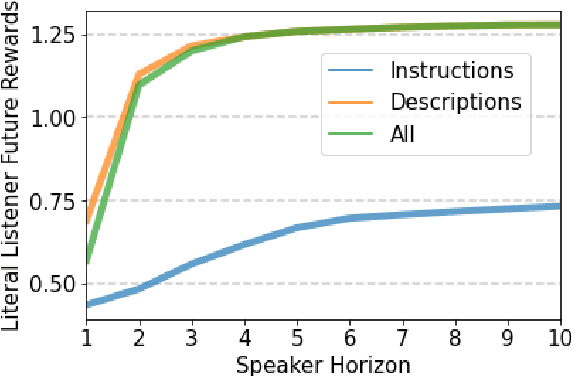
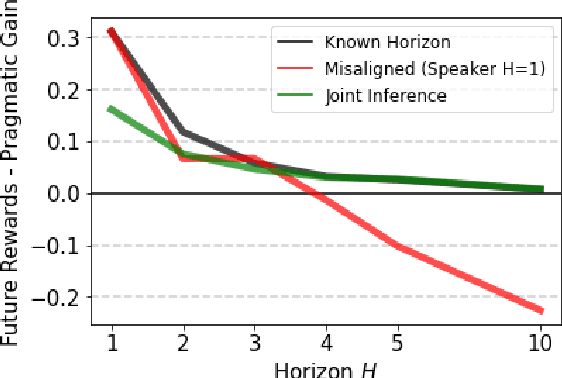
Natural language is an intuitive and expressive way to communicate reward information to autonomous agents. It encompasses everything from concrete instructions to abstract descriptions of the world. Despite this, natural language is often challenging to learn from: it is difficult for machine learning methods to make appropriate inferences from such a wide range of input. This paper proposes a generalization of reward design as a unifying principle to ground linguistic communication: speakers choose utterances to maximize expected rewards from the listener's future behaviors. We first extend reward design to incorporate reasoning about unknown future states in a linear bandit setting. We then define a speaker model which chooses utterances according to this objective. Simulations show that short-horizon speakers (reasoning primarily about a single, known state) tend to use instructions, while long-horizon speakers (reasoning primarily about unknown, future states) tend to describe the reward function. We then define a pragmatic listener which performs inverse reward design by jointly inferring the speaker's latent horizon and rewards. Our findings suggest that this extension of reward design to linguistic communication, including the notion of a latent speaker horizon, is a promising direction for achieving more robust alignment outcomes from natural language supervision.
Guided Imitation of Task and Motion Planning
Dec 06, 2021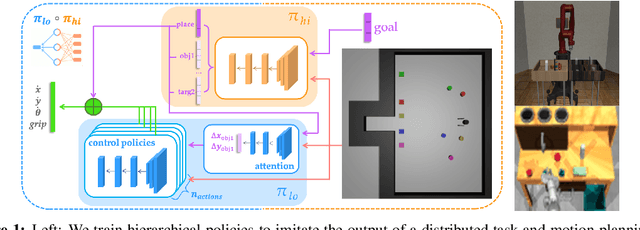
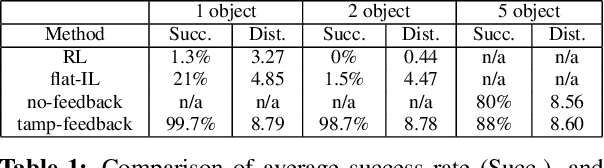
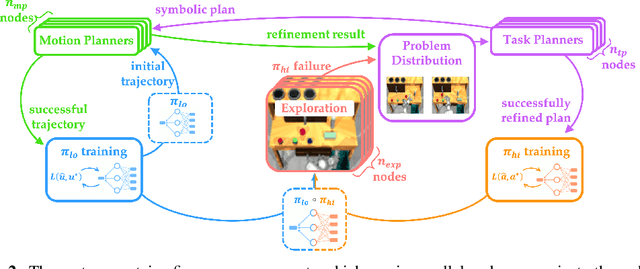
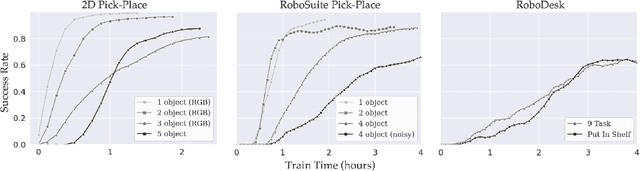
While modern policy optimization methods can do complex manipulation from sensory data, they struggle on problems with extended time horizons and multiple sub-goals. On the other hand, task and motion planning (TAMP) methods scale to long horizons but they are computationally expensive and need to precisely track world state. We propose a method that draws on the strength of both methods: we train a policy to imitate a TAMP solver's output. This produces a feed-forward policy that can accomplish multi-step tasks from sensory data. First, we build an asynchronous distributed TAMP solver that can produce supervision data fast enough for imitation learning. Then, we propose a hierarchical policy architecture that lets us use partially trained control policies to speed up the TAMP solver. In robotic manipulation tasks with 7-DoF joint control, the partially trained policies reduce the time needed for planning by a factor of up to 2.6. Among these tasks, we can learn a policy that solves the RoboSuite 4-object pick-place task 88% of the time from object pose observations and a policy that solves the RoboDesk 9-goal benchmark 79% of the time from RGB images (averaged across the 9 disparate tasks).
What are you optimizing for? Aligning Recommender Systems with Human Values
Jul 22, 2021We describe cases where real recommender systems were modified in the service of various human values such as diversity, fairness, well-being, time well spent, and factual accuracy. From this we identify the current practice of values engineering: the creation of classifiers from human-created data with value-based labels. This has worked in practice for a variety of issues, but problems are addressed one at a time, and users and other stakeholders have seldom been involved. Instead, we look to AI alignment work for approaches that could learn complex values directly from stakeholders, and identify four major directions: useful measures of alignment, participatory design and operation, interactive value learning, and informed deliberative judgments.
Consequences of Misaligned AI
Feb 07, 2021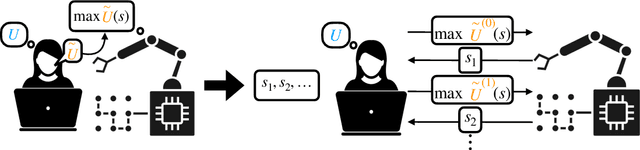
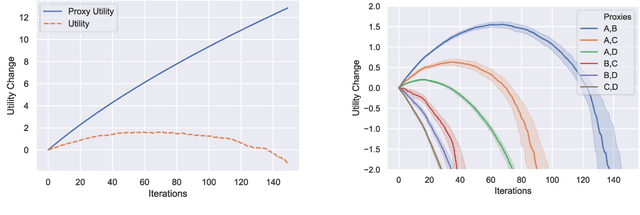
AI systems often rely on two key components: a specified goal or reward function and an optimization algorithm to compute the optimal behavior for that goal. This approach is intended to provide value for a principal: the user on whose behalf the agent acts. The objectives given to these agents often refer to a partial specification of the principal's goals. We consider the cost of this incompleteness by analyzing a model of a principal and an agent in a resource constrained world where the $L$ attributes of the state correspond to different sources of utility for the principal. We assume that the reward function given to the agent only has support on $J < L$ attributes. The contributions of our paper are as follows: 1) we propose a novel model of an incomplete principal-agent problem from artificial intelligence; 2) we provide necessary and sufficient conditions under which indefinitely optimizing for any incomplete proxy objective leads to arbitrarily low overall utility; and 3) we show how modifying the setup to allow reward functions that reference the full state or allowing the principal to update the proxy objective over time can lead to higher utility solutions. The results in this paper argue that we should view the design of reward functions as an interactive and dynamic process and identifies a theoretical scenario where some degree of interactivity is desirable.