 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmergent Linguistic Phenomena in Multi-Agent Communication Games
Jan 25, 2019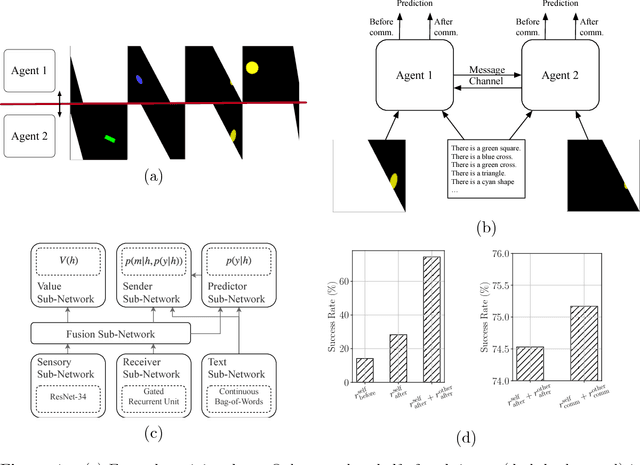
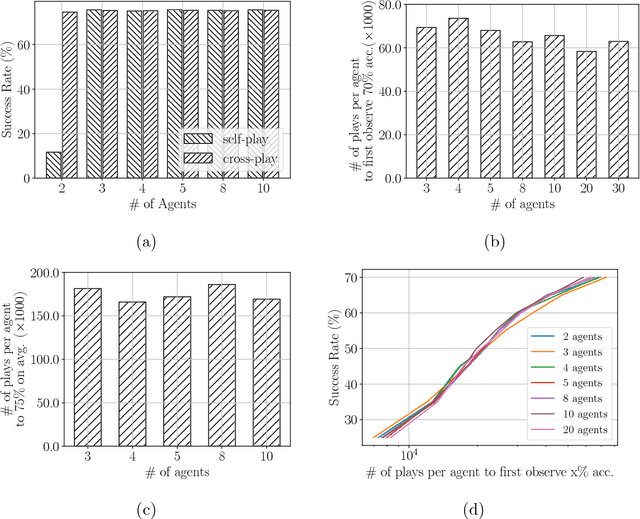
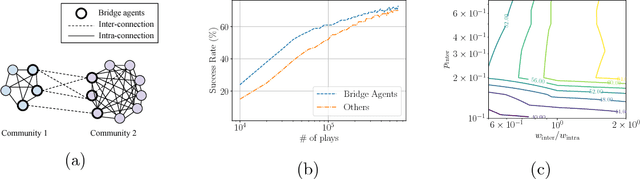
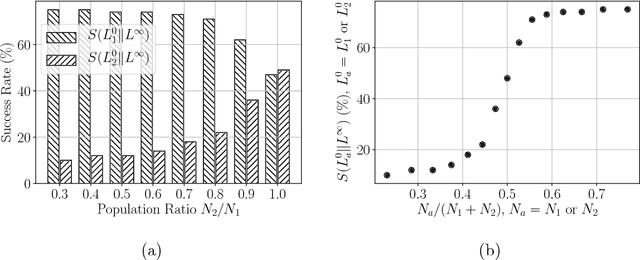
In this work, we propose a computational framework in which agents equipped with communication capabilities simultaneously play a series of referential games, where agents are trained using deep reinforcement learning. We demonstrate that the framework mirrors linguistic phenomena observed in natural language: i) the outcome of contact between communities is a function of inter- and intra-group connectivity; ii) linguistic contact either converges to the majority protocol, or in balanced cases leads to novel creole languages of lower complexity; and iii) a linguistic continuum emerges where neighboring languages are more mutually intelligible than farther removed languages. We conclude that intricate properties of language evolution need not depend on complex evolved linguistic capabilities, but can emerge from simple social exchanges between perceptually-enabled agents playing communication games.
Personalizing Dialogue Agents: I have a dog, do you have pets too?
Sep 25, 2018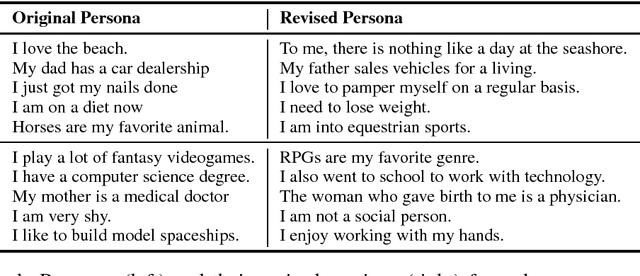

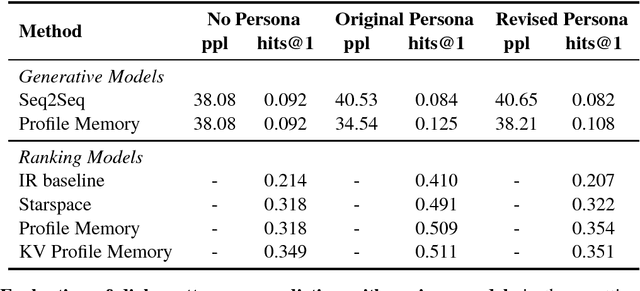
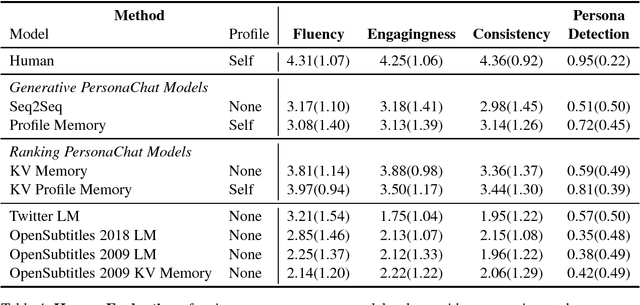
Chit-chat models are known to have several problems: they lack specificity, do not display a consistent personality and are often not very captivating. In this work we present the task of making chit-chat more engaging by conditioning on profile information. We collect data and train models to (i) condition on their given profile information; and (ii) information about the person they are talking to, resulting in improved dialogues, as measured by next utterance prediction. Since (ii) is initially unknown our model is trained to engage its partner with personal topics, and we show the resulting dialogue can be used to predict profile information about the interlocutors.
Jump to better conclusions: SCAN both left and right
Sep 12, 2018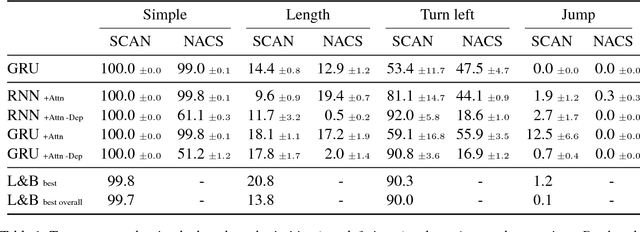
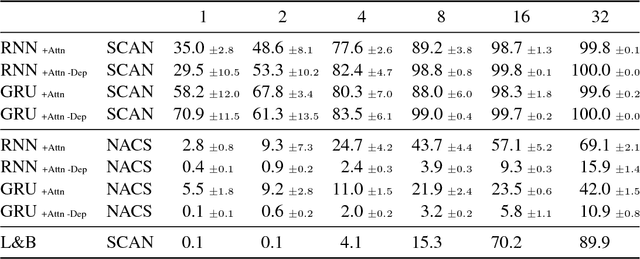

Lake and Baroni (2018) recently introduced the SCAN data set, which consists of simple commands paired with action sequences and is intended to test the strong generalization abilities of recurrent sequence-to-sequence models. Their initial experiments suggested that such models may fail because they lack the ability to extract systematic rules. Here, we take a closer look at SCAN and show that it does not always capture the kind of generalization that it was designed for. To mitigate this we propose a complementary dataset, which requires mapping actions back to the original commands, called NACS. We show that models that do well on SCAN do not necessarily do well on NACS, and that NACS exhibits properties more closely aligned with realistic use-cases for sequence-to-sequence models.
Dynamic Meta-Embeddings for Improved Sentence Representations
Sep 05, 2018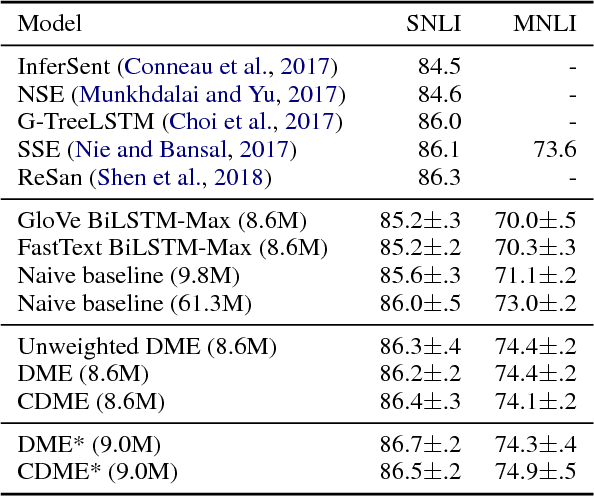

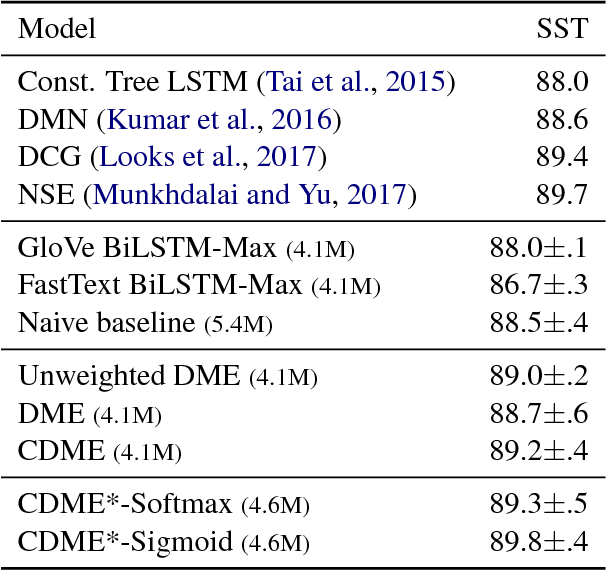
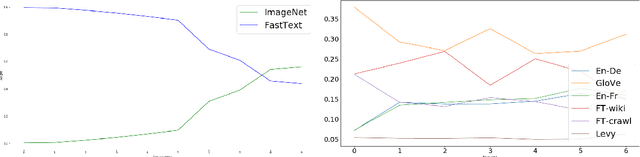
While one of the first steps in many NLP systems is selecting what pre-trained word embeddings to use, we argue that such a step is better left for neural networks to figure out by themselves. To that end, we introduce dynamic meta-embeddings, a simple yet effective method for the supervised learning of embedding ensembles, which leads to state-of-the-art performance within the same model class on a variety of tasks. We subsequently show how the technique can be used to shed new light on the usage of word embeddings in NLP systems.
Talk the Walk: Navigating New York City through Grounded Dialogue
Jul 13, 2018
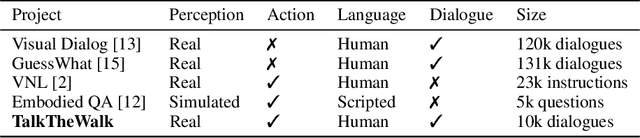
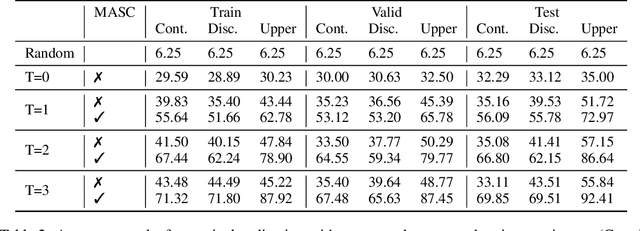
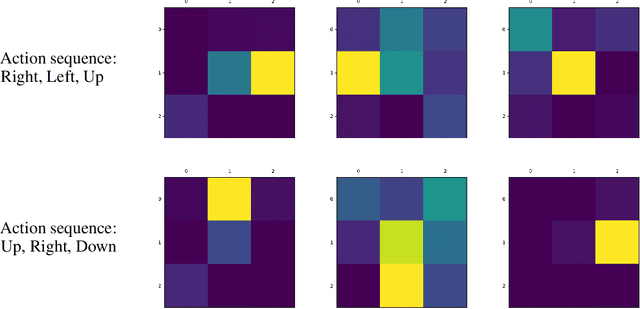
We introduce "Talk The Walk", the first large-scale dialogue dataset grounded in action and perception. The task involves two agents (a "guide" and a "tourist") that communicate via natural language in order to achieve a common goal: having the tourist navigate to a given target location. The task and dataset, which are described in detail, are challenging and their full solution is an open problem that we pose to the community. We (i) focus on the task of tourist localization and develop the novel Masked Attention for Spatial Convolutions (MASC) mechanism that allows for grounding tourist utterances into the guide's map, (ii) show it yields significant improvements for both emergent and natural language communication, and (iii) using this method, we establish non-trivial baselines on the full task.
Supervised Learning of Universal Sentence Representations from Natural Language Inference Data
Jul 08, 2018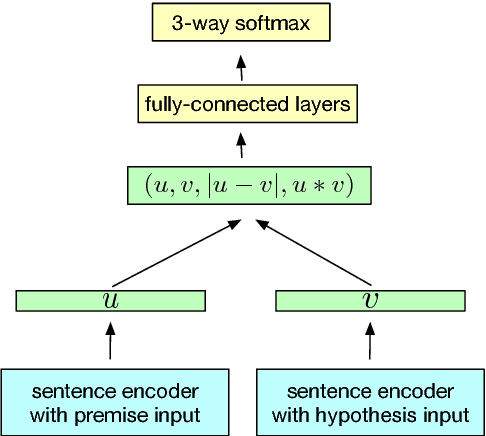

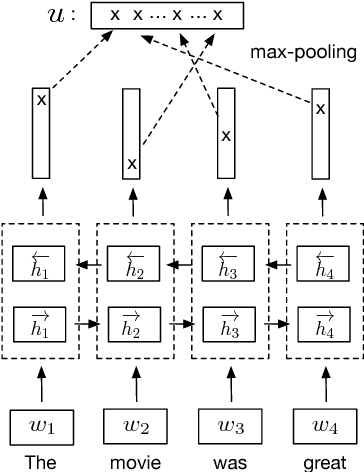

Many modern NLP systems rely on word embeddings, previously trained in an unsupervised manner on large corpora, as base features. Efforts to obtain embeddings for larger chunks of text, such as sentences, have however not been so successful. Several attempts at learning unsupervised representations of sentences have not reached satisfactory enough performance to be widely adopted. In this paper, we show how universal sentence representations trained using the supervised data of the Stanford Natural Language Inference datasets can consistently outperform unsupervised methods like SkipThought vectors on a wide range of transfer tasks. Much like how computer vision uses ImageNet to obtain features, which can then be transferred to other tasks, our work tends to indicate the suitability of natural language inference for transfer learning to other NLP tasks. Our encoder is publicly available.
Learning Continuous Hierarchies in the Lorentz Model of Hyperbolic Geometry
Jul 08, 2018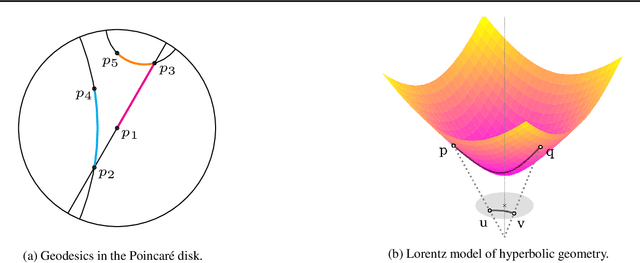
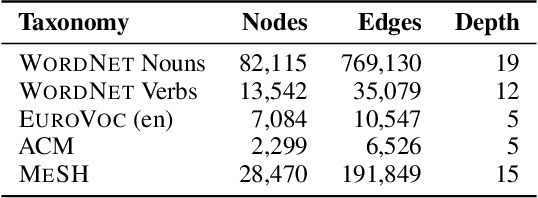
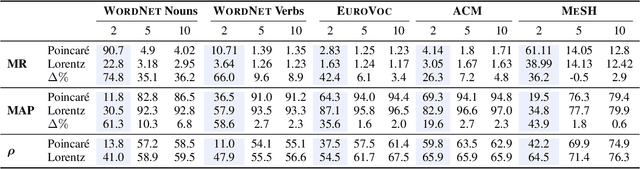
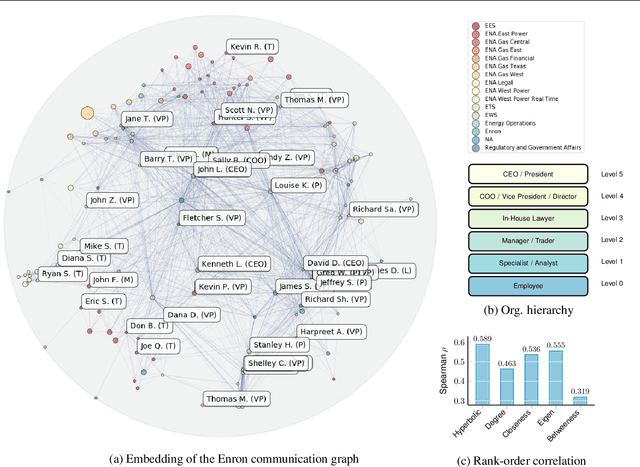
We are concerned with the discovery of hierarchical relationships from large-scale unstructured similarity scores. For this purpose, we study different models of hyperbolic space and find that learning embeddings in the Lorentz model is substantially more efficient than in the Poincar\'e-ball model. We show that the proposed approach allows us to learn high-quality embeddings of large taxonomies which yield improvements over Poincar\'e embeddings, especially in low dimensions. Lastly, we apply our model to discover hierarchies in two real-world datasets: we show that an embedding in hyperbolic space can reveal important aspects of a company's organizational structure as well as reveal historical relationships between language families.
Hearst Patterns Revisited: Automatic Hypernym Detection from Large Text Corpora
Jun 08, 2018

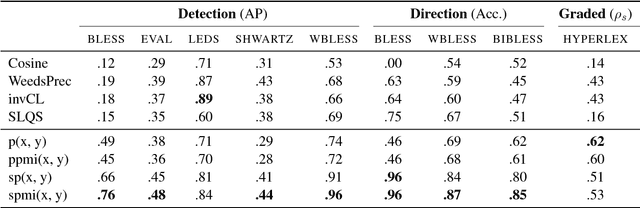
Methods for unsupervised hypernym detection may broadly be categorized according to two paradigms: pattern-based and distributional methods. In this paper, we study the performance of both approaches on several hypernymy tasks and find that simple pattern-based methods consistently outperform distributional methods on common benchmark datasets. Our results show that pattern-based models provide important contextual constraints which are not yet captured in distributional methods.
Learning Visually Grounded Sentence Representations
Jun 04, 2018
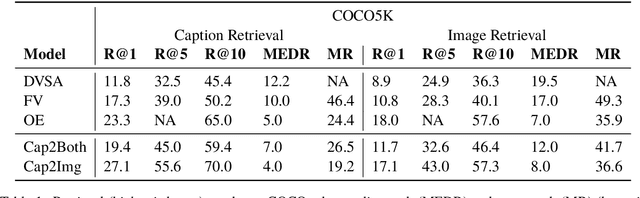
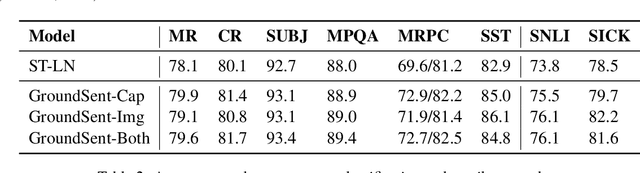
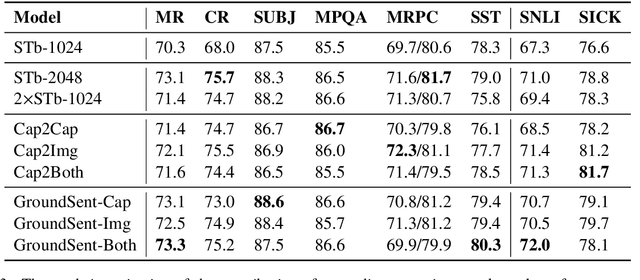
We introduce a variety of models, trained on a supervised image captioning corpus to predict the image features for a given caption, to perform sentence representation grounding. We train a grounded sentence encoder that achieves good performance on COCO caption and image retrieval and subsequently show that this encoder can successfully be transferred to various NLP tasks, with improved performance over text-only models. Lastly, we analyze the contribution of grounding, and show that word embeddings learned by this system outperform non-grounded ones.
Emergent Communication in a Multi-Modal, Multi-Step Referential Game
Apr 16, 2018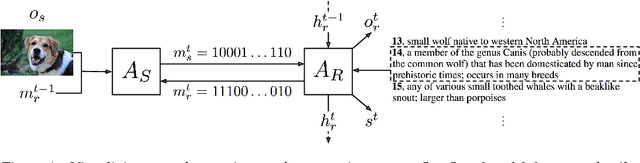

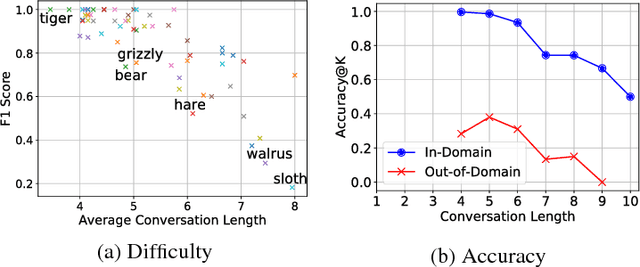
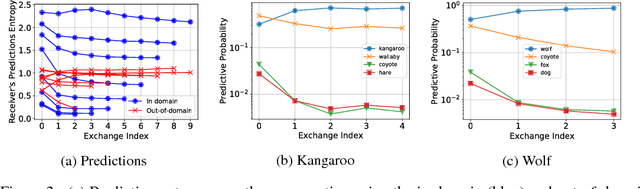
Inspired by previous work on emergent communication in referential games, we propose a novel multi-modal, multi-step referential game, where the sender and receiver have access to distinct modalities of an object, and their information exchange is bidirectional and of arbitrary duration. The multi-modal multi-step setting allows agents to develop an internal communication significantly closer to natural language, in that they share a single set of messages, and that the length of the conversation may vary according to the difficulty of the task. We examine these properties empirically using a dataset consisting of images and textual descriptions of mammals, where the agents are tasked with identifying the correct object. Our experiments indicate that a robust and efficient communication protocol emerges, where gradual information exchange informs better predictions and higher communication bandwidth improves generalization.