 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequence Tutor: Conservative Fine-Tuning of Sequence Generation Models with KL-control
Oct 16, 2017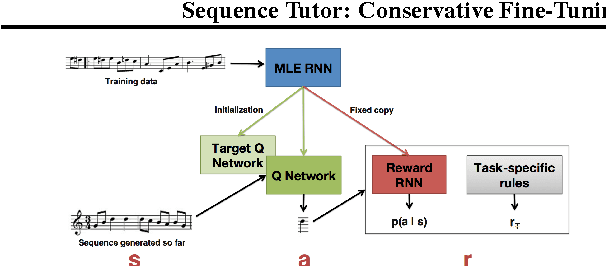
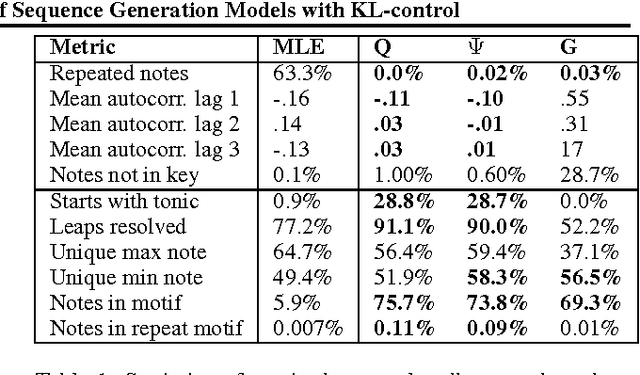
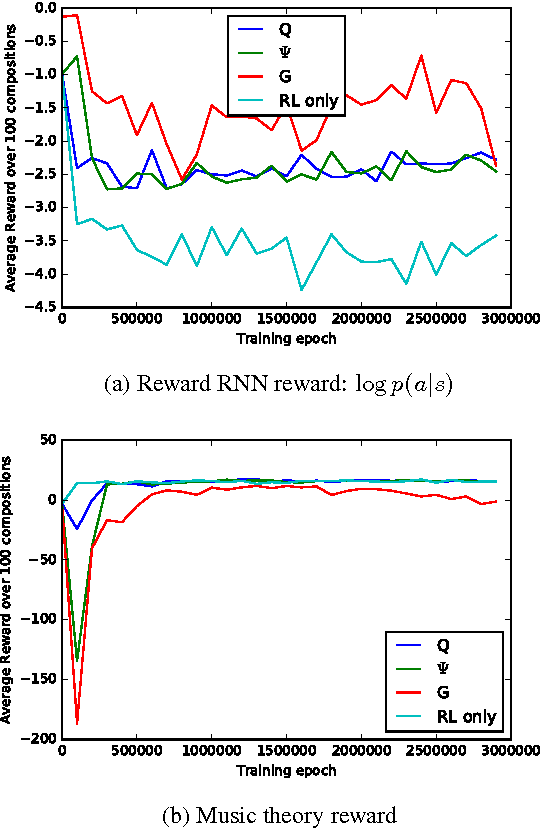
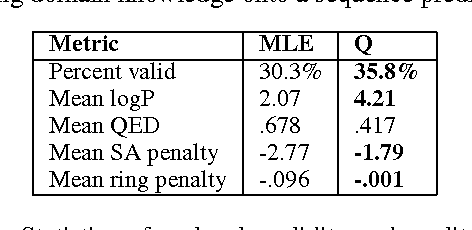
This paper proposes a general method for improving the structure and quality of sequences generated by a recurrent neural network (RNN), while maintaining information originally learned from data, as well as sample diversity. An RNN is first pre-trained on data using maximum likelihood estimation (MLE), and the probability distribution over the next token in the sequence learned by this model is treated as a prior policy. Another RNN is then trained using reinforcement learning (RL) to generate higher-quality outputs that account for domain-specific incentives while retaining proximity to the prior policy of the MLE RNN. To formalize this objective, we derive novel off-policy RL methods for RNNs from KL-control. The effectiveness of the approach is demonstrated on two applications; 1) generating novel musical melodies, and 2) computational molecular generation. For both problems, we show that the proposed method improves the desired properties and structure of the generated sequences, while maintaining information learned from data.
Improving image generative models with human interactions
Sep 29, 2017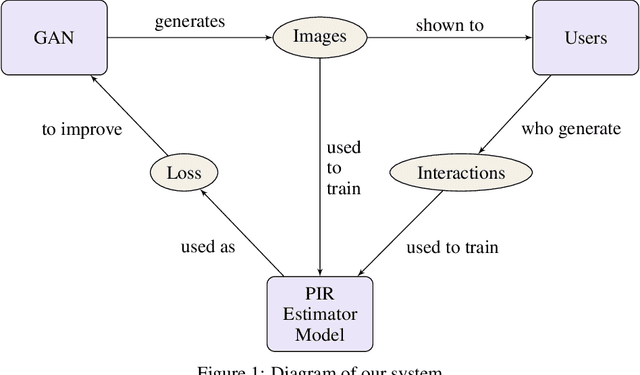
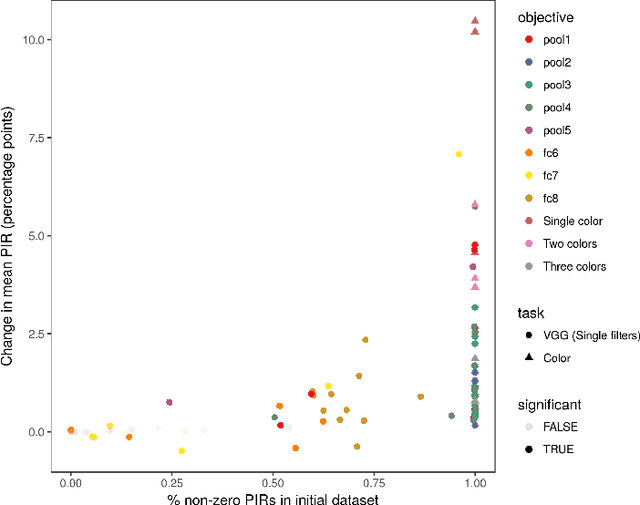
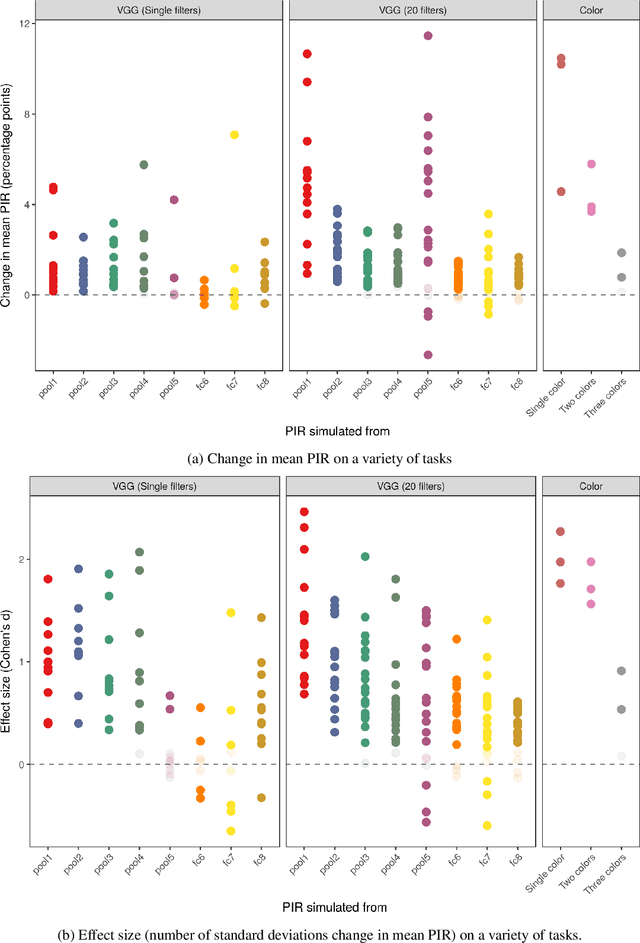

GANs provide a framework for training generative models which mimic a data distribution. However, in many cases we wish to train these generative models to optimize some auxiliary objective function within the data it generates, such as making more aesthetically pleasing images. In some cases, these objective functions are difficult to evaluate, e.g. they may require human interaction. Here, we develop a system for efficiently improving a GAN to target an objective involving human interaction, specifically generating images that increase rates of positive user interactions. To improve the generative model, we build a model of human behavior in the targeted domain from a relatively small set of interactions, and then use this behavioral model as an auxiliary loss function to improve the generative model. We show that this system is successful at improving positive interaction rates, at least on simulated data, and characterize some of the factors that affect its performance.
Online and Linear-Time Attention by Enforcing Monotonic Alignments
Jun 29, 2017
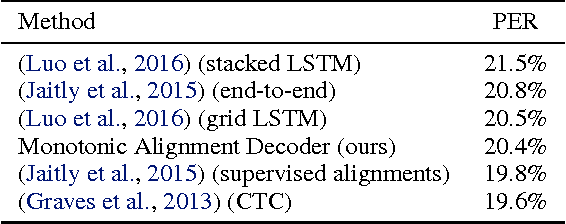
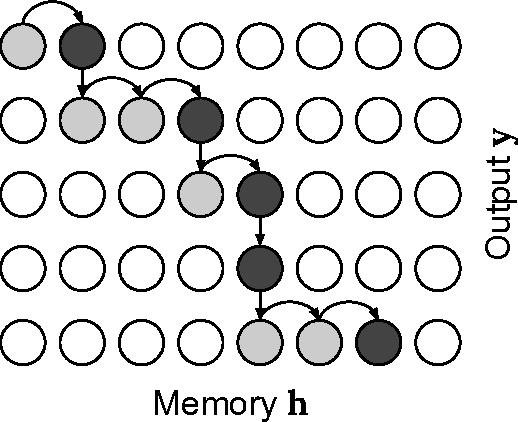
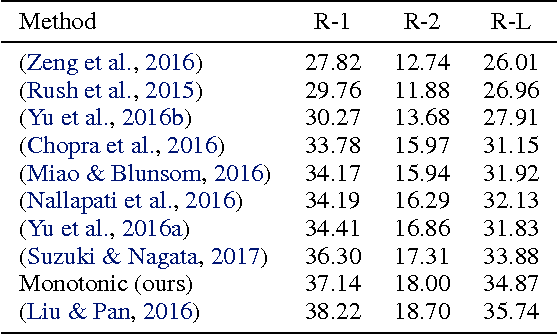
Recurrent neural network models with an attention mechanism have proven to be extremely effective on a wide variety of sequence-to-sequence problems. However, the fact that soft attention mechanisms perform a pass over the entire input sequence when producing each element in the output sequence precludes their use in online settings and results in a quadratic time complexity. Based on the insight that the alignment between input and output sequence elements is monotonic in many problems of interest, we propose an end-to-end differentiable method for learning monotonic alignments which, at test time, enables computing attention online and in linear time. We validate our approach on sentence summarization, machine translation, and online speech recognition problems and achieve results competitive with existing sequence-to-sequence models.
A Neural Representation of Sketch Drawings
May 19, 2017
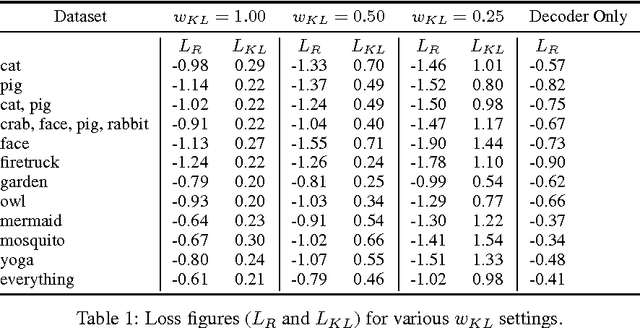
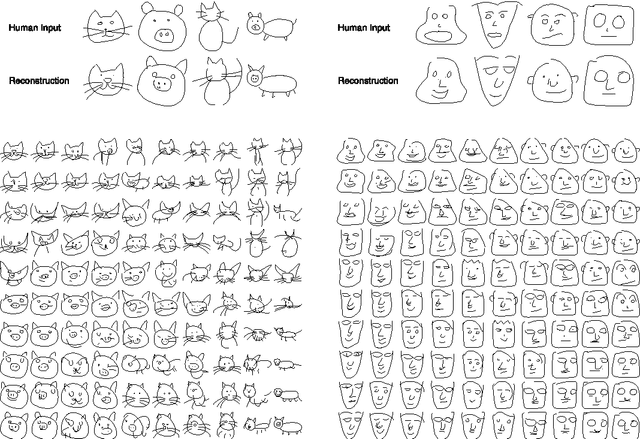
We present sketch-rnn, a recurrent neural network (RNN) able to construct stroke-based drawings of common objects. The model is trained on thousands of crude human-drawn images representing hundreds of classes. We outline a framework for conditional and unconditional sketch generation, and describe new robust training methods for generating coherent sketch drawings in a vector format.
Neural Audio Synthesis of Musical Notes with WaveNet Autoencoders
Apr 05, 2017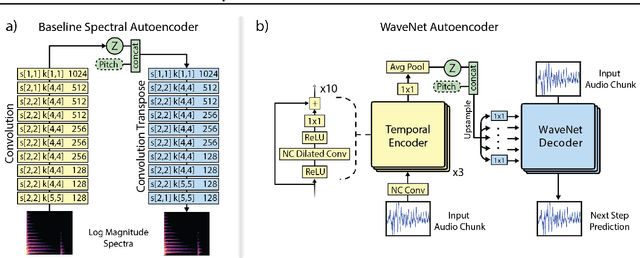
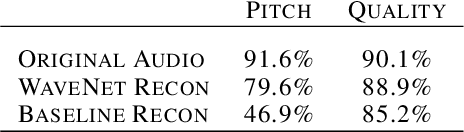

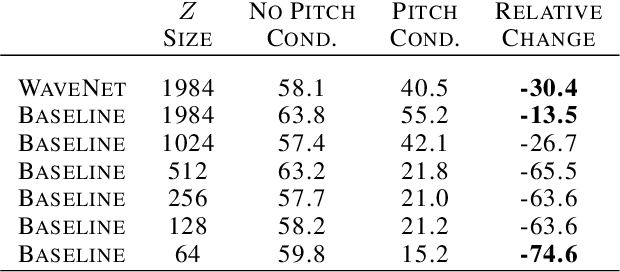
Generative models in vision have seen rapid progress due to algorithmic improvements and the availability of high-quality image datasets. In this paper, we offer contributions in both these areas to enable similar progress in audio modeling. First, we detail a powerful new WaveNet-style autoencoder model that conditions an autoregressive decoder on temporal codes learned from the raw audio waveform. Second, we introduce NSynth, a large-scale and high-quality dataset of musical notes that is an order of magnitude larger than comparable public datasets. Using NSynth, we demonstrate improved qualitative and quantitative performance of the WaveNet autoencoder over a well-tuned spectral autoencoder baseline. Finally, we show that the model learns a manifold of embeddings that allows for morphing between instruments, meaningfully interpolating in timbre to create new types of sounds that are realistic and expressive.