 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAir Quality Downscaling with Station-Guided Pseudo-Supervision
Jul 06, 2026Super-resolving coarse atmospheric fields to local PM$_{2.5}$ variations is uniquely challenged by a mismatch in spatial support: while pixels represent regional averages, ground-truth observations are discrete, unaligned samples of a continuous spatial signal. To bridge this gap, we present a station-guided framework for high-resolution PM$_{2.5}$ downscaling over Europe. Taking coarse CAMS atmospheric composition fields alongside heterogeneous side information (i.e., human activity, land cover, elevation, satellite aerosol observations, and wind fields) our framework jointly super-resolves ($\times 40$, $\approx$ 1 km) and bias-corrects CAMS rasters, without relying on temporal sequence modelling. To address the challenge of densely supervising our multi-scale transformer network with sparse in-situ data, we introduce a time-agnostic propagation strategy that utilises spatial Gaussian blending of interpolated OpenAQ observations. Extensive qualitative and station-level evaluations across Europe demonstrate that our model recovers fine-grained spatial structures and effectively mitigates localised CAMS biases.
DermaFlux: Synthetic Skin Lesion Generation with Rectified Flows for Enhanced Image Classification
Mar 17, 2026Despite recent advances in deep generative modeling, skin lesion classification systems remain constrained by the limited availability of large, diverse, and well-annotated clinical datasets, resulting in class imbalance between benign and malignant lesions and consequently reduced generalization performance. We introduce DermaFlux, a rectified flow-based text-to-image generative framework that synthesizes clinically grounded skin lesion images from natural language descriptions of dermatological attributes. Built upon Flux.1, DermaFlux is fine-tuned using parameter-efficient Low-Rank Adaptation (LoRA) on a large curated collection of publicly available clinical image datasets. We construct image-text pairs using synthetic textual captions generated by Llama 3.2, following established dermatological criteria including lesion asymmetry, border irregularity, and color variation. Extensive experiments demonstrate that DermaFlux generates diverse and clinically meaningful dermatology images that improve binary classification performance by up to 6% when augmenting small real-world datasets, and by up to 9% when classifiers are trained on DermaFlux-generated synthetic images rather than diffusion-based synthetic images. Our ImageNet-pretrained ViT fine-tuned with only 2,500 real images and 4,375 DermaFlux-generated samples achieves 78.04% binary classification accuracy and an AUC of 0.859, surpassing the next best dermatology model by 8%.
GroupBERT: Enhanced Transformer Architecture with Efficient Grouped Structures
Jun 10, 2021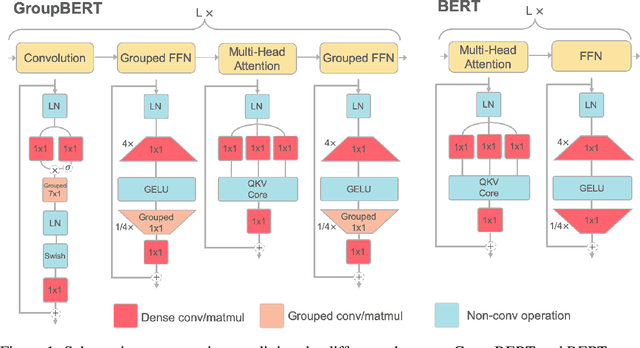
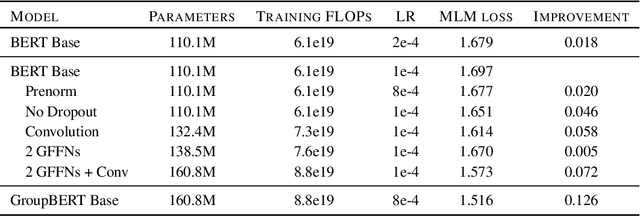

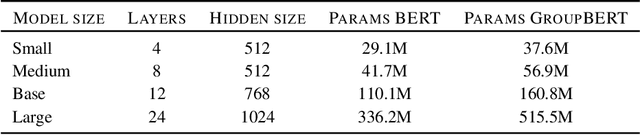
Attention based language models have become a critical component in state-of-the-art natural language processing systems. However, these models have significant computational requirements, due to long training times, dense operations and large parameter count. In this work we demonstrate a set of modifications to the structure of a Transformer layer, producing a more efficient architecture. First, we add a convolutional module to complement the self-attention module, decoupling the learning of local and global interactions. Secondly, we rely on grouped transformations to reduce the computational cost of dense feed-forward layers and convolutions, while preserving the expressivity of the model. We apply the resulting architecture to language representation learning and demonstrate its superior performance compared to BERT models of different scales. We further highlight its improved efficiency, both in terms of floating-point operations (FLOPs) and time-to-train.
CROSSBOW: Scaling Deep Learning with Small Batch Sizes on Multi-GPU Servers
Jan 08, 2019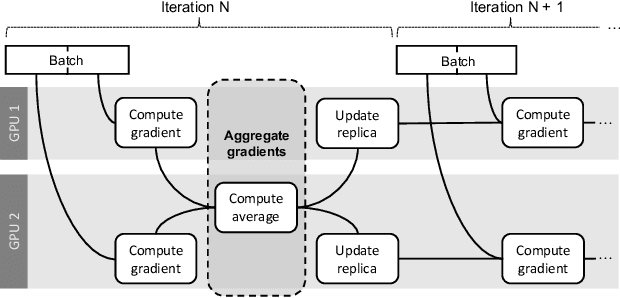
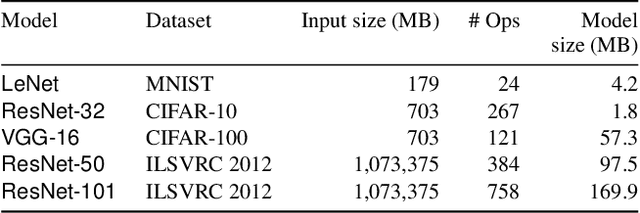

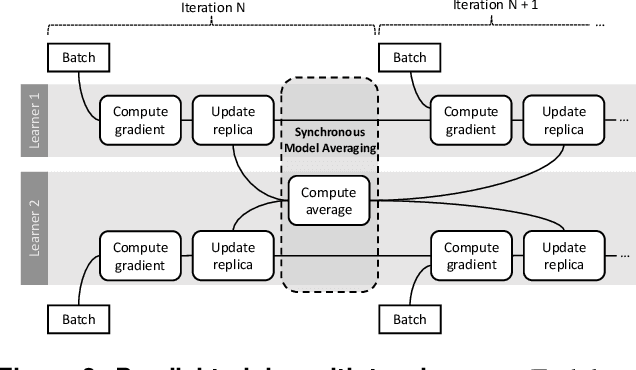
Deep learning models are trained on servers with many GPUs, and training must scale with the number of GPUs. Systems such as TensorFlow and Caffe2 train models with parallel synchronous stochastic gradient descent: they process a batch of training data at a time, partitioned across GPUs, and average the resulting partial gradients to obtain an updated global model. To fully utilise all GPUs, systems must increase the batch size, which hinders statistical efficiency. Users tune hyper-parameters such as the learning rate to compensate for this, which is complex and model-specific. We describe CROSSBOW, a new single-server multi-GPU system for training deep learning models that enables users to freely choose their preferred batch size - however small - while scaling to multiple GPUs. CROSSBOW uses many parallel model replicas and avoids reduced statistical efficiency through a new synchronous training method. We introduce SMA, a synchronous variant of model averaging in which replicas independently explore the solution space with gradient descent, but adjust their search synchronously based on the trajectory of a globally-consistent average model. CROSSBOW achieves high hardware efficiency with small batch sizes by potentially training multiple model replicas per GPU, automatically tuning the number of replicas to maximise throughput. Our experiments show that CROSSBOW improves the training time of deep learning models on an 8-GPU server by 1.3-4x compared to TensorFlow.