 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM Self Defense: By Self Examination, LLMs Know They Are Being Tricked
Aug 15, 2023



Large language models (LLMs) have skyrocketed in popularity in recent years due to their ability to generate high-quality text in response to human prompting. However, these models have been shown to have the potential to generate harmful content in response to user prompting (e.g., giving users instructions on how to commit crimes). There has been a focus in the literature on mitigating these risks, through methods like aligning models with human values through reinforcement learning. However, it has been shown that even aligned language models are susceptible to adversarial attacks that bypass their restrictions on generating harmful text. We propose a simple approach to defending against these attacks by having a large language model filter its own responses. Our current results show that even if a model is not fine-tuned to be aligned with human values, it is possible to stop it from presenting harmful content to users by validating the content using a language model.
WizMap: Scalable Interactive Visualization for Exploring Large Machine Learning Embeddings
Jun 15, 2023
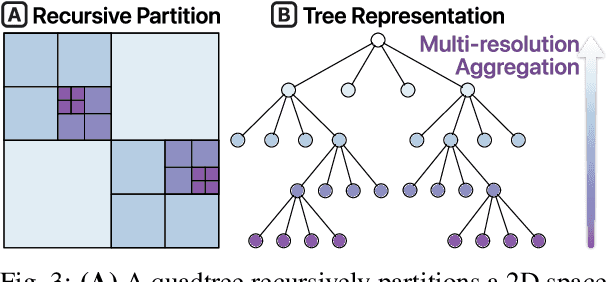
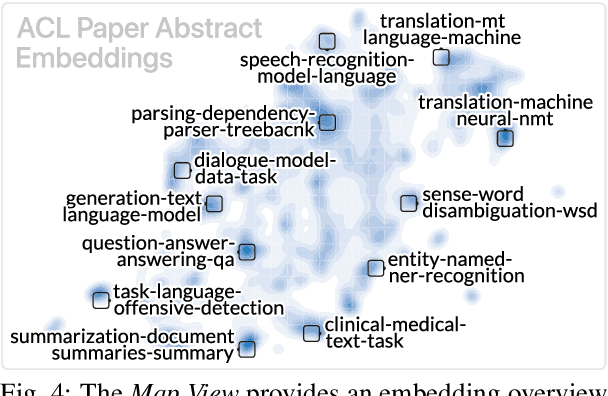

Machine learning models often learn latent embedding representations that capture the domain semantics of their training data. These embedding representations are valuable for interpreting trained models, building new models, and analyzing new datasets. However, interpreting and using embeddings can be challenging due to their opaqueness, high dimensionality, and the large size of modern datasets. To tackle these challenges, we present WizMap, an interactive visualization tool to help researchers and practitioners easily explore large embeddings. With a novel multi-resolution embedding summarization method and a familiar map-like interaction design, WizMap enables users to navigate and interpret embedding spaces with ease. Leveraging modern web technologies such as WebGL and Web Workers, WizMap scales to millions of embedding points directly in users' web browsers and computational notebooks without the need for dedicated backend servers. WizMap is open-source and available at the following public demo link: https://poloclub.github.io/wizmap.
Diffusion Explainer: Visual Explanation for Text-to-image Stable Diffusion
May 08, 2023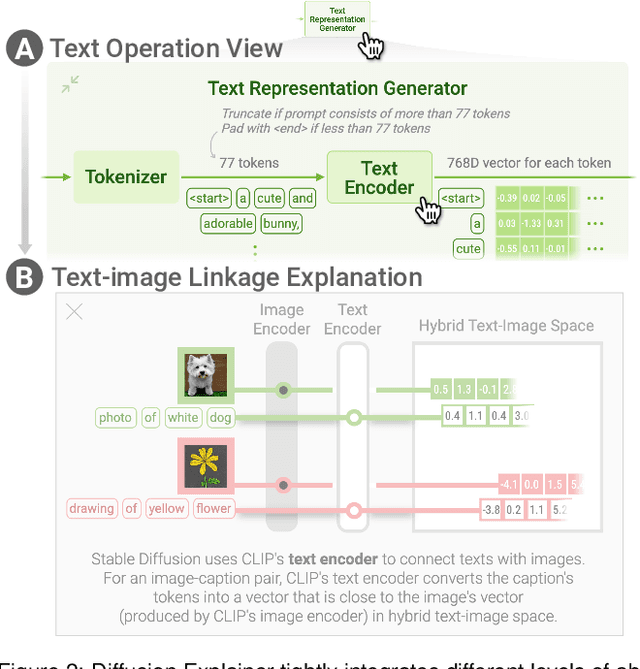
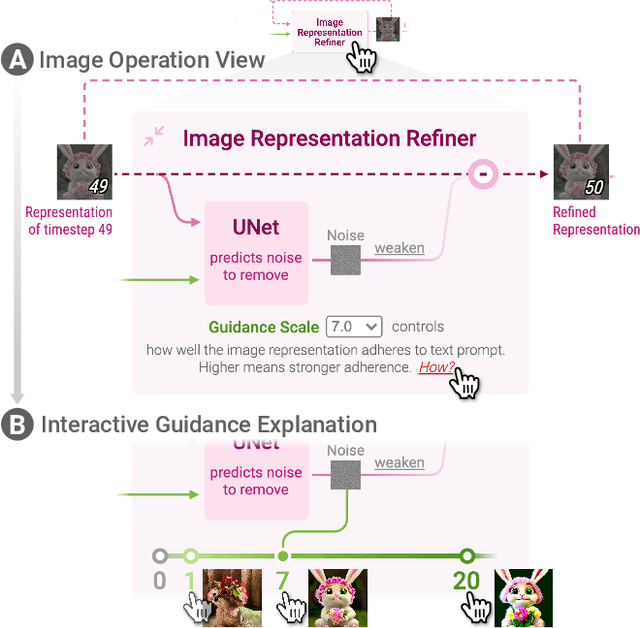
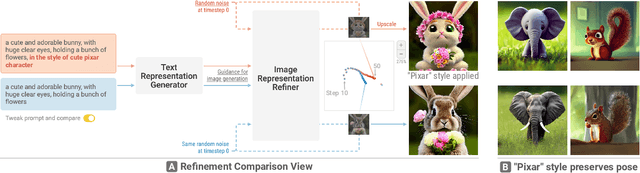
Diffusion-based generative models' impressive ability to create convincing images has captured global attention. However, their complex internal structures and operations often make them difficult for non-experts to understand. We present Diffusion Explainer, the first interactive visualization tool that explains how Stable Diffusion transforms text prompts into images. Diffusion Explainer tightly integrates a visual overview of Stable Diffusion's complex components with detailed explanations of their underlying operations, enabling users to fluidly transition between multiple levels of abstraction through animations and interactive elements. By comparing the evolutions of image representations guided by two related text prompts over refinement timesteps, users can discover the impact of prompts on image generation. Diffusion Explainer runs locally in users' web browsers without the need for installation or specialized hardware, broadening the public's education access to modern AI techniques. Our open-sourced tool is available at: https://poloclub.github.io/diffusion-explainer/. A video demo is available at https://youtu.be/Zg4gxdIWDds.
SuperNOVA: Design Strategies and Opportunities for Interactive Visualization in Computational Notebooks
May 04, 2023


Computational notebooks such as Jupyter Notebook have become data scientists' de facto programming environments. Many visualization researchers and practitioners have developed interactive visualization tools that support notebooks. However, little is known about the appropriate design of visual analytics (VA) tools in notebooks. To bridge this critical research gap, we investigate the design strategies in this space by analyzing 159 notebook VA tools and their users' feedback. Our analysis encompasses 62 systems from academic papers and 103 systems sourced from a pool of 55k notebooks containing interactive visualizations that we obtain via scraping 8.6 million notebooks on GitHub. We also examine findings from 15 user studies and user feedback in 379 GitHub issues. Through this work, we identify unique design opportunities and considerations for future notebook VA tools, such as using and manipulating multimodal data in notebooks as well as balancing the degree of visualization-notebook integration. Finally, we develop SuperNOVA, an open-source interactive tool to help researchers explore existing notebook VA tools and search for related work.
WebSHAP: Towards Explaining Any Machine Learning Models Anywhere
Mar 16, 2023As machine learning (ML) is increasingly integrated into our everyday Web experience, there is a call for transparent and explainable web-based ML. However, existing explainability techniques often require dedicated backend servers, which limit their usefulness as the Web community moves toward in-browser ML for lower latency and greater privacy. To address the pressing need for a client-side explainability solution, we present WebSHAP, the first in-browser tool that adapts the state-of-the-art model-agnostic explainability technique SHAP to the Web environment. Our open-source tool is developed with modern Web technologies such as WebGL that leverage client-side hardware capabilities and make it easy to integrate into existing Web ML applications. We demonstrate WebSHAP in a usage scenario of explaining ML-based loan approval decisions to loan applicants. Reflecting on our work, we discuss the opportunities and challenges for future research on transparent Web ML. WebSHAP is available at https://github.com/poloclub/webshap.
GAM Coach: Towards Interactive and User-centered Algorithmic Recourse
Mar 01, 2023



Machine learning (ML) recourse techniques are increasingly used in high-stakes domains, providing end users with actions to alter ML predictions, but they assume ML developers understand what input variables can be changed. However, a recourse plan's actionability is subjective and unlikely to match developers' expectations completely. We present GAM Coach, a novel open-source system that adapts integer linear programming to generate customizable counterfactual explanations for Generalized Additive Models (GAMs), and leverages interactive visualizations to enable end users to iteratively generate recourse plans meeting their needs. A quantitative user study with 41 participants shows our tool is usable and useful, and users prefer personalized recourse plans over generic plans. Through a log analysis, we explore how users discover satisfactory recourse plans, and provide empirical evidence that transparency can lead to more opportunities for everyday users to discover counterintuitive patterns in ML models. GAM Coach is available at: https://poloclub.github.io/gam-coach/.
Energy Transformer
Feb 14, 2023



Transformers have become the de facto models of choice in machine learning, typically leading to impressive performance on many applications. At the same time, the architectural development in the transformer world is mostly driven by empirical findings, and the theoretical understanding of their architectural building blocks is rather limited. In contrast, Dense Associative Memory models or Modern Hopfield Networks have a well-established theoretical foundation, but have not yet demonstrated truly impressive practical results. We propose a transformer architecture that replaces the sequence of feedforward transformer blocks with a single large Associative Memory model. Our novel architecture, called Energy Transformer (or ET for short), has many of the familiar architectural primitives that are often used in the current generation of transformers. However, it is not identical to the existing architectures. The sequence of transformer layers in ET is purposely designed to minimize a specifically engineered energy function, which is responsible for representing the relationships between the tokens. As a consequence of this computational principle, the attention in ET is different from the conventional attention mechanism. In this work, we introduce the theoretical foundations of ET, explore it's empirical capabilities using the image completion task, and obtain strong quantitative results on the graph anomaly detection task.
Lessons from the Development of an Anomaly Detection Interface on the Mars Perseverance Rover using the ISHMAP Framework
Feb 14, 2023



While anomaly detection stands among the most important and valuable problems across many scientific domains, anomaly detection research often focuses on AI methods that can lack the nuance and interpretability so critical to conducting scientific inquiry. In this application paper we present the results of utilizing an alternative approach that situates the mathematical framing of machine learning based anomaly detection within a participatory design framework. In a collaboration with NASA scientists working with the PIXL instrument studying Martian planetary geochemistry as a part of the search for extra-terrestrial life; we report on over 18 months of in-context user research and co-design to define the key problems NASA scientists face when looking to detect and interpret spectral anomalies. We address these problems and develop a novel spectral anomaly detection toolkit for PIXL scientists that is highly accurate while maintaining strong transparency to scientific interpretation. We also describe outcomes from a yearlong field deployment of the algorithm and associated interface. Finally we introduce a new design framework which we developed through the course of this collaboration for co-creating anomaly detection algorithms: Iterative Semantic Heuristic Modeling of Anomalous Phenomena (ISHMAP), which provides a process for scientists and researchers to produce natively interpretable anomaly detection models. This work showcases an example of successfully bridging methodologies from AI and HCI within a scientific domain, and provides a resource in ISHMAP which may be used by other researchers and practitioners looking to partner with other scientific teams to achieve better science through more effective and interpretable anomaly detection tools.
RobArch: Designing Robust Architectures against Adversarial Attacks
Jan 08, 2023



Adversarial Training is the most effective approach for improving the robustness of Deep Neural Networks (DNNs). However, compared to the large body of research in optimizing the adversarial training process, there are few investigations into how architecture components affect robustness, and they rarely constrain model capacity. Thus, it is unclear where robustness precisely comes from. In this work, we present the first large-scale systematic study on the robustness of DNN architecture components under fixed parameter budgets. Through our investigation, we distill 18 actionable robust network design guidelines that empower model developers to gain deep insights. We demonstrate these guidelines' effectiveness by introducing the novel Robust Architecture (RobArch) model that instantiates the guidelines to build a family of top-performing models across parameter capacities against strong adversarial attacks. RobArch achieves the new state-of-the-art AutoAttack accuracy on the RobustBench ImageNet leaderboard. The code is available at $\href{https://github.com/ShengYun-Peng/RobArch}{\text{this url}}$.
DiffusionDB: A Large-scale Prompt Gallery Dataset for Text-to-Image Generative Models
Nov 15, 2022With recent advancements in diffusion models, users can generate high-quality images by writing text prompts in natural language. However, generating images with desired details requires proper prompts, and it is often unclear how a model reacts to different prompts and what the best prompts are. To help researchers tackle these critical challenges, we introduce DiffusionDB, the first large-scale text-to-image prompt dataset. DiffusionDB contains 14 million images generated by Stable Diffusion using prompts and hyperparameters specified by real users. We analyze prompts in the dataset and discuss key properties of these prompts. The unprecedented scale and diversity of this human-actuated dataset provide exciting research opportunities in understanding the interplay between prompts and generative models, detecting deepfakes, and designing human-AI interaction tools to help users more easily use these models. DiffusionDB is publicly available at: https://poloclub.github.io/diffusiondb.