 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuroMapper: In-browser Visualizer for Neural Network Training
Oct 22, 2022
We present our ongoing work NeuroMapper, an in-browser visualization tool that helps machine learning (ML) developers interpret the evolution of a model during training, providing a new way to monitor the training process and visually discover reasons for suboptimal training. While most existing deep neural networks (DNNs) interpretation tools are designed for already-trained model, NeuroMapper scalably visualizes the evolution of the embeddings of a model's blocks across training epochs, enabling real-time visualization of 40,000 embedded points. To promote the embedding visualizations' spatial coherence across epochs, NeuroMapper adapts AlignedUMAP, a recent nonlinear dimensionality reduction technique to align the embeddings. With NeuroMapper, users can explore the training dynamics of a Resnet-50 model, and adjust the embedding visualizations' parameters in real time. NeuroMapper is open-sourced at https://github.com/poloclub/NeuroMapper and runs in all modern web browsers. A demo of the tool in action is available at: https://poloclub.github.io/NeuroMapper/.
IMB-NAS: Neural Architecture Search for Imbalanced Datasets
Sep 30, 2022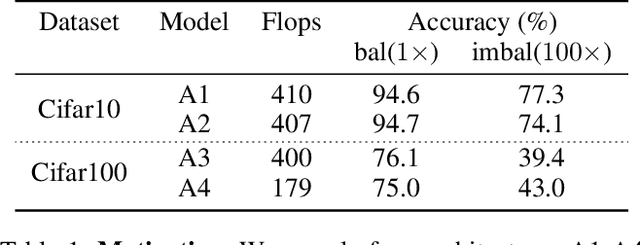
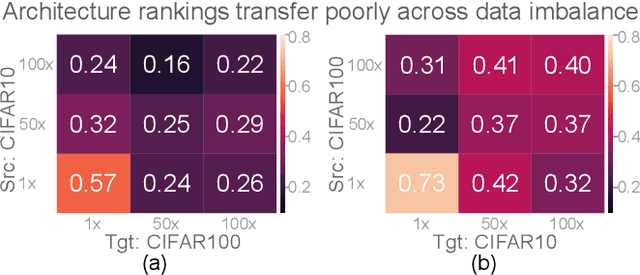

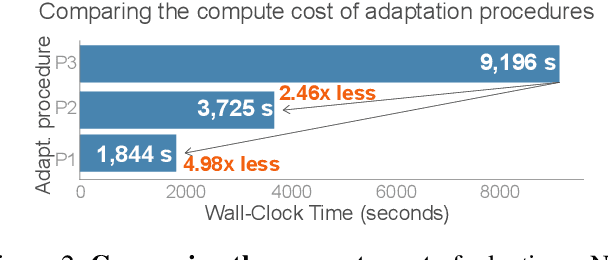
Class imbalance is a ubiquitous phenomenon occurring in real world data distributions. To overcome its detrimental effect on training accurate classifiers, existing work follows three major directions: class re-balancing, information transfer, and representation learning. In this paper, we propose a new and complementary direction for improving performance on long tailed datasets - optimizing the backbone architecture through neural architecture search (NAS). We find that an architecture's accuracy obtained on a balanced dataset is not indicative of good performance on imbalanced ones. This poses the need for a full NAS run on long tailed datasets which can quickly become prohibitively compute intensive. To alleviate this compute burden, we aim to efficiently adapt a NAS super-network from a balanced source dataset to an imbalanced target one. Among several adaptation strategies, we find that the most effective one is to retrain the linear classification head with reweighted loss, while freezing the backbone NAS super-network trained on a balanced source dataset. We perform extensive experiments on multiple datasets and provide concrete insights to optimize architectures for long tailed datasets.
TimberTrek: Exploring and Curating Sparse Decision Trees with Interactive Visualization
Sep 19, 2022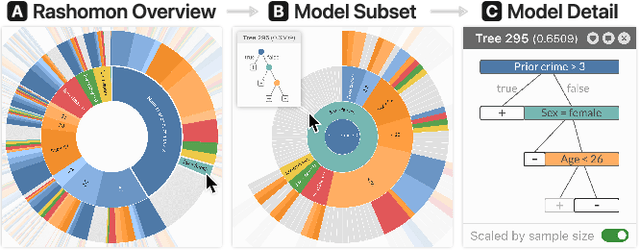
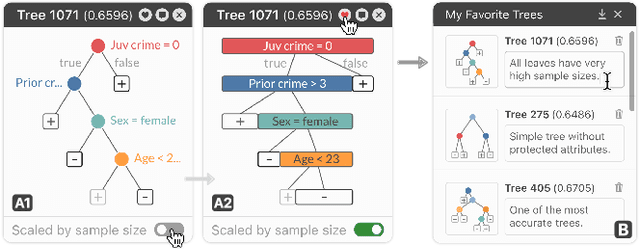
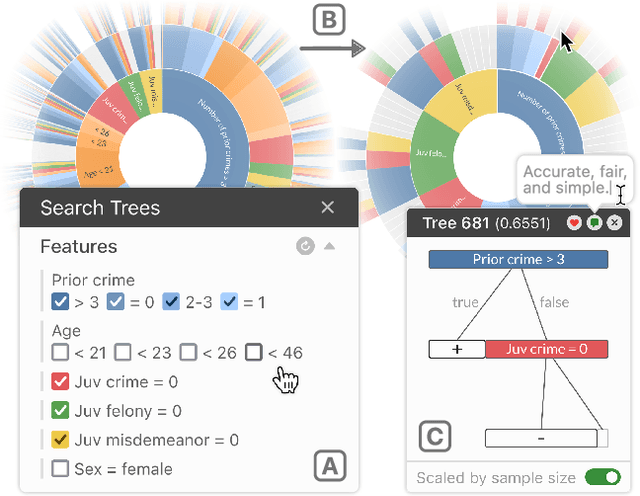
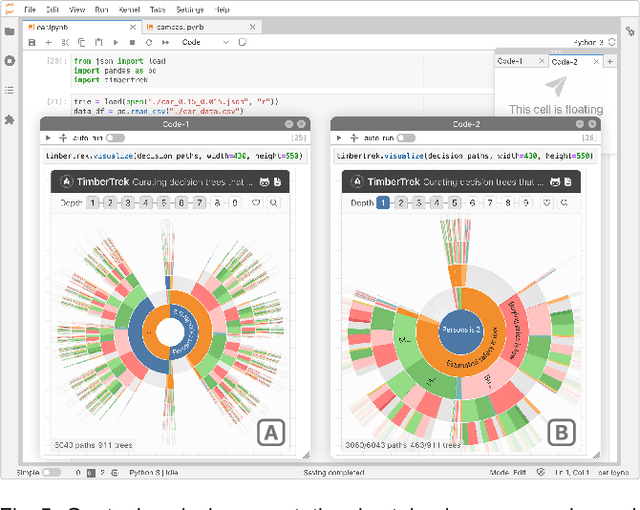
Given thousands of equally accurate machine learning (ML) models, how can users choose among them? A recent ML technique enables domain experts and data scientists to generate a complete Rashomon set for sparse decision trees--a huge set of almost-optimal interpretable ML models. To help ML practitioners identify models with desirable properties from this Rashomon set, we develop TimberTrek, the first interactive visualization system that summarizes thousands of sparse decision trees at scale. Two usage scenarios highlight how TimberTrek can empower users to easily explore, compare, and curate models that align with their domain knowledge and values. Our open-source tool runs directly in users' computational notebooks and web browsers, lowering the barrier to creating more responsible ML models. TimberTrek is available at the following public demo link: https://poloclub.github.io/timbertrek.
Interpretability, Then What? Editing Machine Learning Models to Reflect Human Knowledge and Values
Jun 30, 2022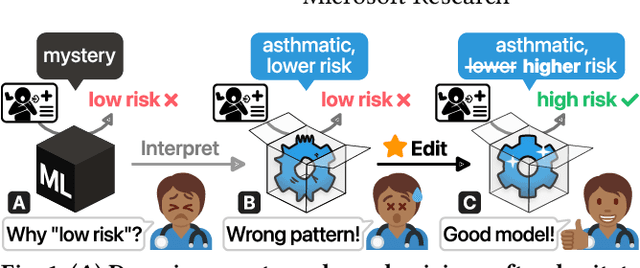
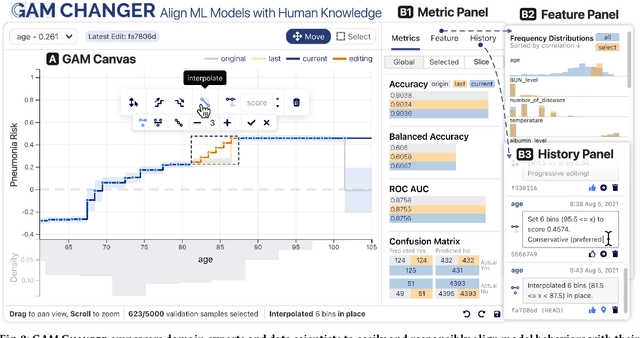
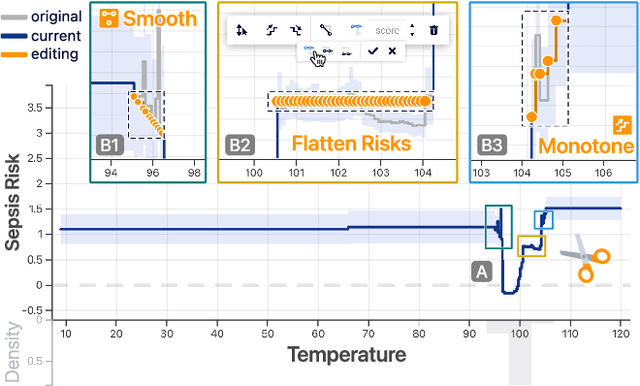
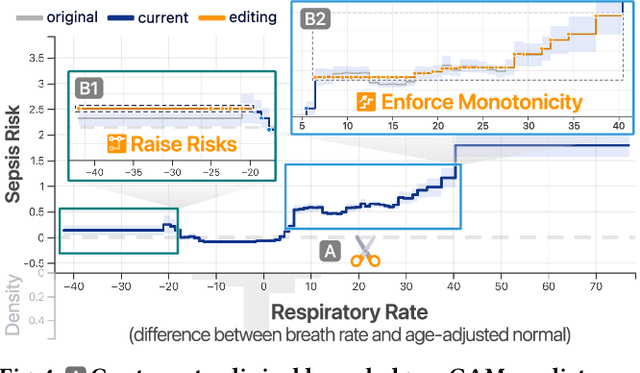
Machine learning (ML) interpretability techniques can reveal undesirable patterns in data that models exploit to make predictions--potentially causing harms once deployed. However, how to take action to address these patterns is not always clear. In a collaboration between ML and human-computer interaction researchers, physicians, and data scientists, we develop GAM Changer, the first interactive system to help domain experts and data scientists easily and responsibly edit Generalized Additive Models (GAMs) and fix problematic patterns. With novel interaction techniques, our tool puts interpretability into action--empowering users to analyze, validate, and align model behaviors with their knowledge and values. Physicians have started to use our tool to investigate and fix pneumonia and sepsis risk prediction models, and an evaluation with 7 data scientists working in diverse domains highlights that our tool is easy to use, meets their model editing needs, and fits into their current workflows. Built with modern web technologies, our tool runs locally in users' web browsers or computational notebooks, lowering the barrier to use. GAM Changer is available at the following public demo link: https://interpret.ml/gam-changer.
Visual Auditor: Interactive Visualization for Detection and Summarization of Model Biases
Jun 25, 2022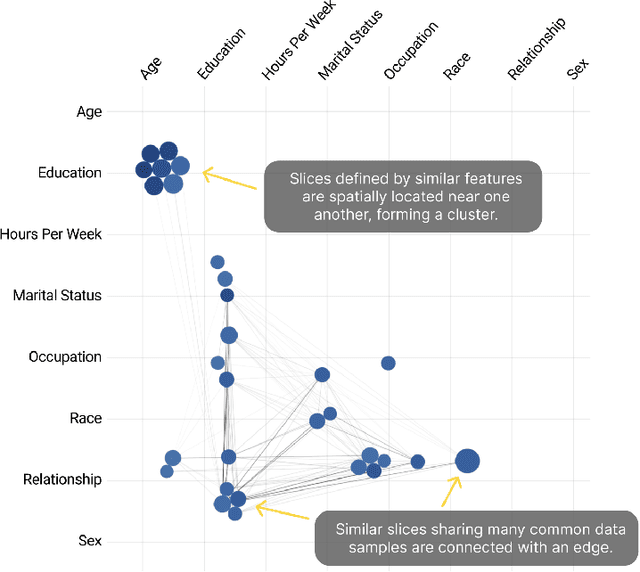

As machine learning (ML) systems become increasingly widespread, it is necessary to audit these systems for biases prior to their deployment. Recent research has developed algorithms for effectively identifying intersectional bias in the form of interpretable, underperforming subsets (or slices) of the data. However, these solutions and their insights are limited without a tool for visually understanding and interacting with the results of these algorithms. We propose Visual Auditor, an interactive visualization tool for auditing and summarizing model biases. Visual Auditor assists model validation by providing an interpretable overview of intersectional bias (bias that is present when examining populations defined by multiple features), details about relationships between problematic data slices, and a comparison between underperforming and overperforming data slices in a model. Our open-source tool runs directly in both computational notebooks and web browsers, making model auditing accessible and easily integrated into current ML development workflows. An observational user study in collaboration with domain experts at Fiddler AI highlights that our tool can help ML practitioners identify and understand model biases.
VisCUIT: Visual Auditor for Bias in CNN Image Classifier
Apr 13, 2022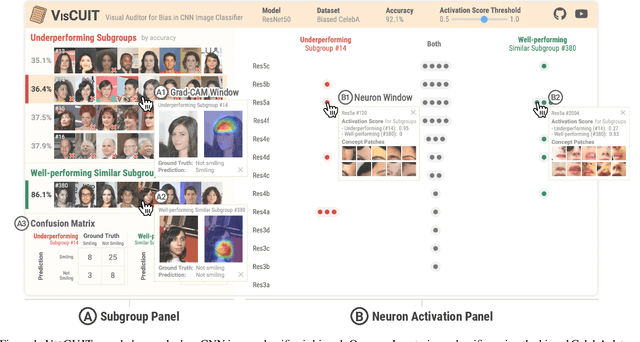

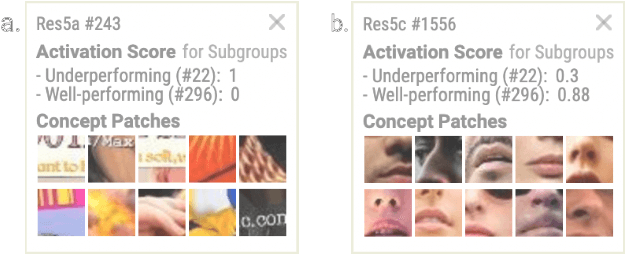

CNN image classifiers are widely used, thanks to their efficiency and accuracy. However, they can suffer from biases that impede their practical applications. Most existing bias investigation techniques are either inapplicable to general image classification tasks or require significant user efforts in perusing all data subgroups to manually specify which data attributes to inspect. We present VisCUIT, an interactive visualization system that reveals how and why a CNN classifier is biased. VisCUIT visually summarizes the subgroups on which the classifier underperforms and helps users discover and characterize the cause of the underperformances by revealing image concepts responsible for activating neurons that contribute to misclassifications. VisCUIT runs in modern browsers and is open-source, allowing people to easily access and extend the tool to other model architectures and datasets. VisCUIT is available at the following public demo link: https://poloclub.github.io/VisCUIT. A video demo is available at https://youtu.be/eNDbSyM4R_4.
Hear No Evil: Towards Adversarial Robustness of Automatic Speech Recognition via Multi-Task Learning
Apr 05, 2022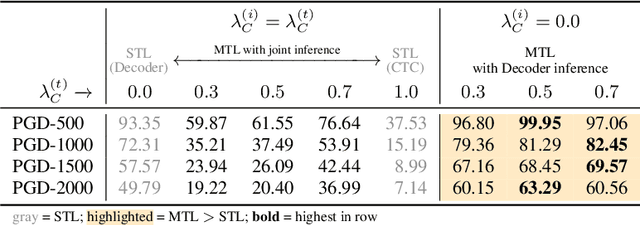
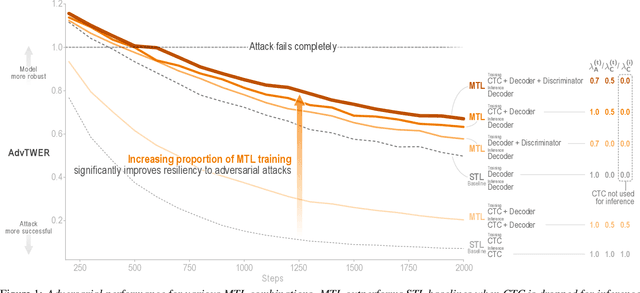
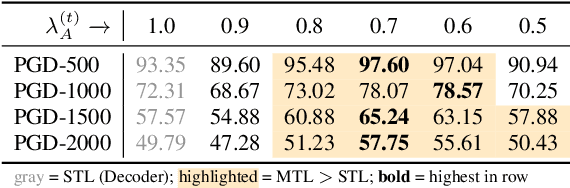
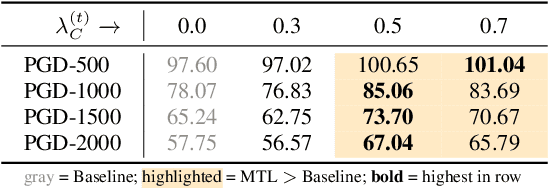
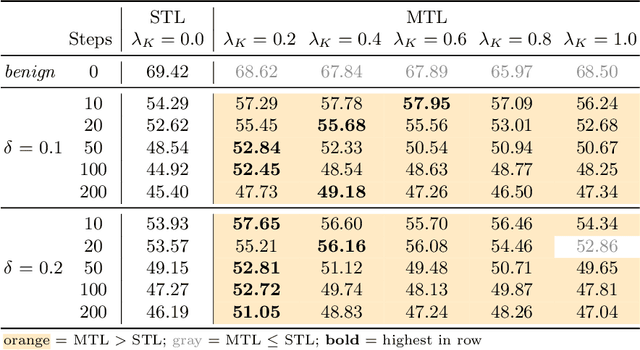
As automatic speech recognition (ASR) systems are now being widely deployed in the wild, the increasing threat of adversarial attacks raises serious questions about the security and reliability of using such systems. On the other hand, multi-task learning (MTL) has shown success in training models that can resist adversarial attacks in the computer vision domain. In this work, we investigate the impact of performing such multi-task learning on the adversarial robustness of ASR models in the speech domain. We conduct extensive MTL experimentation by combining semantically diverse tasks such as accent classification and ASR, and evaluate a wide range of adversarial settings. Our thorough analysis reveals that performing MTL with semantically diverse tasks consistently makes it harder for an adversarial attack to succeed. We also discuss in detail the serious pitfalls and their related remedies that have a significant impact on the robustness of MTL models. Our proposed MTL approach shows considerable absolute improvements in adversarially targeted WER ranging from 17.25 up to 59.90 compared to single-task learning baselines (attention decoder and CTC respectively). Ours is the first in-depth study that uncovers adversarial robustness gains from multi-task learning for ASR.
SkeleVision: Towards Adversarial Resiliency of Person Tracking with Multi-Task Learning
Apr 02, 2022
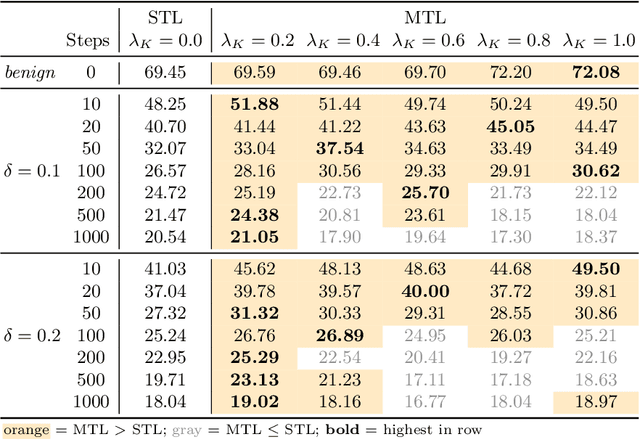
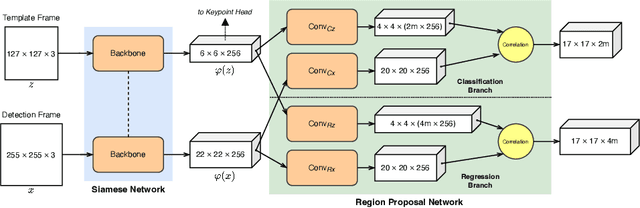
Person tracking using computer vision techniques has wide ranging applications such as autonomous driving, home security and sports analytics. However, the growing threat of adversarial attacks raises serious concerns regarding the security and reliability of such techniques. In this work, we study the impact of multi-task learning (MTL) on the adversarial robustness of the widely used SiamRPN tracker, in the context of person tracking. Specifically, we investigate the effect of jointly learning with semantically analogous tasks of person tracking and human keypoint detection. We conduct extensive experiments with more powerful adversarial attacks that can be physically realizable, demonstrating the practical value of our approach. Our empirical study with simulated as well as real-world datasets reveals that training with MTL consistently makes it harder to attack the SiamRPN tracker, compared to typically training only on the single task of person tracking.
ConceptEvo: Interpreting Concept Evolution in Deep Learning Training
Mar 30, 2022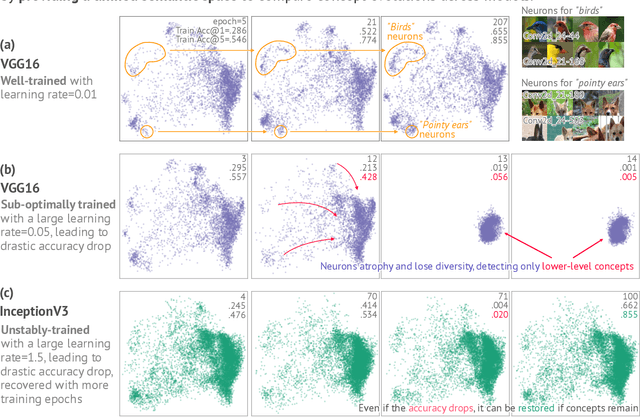


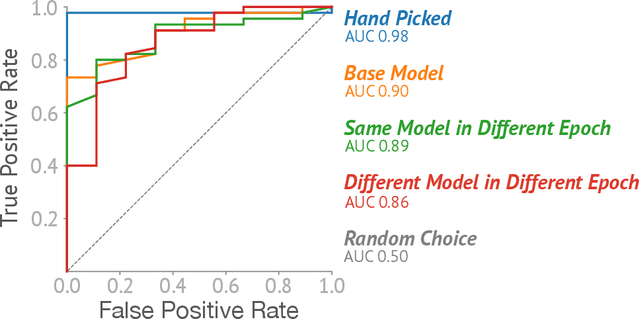
Deep neural networks (DNNs) have been widely used for decision making, prompting a surge of interest in interpreting how these complex models work. Recent literature on DNN interpretation has revolved around already-trained models; however, much less research focuses on interpreting how the models evolve as they are trained. Interpreting model evolution is crucial to monitor network training and can aid proactive decisions about necessary interventions. In this work, we present ConceptEvo, a general interpretation framework for DNNs that reveals the inception and evolution of detected concepts during training. Through a large-scale human evaluation with 260 participants and quantitative experiments, we show that ConceptEvo discovers evolution across different models that are meaningful to humans, helpful for early-training intervention decisions, and crucial to the prediction for a given class.
GAM Changer: Editing Generalized Additive Models with Interactive Visualization
Dec 06, 2021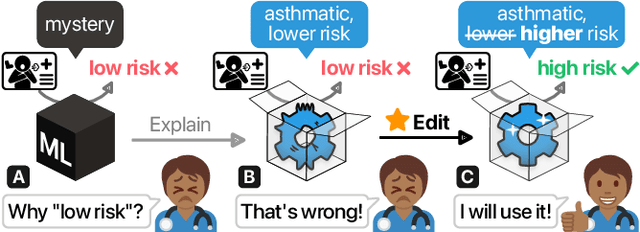

Recent strides in interpretable machine learning (ML) research reveal that models exploit undesirable patterns in the data to make predictions, which potentially causes harms in deployment. However, it is unclear how we can fix these models. We present our ongoing work, GAM Changer, an open-source interactive system to help data scientists and domain experts easily and responsibly edit their Generalized Additive Models (GAMs). With novel visualization techniques, our tool puts interpretability into action -- empowering human users to analyze, validate, and align model behaviors with their knowledge and values. Built using modern web technologies, our tool runs locally in users' computational notebooks or web browsers without requiring extra compute resources, lowering the barrier to creating more responsible ML models. GAM Changer is available at https://interpret.ml/gam-changer.